 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDrive: Benchmarking Closed-Loop Cooperative Driving for End-to-End Multi-agent Systems
May 11, 2026Vehicle-to-Everything (V2X) communication has emerged as a promising paradigm for autonomous driving, enabling connected agents to share complementary perception information and negotiate with each other to benefit the final planning. Existing V2X benchmarks, however, fall short in two ways: (i) open-loop evaluations fail to capture the inherently closed-loop nature of driving, leading to evaluation gaps, and (ii) current closed-loop evaluations lack behavioral and interactive diversity to reflect real-world driving. Thus, it is still unclear the extent of benefits of multi-agent systems for closed-loop driving. In this paper, we introduce MDrive, a closed-loop cooperative driving benchmark comprising 225 scenarios grounded in both NHTSA pre-crash typologies and real-world V2X datasets. Our benchmark results demonstrate that multi-agent systems are generally better than single-agent counterparts. However, current multi-agent systems still face two important challenges: (i) perception sharing enhances perceptions, but doesn't always translate to better planning; (ii) negotiation improves planning performance but harms it in complex and dense traffic scenarios. MDrive further provides an open-source toolbox for scenario generation, Real2Sim conversion, and human-in-the-loop simulation. Together, MDrive establishes a reproducible foundation for evaluating and improving the generalization and robustness of cooperative driving systems.
Vista4D: Video Reshooting with 4D Point Clouds
Apr 23, 2026We present Vista4D, a robust and flexible video reshooting framework that grounds the input video and target cameras in a 4D point cloud. Specifically, given an input video, our method re-synthesizes the scene with the same dynamics from a different camera trajectory and viewpoint. Existing video reshooting methods often struggle with depth estimation artifacts of real-world dynamic videos, while also failing to preserve content appearance and failing to maintain precise camera control for challenging new trajectories. We build a 4D-grounded point cloud representation with static pixel segmentation and 4D reconstruction to explicitly preserve seen content and provide rich camera signals, and we train with reconstructed multiview dynamic data for robustness against point cloud artifacts during real-world inference. Our results demonstrate improved 4D consistency, camera control, and visual quality compared to state-of-the-art baselines under a variety of videos and camera paths. Moreover, our method generalizes to real-world applications such as dynamic scene expansion and 4D scene recomposition. See our project page for results, code, and models: https://eyeline-labs.github.io/Vista4D
BridgeSim: Unveiling the OL-CL Gap in End-to-End Autonomous Driving
Apr 12, 2026Open-loop (OL) to closed-loop (CL) gap (OL-CL gap) exists when OL-pretrained policies scoring high in OL evaluations fail to transfer effectively in closed-loop (CL) deployment. In this paper, we unveil the root causes of this systemic failure and propose a practical remedy. Specifically, we demonstrate that OL policies suffer from Observational Domain Shift and Objective Mismatch. We show that while the former is largely recoverable with adaptation techniques, the latter creates a structural inability to model complex reactive behaviors, which forms the primary OL-CL gap. We find that a wide range of OL policies learn a biased Q-value estimator that neglects both the reactive nature of CL simulations and the temporal awareness needed to reduce compounding errors. To this end, we propose a Test-Time Adaptation (TTA) framework that calibrates observational shift, reduces state-action biases, and enforces temporal consistency. Extensive experiments show that TTA effectively mitigates planning biases and yields superior scaling dynamics than its baseline counterparts. Furthermore, our analysis highlights the existence of blind spots in standard OL evaluation protocols that fail to capture the realities of closed-loop deployment.
AURA: Multimodal Shared Autonomy for Real-World Urban Navigation
Apr 02, 2026Long-horizon navigation in complex urban environments relies heavily on continuous human operation, which leads to fatigue, reduced efficiency, and safety concerns. Shared autonomy, where a Vision-Language AI agent and a human operator collaborate on maneuvering the mobile machine, presents a promising solution to address these issues. However, existing shared autonomy methods often require humans and AI to operate within the same action space, leading to high cognitive overhead. We present Assistive Urban Robot Autonomy (AURA), a new multi-modal framework that decomposes urban navigation into high-level human instruction and low-level AI control. AURA incorporates a Spatial-Aware Instruction Encoder to align various human instructions with visual and spatial context. To facilitate training, we construct MM-CoS, a large-scale dataset comprising teleoperation and vision-language descriptions. Experiments in simulation and the real world demonstrate that AURA effectively follows human instructions, reduces manual operation effort, and improves navigation stability, while enabling online adaptation. Moreover, under similar takeover conditions, our shared autonomy framework reduces the frequency of takeovers by more than 44%. Demo video and more detail are provided in the project page.
