 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSV: Towards Understanding the User-generated Short-form Videos
May 20, 2026Several large-scale video datasets have been published these years and have advanced the area of video understanding. However, the newly emerged user-generated short-form videos have rarely been studied. This paper presents USV, the User-generated Short-form Video dataset for high-level semantic video understanding. The dataset contains around 224K videos collected from UGC platforms by label queries without extra manual verification and trimming. Although video understanding has achieved plausible improvement these years, most works focus on instance-level recognition, which is not sufficient for learning the representation of the high-level semantic information of videos. Therefore, we further establish two tasks: topic recognition and video-text retrieval on USV. We propose two unified and effective baseline methods Multi-Modality Fusion Network (MMF-Net) and Video-Text Contrastive Learning (VTCL), to tackle the topic recognition task and video-text retrieval respectively, and carry out comprehensive benchmarks to facilitate future research. Our project page is https://usvdataset.github.io.
Visually-grounded Humanoid Agents
Apr 09, 2026Digital human generation has been studied for decades and supports a wide range of real-world applications. However, most existing systems are passively animated, relying on privileged state or scripted control, which limits scalability to novel environments. We instead ask: how can digital humans actively behave using only visual observations and specified goals in novel scenes? Achieving this would enable populating any 3D environments with digital humans at scale that exhibit spontaneous, natural, goal-directed behaviors. To this end, we introduce Visually-grounded Humanoid Agents, a coupled two-layer (world-agent) paradigm that replicates humans at multiple levels: they look, perceive, reason, and behave like real people in real-world 3D scenes. The World Layer reconstructs semantically rich 3D Gaussian scenes from real-world videos via an occlusion-aware pipeline and accommodates animatable Gaussian-based human avatars. The Agent Layer transforms these avatars into autonomous humanoid agents, equipping them with first-person RGB-D perception and enabling them to perform accurate, embodied planning with spatial awareness and iterative reasoning, which is then executed at the low level as full-body actions to drive their behaviors in the scene. We further introduce a benchmark to evaluate humanoid-scene interaction in diverse reconstructed environments. Experiments show our agents achieve robust autonomous behavior, yielding higher task success rates and fewer collisions than ablations and state-of-the-art planning methods. This work enables active digital human population and advances human-centric embodied AI. Data, code, and models will be open-sourced.
AURA: Multimodal Shared Autonomy for Real-World Urban Navigation
Apr 02, 2026Long-horizon navigation in complex urban environments relies heavily on continuous human operation, which leads to fatigue, reduced efficiency, and safety concerns. Shared autonomy, where a Vision-Language AI agent and a human operator collaborate on maneuvering the mobile machine, presents a promising solution to address these issues. However, existing shared autonomy methods often require humans and AI to operate within the same action space, leading to high cognitive overhead. We present Assistive Urban Robot Autonomy (AURA), a new multi-modal framework that decomposes urban navigation into high-level human instruction and low-level AI control. AURA incorporates a Spatial-Aware Instruction Encoder to align various human instructions with visual and spatial context. To facilitate training, we construct MM-CoS, a large-scale dataset comprising teleoperation and vision-language descriptions. Experiments in simulation and the real world demonstrate that AURA effectively follows human instructions, reduces manual operation effort, and improves navigation stability, while enabling online adaptation. Moreover, under similar takeover conditions, our shared autonomy framework reduces the frequency of takeovers by more than 44%. Demo video and more detail are provided in the project page.
Learning Sidewalk Autopilot from Multi-Scale Imitation with Corrective Behavior Expansion
Mar 23, 2026Sidewalk micromobility is a promising solution for last-mile transportation, but current learning-based control methods struggle in complex urban environments. Imitation learning (IL) learns policies from human demonstrations, yet its reliance on fixed offline data often leads to compounding errors, limited robustness, and poor generalization. To address these challenges, we propose a framework that advances IL through corrective behavior expansion and multi-scale imitation learning. On the data side, we augment teleoperation datasets with diverse corrective behaviors and sensor augmentations to enable the policy to learn to recover from its own mistakes. On the model side, we introduce a multi-scale IL architecture that captures both short-horizon interactive behaviors and long-horizon goal-directed intentions via horizon-based trajectory clustering and hierarchical supervision. Real-world experiments show that our approach significantly improves robustness and generalization in diverse sidewalk scenarios.
