 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridgeSim: Unveiling the OL-CL Gap in End-to-End Autonomous Driving
Apr 12, 2026Open-loop (OL) to closed-loop (CL) gap (OL-CL gap) exists when OL-pretrained policies scoring high in OL evaluations fail to transfer effectively in closed-loop (CL) deployment. In this paper, we unveil the root causes of this systemic failure and propose a practical remedy. Specifically, we demonstrate that OL policies suffer from Observational Domain Shift and Objective Mismatch. We show that while the former is largely recoverable with adaptation techniques, the latter creates a structural inability to model complex reactive behaviors, which forms the primary OL-CL gap. We find that a wide range of OL policies learn a biased Q-value estimator that neglects both the reactive nature of CL simulations and the temporal awareness needed to reduce compounding errors. To this end, we propose a Test-Time Adaptation (TTA) framework that calibrates observational shift, reduces state-action biases, and enforces temporal consistency. Extensive experiments show that TTA effectively mitigates planning biases and yields superior scaling dynamics than its baseline counterparts. Furthermore, our analysis highlights the existence of blind spots in standard OL evaluation protocols that fail to capture the realities of closed-loop deployment.
AURA: Multimodal Shared Autonomy for Real-World Urban Navigation
Apr 02, 2026Long-horizon navigation in complex urban environments relies heavily on continuous human operation, which leads to fatigue, reduced efficiency, and safety concerns. Shared autonomy, where a Vision-Language AI agent and a human operator collaborate on maneuvering the mobile machine, presents a promising solution to address these issues. However, existing shared autonomy methods often require humans and AI to operate within the same action space, leading to high cognitive overhead. We present Assistive Urban Robot Autonomy (AURA), a new multi-modal framework that decomposes urban navigation into high-level human instruction and low-level AI control. AURA incorporates a Spatial-Aware Instruction Encoder to align various human instructions with visual and spatial context. To facilitate training, we construct MM-CoS, a large-scale dataset comprising teleoperation and vision-language descriptions. Experiments in simulation and the real world demonstrate that AURA effectively follows human instructions, reduces manual operation effort, and improves navigation stability, while enabling online adaptation. Moreover, under similar takeover conditions, our shared autonomy framework reduces the frequency of takeovers by more than 44%. Demo video and more detail are provided in the project page.
Learning Sidewalk Autopilot from Multi-Scale Imitation with Corrective Behavior Expansion
Mar 23, 2026Sidewalk micromobility is a promising solution for last-mile transportation, but current learning-based control methods struggle in complex urban environments. Imitation learning (IL) learns policies from human demonstrations, yet its reliance on fixed offline data often leads to compounding errors, limited robustness, and poor generalization. To address these challenges, we propose a framework that advances IL through corrective behavior expansion and multi-scale imitation learning. On the data side, we augment teleoperation datasets with diverse corrective behaviors and sensor augmentations to enable the policy to learn to recover from its own mistakes. On the model side, we introduce a multi-scale IL architecture that captures both short-horizon interactive behaviors and long-horizon goal-directed intentions via horizon-based trajectory clustering and hierarchical supervision. Real-world experiments show that our approach significantly improves robustness and generalization in diverse sidewalk scenarios.
From Seeing to Experiencing: Scaling Navigation Foundation Models with Reinforcement Learning
Jul 29, 2025Navigation foundation models trained on massive webscale data enable agents to generalize across diverse environments and embodiments. However, these models trained solely on offline data, often lack the capacity to reason about the consequences of their actions or adapt through counterfactual understanding. They thus face significant limitations in the real-world urban navigation where interactive and safe behaviors, such as avoiding obstacles and moving pedestrians, are critical. To tackle these challenges, we introduce the Seeing-to-Experiencing framework to scale the capability of navigation foundation models with reinforcement learning. S2E combines the strengths of pre-training on videos and post-training through RL. It maintains the generalizability acquired from large-scale real-world videos while enhancing its interactivity through RL in simulation environments. Specifically, we introduce two innovations: an Anchor-Guided Distribution Matching strategy, which stabilizes learning and models diverse motion patterns through anchor-based supervision; and a Residual-Attention Module, which obtains reactive behaviors from simulation environments without erasing the model's pretrained knowledge. Moreover, we establish a comprehensive end-to-end evaluation benchmark, NavBench-GS, built on photorealistic 3DGS reconstructions of real-world scenes that incorporate physical interactions. It can systematically assess the generalizability and safety of navigation foundation models. Extensive experiments show that S2E mitigates the diminishing returns often seen when scaling with offline data alone. We perform a thorough analysis of the benefits of Reinforcement Learning compared to Supervised Fine-Tuning in the context of post-training for robot learning. Our findings emphasize the crucial role of integrating interactive online experiences to effectively scale foundation models in Robotics.