DiSCo: Diffusion Sequence Copilots for Shared Autonomy
Mar 24, 2026Shared autonomy combines human user and AI copilot actions to control complex systems such as robotic arms. When a task is challenging, requires high dimensional control, or is subject to corruption, shared autonomy can significantly increase task performance by using a trained copilot to effectively correct user actions in a manner consistent with the user's goals. To significantly improve the performance of shared autonomy, we introduce Diffusion Sequence Copilots (DiSCo): a method of shared autonomy with diffusion policy that plans action sequences consistent with past user actions. DiSCo seeds and inpaints the diffusion process with user-provided actions with hyperparameters to balance conformity to expert actions, alignment with user intent, and perceived responsiveness. We demonstrate that DiSCo substantially improves task performance in simulated driving and robotic arm tasks. Project website: https://sites.google.com/view/disco-shared-autonomy/
Learning Sidewalk Autopilot from Multi-Scale Imitation with Corrective Behavior Expansion
Mar 23, 2026Sidewalk micromobility is a promising solution for last-mile transportation, but current learning-based control methods struggle in complex urban environments. Imitation learning (IL) learns policies from human demonstrations, yet its reliance on fixed offline data often leads to compounding errors, limited robustness, and poor generalization. To address these challenges, we propose a framework that advances IL through corrective behavior expansion and multi-scale imitation learning. On the data side, we augment teleoperation datasets with diverse corrective behaviors and sensor augmentations to enable the policy to learn to recover from its own mistakes. On the model side, we introduce a multi-scale IL architecture that captures both short-horizon interactive behaviors and long-horizon goal-directed intentions via horizon-based trajectory clustering and hierarchical supervision. Real-world experiments show that our approach significantly improves robustness and generalization in diverse sidewalk scenarios.
Understanding Real-World Traffic Safety through RoadSafe365 Benchmark
Feb 06, 2026Although recent traffic benchmarks have advanced multimodal data analysis, they generally lack systematic evaluation aligned with official safety standards. To fill this gap, we introduce RoadSafe365, a large-scale vision-language benchmark that supports fine-grained analysis of traffic safety from extensive and diverse real-world video data collections. Unlike prior works that focus primarily on coarse accident identification, RoadSafe365 is independently curated and systematically organized using a hierarchical taxonomy that refines and extends foundational definitions of crash, incident, and violation to bridge official traffic safety standards with data-driven traffic understanding systems. RoadSafe365 provides rich attribute annotations across diverse traffic event types, environmental contexts, and interaction scenarios, yielding 36,196 annotated clips from both dashcam and surveillance cameras. Each clip is paired with multiple-choice question-answer sets, comprising 864K candidate options, 8.4K unique answers, and 36K detailed scene descriptions collectively designed for vision-language understanding and reasoning. We establish strong baselines and observe consistent gains when fine-tuning on RoadSafe365. Cross-domain experiments on both real and synthetic datasets further validate its effectiveness. Designed for large-scale training and standardized evaluation, RoadSafe365 provides a comprehensive benchmark to advance reproducible research in real-world traffic safety analysis.
Counterfactual VLA: Self-Reflective Vision-Language-Action Model with Adaptive Reasoning
Dec 30, 2025Recent reasoning-augmented Vision-Language-Action (VLA) models have improved the interpretability of end-to-end autonomous driving by generating intermediate reasoning traces. Yet these models primarily describe what they perceive and intend to do, rarely questioning whether their planned actions are safe or appropriate. This work introduces Counterfactual VLA (CF-VLA), a self-reflective VLA framework that enables the model to reason about and revise its planned actions before execution. CF-VLA first generates time-segmented meta-actions that summarize driving intent, and then performs counterfactual reasoning conditioned on both the meta-actions and the visual context. This step simulates potential outcomes, identifies unsafe behaviors, and outputs corrected meta-actions that guide the final trajectory generation. To efficiently obtain such self-reflective capabilities, we propose a rollout-filter-label pipeline that mines high-value scenes from a base (non-counterfactual) VLA's rollouts and labels counterfactual reasoning traces for subsequent training rounds. Experiments on large-scale driving datasets show that CF-VLA improves trajectory accuracy by up to 17.6%, enhances safety metrics by 20.5%, and exhibits adaptive thinking: it only enables counterfactual reasoning in challenging scenarios. By transforming reasoning traces from one-shot descriptions to causal self-correction signals, CF-VLA takes a step toward self-reflective autonomous driving agents that learn to think before they act.