From Seeing to Experiencing: Scaling Navigation Foundation Models with Reinforcement Learning
Jul 29, 2025Navigation foundation models trained on massive webscale data enable agents to generalize across diverse environments and embodiments. However, these models trained solely on offline data, often lack the capacity to reason about the consequences of their actions or adapt through counterfactual understanding. They thus face significant limitations in the real-world urban navigation where interactive and safe behaviors, such as avoiding obstacles and moving pedestrians, are critical. To tackle these challenges, we introduce the Seeing-to-Experiencing framework to scale the capability of navigation foundation models with reinforcement learning. S2E combines the strengths of pre-training on videos and post-training through RL. It maintains the generalizability acquired from large-scale real-world videos while enhancing its interactivity through RL in simulation environments. Specifically, we introduce two innovations: an Anchor-Guided Distribution Matching strategy, which stabilizes learning and models diverse motion patterns through anchor-based supervision; and a Residual-Attention Module, which obtains reactive behaviors from simulation environments without erasing the model's pretrained knowledge. Moreover, we establish a comprehensive end-to-end evaluation benchmark, NavBench-GS, built on photorealistic 3DGS reconstructions of real-world scenes that incorporate physical interactions. It can systematically assess the generalizability and safety of navigation foundation models. Extensive experiments show that S2E mitigates the diminishing returns often seen when scaling with offline data alone. We perform a thorough analysis of the benefits of Reinforcement Learning compared to Supervised Fine-Tuning in the context of post-training for robot learning. Our findings emphasize the crucial role of integrating interactive online experiences to effectively scale foundation models in Robotics.
Towards Autonomous Micromobility through Scalable Urban Simulation
May 01, 2025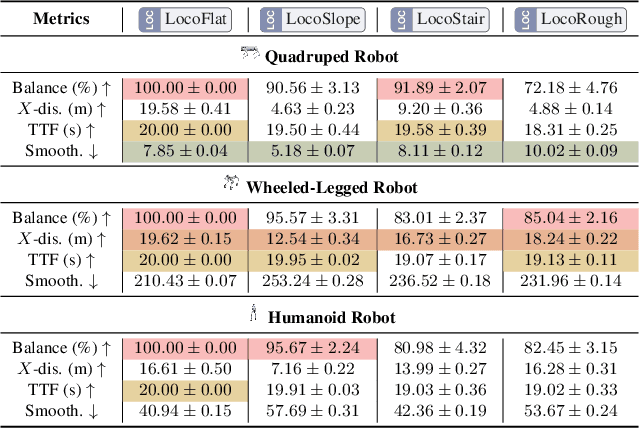

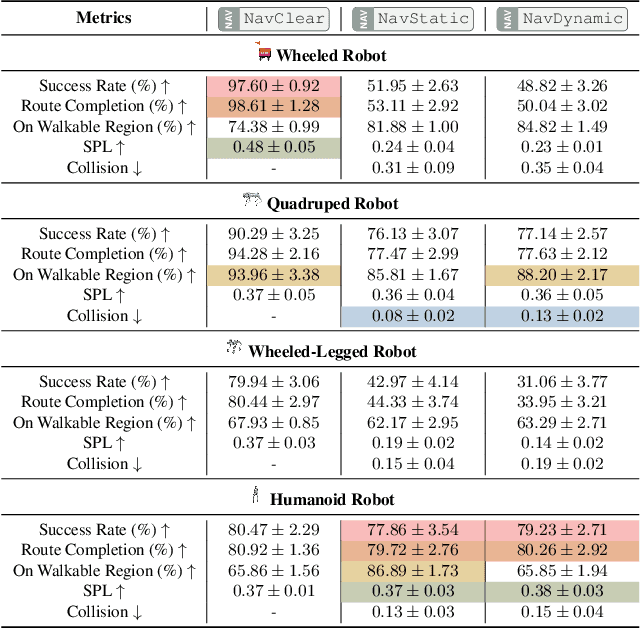
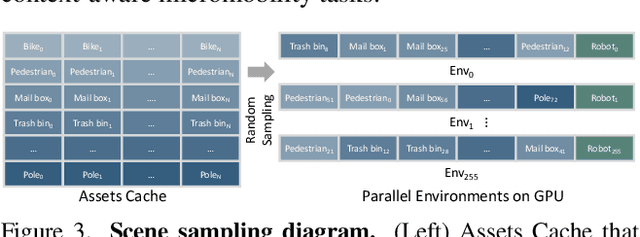
Micromobility, which utilizes lightweight mobile machines moving in urban public spaces, such as delivery robots and mobility scooters, emerges as a promising alternative to vehicular mobility. Current micromobility depends mostly on human manual operation (in-person or remote control), which raises safety and efficiency concerns when navigating busy urban environments full of unpredictable obstacles and pedestrians. Assisting humans with AI agents in maneuvering micromobility devices presents a viable solution for enhancing safety and efficiency. In this work, we present a scalable urban simulation solution to advance autonomous micromobility. First, we build URBAN-SIM - a high-performance robot learning platform for large-scale training of embodied agents in interactive urban scenes. URBAN-SIM contains three critical modules: Hierarchical Urban Generation pipeline, Interactive Dynamics Generation strategy, and Asynchronous Scene Sampling scheme, to improve the diversity, realism, and efficiency of robot learning in simulation. Then, we propose URBAN-BENCH - a suite of essential tasks and benchmarks to gauge various capabilities of the AI agents in achieving autonomous micromobility. URBAN-BENCH includes eight tasks based on three core skills of the agents: Urban Locomotion, Urban Navigation, and Urban Traverse. We evaluate four robots with heterogeneous embodiments, such as the wheeled and legged robots, across these tasks. Experiments on diverse terrains and urban structures reveal each robot's strengths and limitations.