Group Diffusion: Enhancing Image Generation by Unlocking Cross-Sample Collaboration
Dec 11, 2025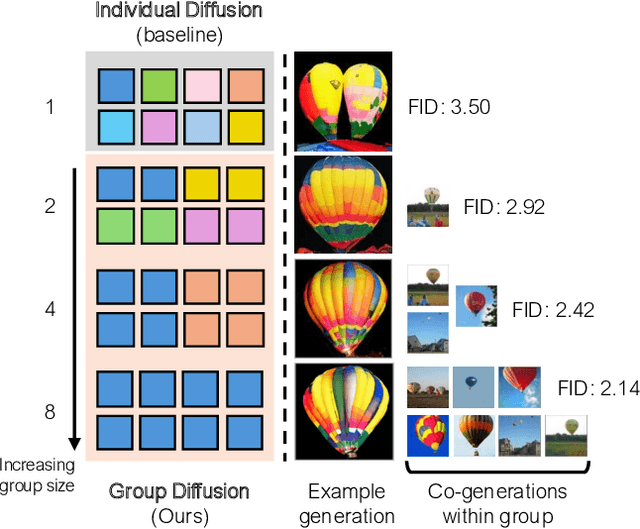
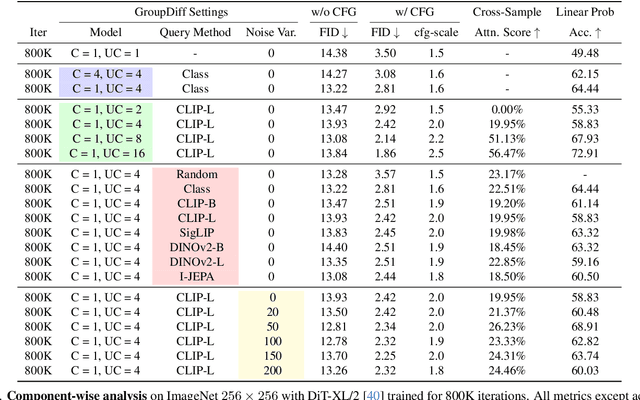

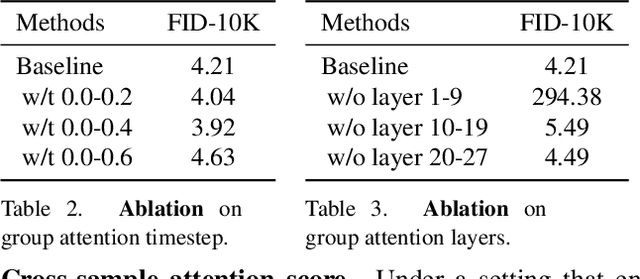
In this work, we explore an untapped signal in diffusion model inference. While all previous methods generate images independently at inference, we instead ask if samples can be generated collaboratively. We propose Group Diffusion, unlocking the attention mechanism to be shared across images, rather than limited to just the patches within an image. This enables images to be jointly denoised at inference time, learning both intra and inter-image correspondence. We observe a clear scaling effect - larger group sizes yield stronger cross-sample attention and better generation quality. Furthermore, we introduce a qualitative measure to capture this behavior and show that its strength closely correlates with FID. Built on standard diffusion transformers, our GroupDiff achieves up to 32.2% FID improvement on ImageNet-256x256. Our work reveals cross-sample inference as an effective, previously unexplored mechanism for generative modeling.
Predictive Preference Learning from Human Interventions
Oct 02, 2025Learning from human involvement aims to incorporate the human subject to monitor and correct agent behavior errors. Although most interactive imitation learning methods focus on correcting the agent's action at the current state, they do not adjust its actions in future states, which may be potentially more hazardous. To address this, we introduce Predictive Preference Learning from Human Interventions (PPL), which leverages the implicit preference signals contained in human interventions to inform predictions of future rollouts. The key idea of PPL is to bootstrap each human intervention into L future time steps, called the preference horizon, with the assumption that the agent follows the same action and the human makes the same intervention in the preference horizon. By applying preference optimization on these future states, expert corrections are propagated into the safety-critical regions where the agent is expected to explore, significantly improving learning efficiency and reducing human demonstrations needed. We evaluate our approach with experiments on both autonomous driving and robotic manipulation benchmarks and demonstrate its efficiency and generality. Our theoretical analysis further shows that selecting an appropriate preference horizon L balances coverage of risky states with label correctness, thereby bounding the algorithmic optimality gap. Demo and code are available at: https://metadriverse.github.io/ppl