MEAT: Multiview Diffusion Model for Human Generation on Megapixels with Mesh Attention
Mar 11, 2025



Multiview diffusion models have shown considerable success in image-to-3D generation for general objects. However, when applied to human data, existing methods have yet to deliver promising results, largely due to the challenges of scaling multiview attention to higher resolutions. In this paper, we explore human multiview diffusion models at the megapixel level and introduce a solution called mesh attention to enable training at 1024x1024 resolution. Using a clothed human mesh as a central coarse geometric representation, the proposed mesh attention leverages rasterization and projection to establish direct cross-view coordinate correspondences. This approach significantly reduces the complexity of multiview attention while maintaining cross-view consistency. Building on this foundation, we devise a mesh attention block and combine it with keypoint conditioning to create our human-specific multiview diffusion model, MEAT. In addition, we present valuable insights into applying multiview human motion videos for diffusion training, addressing the longstanding issue of data scarcity. Extensive experiments show that MEAT effectively generates dense, consistent multiview human images at the megapixel level, outperforming existing multiview diffusion methods.
Vid2Sim: Realistic and Interactive Simulation from Video for Urban Navigation
Jan 14, 2025Sim-to-real gap has long posed a significant challenge for robot learning in simulation, preventing the deployment of learned models in the real world. Previous work has primarily focused on domain randomization and system identification to mitigate this gap. However, these methods are often limited by the inherent constraints of the simulation and graphics engines. In this work, we propose Vid2Sim, a novel framework that effectively bridges the sim2real gap through a scalable and cost-efficient real2sim pipeline for neural 3D scene reconstruction and simulation. Given a monocular video as input, Vid2Sim can generate photorealistic and physically interactable 3D simulation environments to enable the reinforcement learning of visual navigation agents in complex urban environments. Extensive experiments demonstrate that Vid2Sim significantly improves the performance of urban navigation in the digital twins and real world by 31.2% and 68.3% in success rate compared with agents trained with prior simulation methods.
Joint Optimization for 4D Human-Scene Reconstruction in the Wild
Jan 04, 2025



Reconstructing human motion and its surrounding environment is crucial for understanding human-scene interaction and predicting human movements in the scene. While much progress has been made in capturing human-scene interaction in constrained environments, those prior methods can hardly reconstruct the natural and diverse human motion and scene context from web videos. In this work, we propose JOSH, a novel optimization-based method for 4D human-scene reconstruction in the wild from monocular videos. JOSH uses techniques in both dense scene reconstruction and human mesh recovery as initialization, and then it leverages the human-scene contact constraints to jointly optimize the scene, the camera poses, and the human motion. Experiment results show JOSH achieves better results on both global human motion estimation and dense scene reconstruction by joint optimization of scene geometry and human motion. We further design a more efficient model, JOSH3R, and directly train it with pseudo-labels from web videos. JOSH3R outperforms other optimization-free methods by only training with labels predicted from JOSH, further demonstrating its accuracy and generalization ability.
Learning to Generate Diverse Pedestrian Movements from Web Videos with Noisy Labels
Oct 10, 2024



Understanding and modeling pedestrian movements in the real world is crucial for applications like motion forecasting and scene simulation. Many factors influence pedestrian movements, such as scene context, individual characteristics, and goals, which are often ignored by the existing human generation methods. Web videos contain natural pedestrian behavior and rich motion context, but annotating them with pre-trained predictors leads to noisy labels. In this work, we propose learning diverse pedestrian movements from web videos. We first curate a large-scale dataset called CityWalkers that captures diverse real-world pedestrian movements in urban scenes. Then, based on CityWalkers, we propose a generative model called PedGen for diverse pedestrian movement generation. PedGen introduces automatic label filtering to remove the low-quality labels and a mask embedding to train with partial labels. It also contains a novel context encoder that lifts the 2D scene context to 3D and can incorporate various context factors in generating realistic pedestrian movements in urban scenes. Experiments show that PedGen outperforms existing baseline methods for pedestrian movement generation by learning from noisy labels and incorporating the context factors. In addition, PedGen achieves zero-shot generalization in both real-world and simulated environments. The code, model, and data will be made publicly available at https://genforce.github.io/PedGen/ .