Dreamland: Controllable World Creation with Simulator and Generative Models
Jun 09, 2025Large-scale video generative models can synthesize diverse and realistic visual content for dynamic world creation, but they often lack element-wise controllability, hindering their use in editing scenes and training embodied AI agents. We propose Dreamland, a hybrid world generation framework combining the granular control of a physics-based simulator and the photorealistic content output of large-scale pretrained generative models. In particular, we design a layered world abstraction that encodes both pixel-level and object-level semantics and geometry as an intermediate representation to bridge the simulator and the generative model. This approach enhances controllability, minimizes adaptation cost through early alignment with real-world distributions, and supports off-the-shelf use of existing and future pretrained generative models. We further construct a D3Sim dataset to facilitate the training and evaluation of hybrid generation pipelines. Experiments demonstrate that Dreamland outperforms existing baselines with 50.8% improved image quality, 17.9% stronger controllability, and has great potential to enhance embodied agent training. Code and data will be made available.
Towards Autonomous Micromobility through Scalable Urban Simulation
May 01, 2025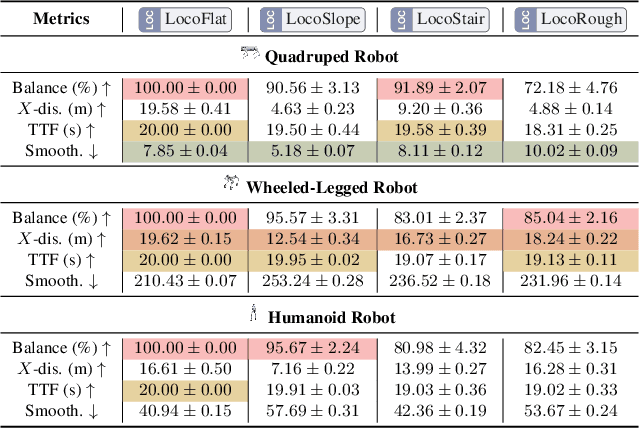

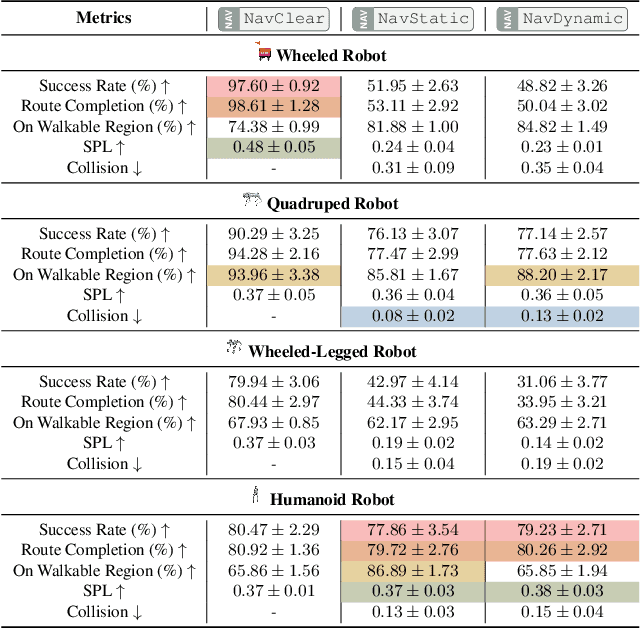
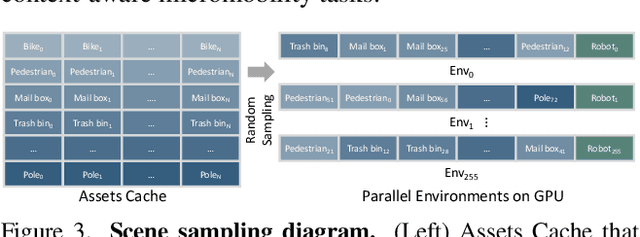
Micromobility, which utilizes lightweight mobile machines moving in urban public spaces, such as delivery robots and mobility scooters, emerges as a promising alternative to vehicular mobility. Current micromobility depends mostly on human manual operation (in-person or remote control), which raises safety and efficiency concerns when navigating busy urban environments full of unpredictable obstacles and pedestrians. Assisting humans with AI agents in maneuvering micromobility devices presents a viable solution for enhancing safety and efficiency. In this work, we present a scalable urban simulation solution to advance autonomous micromobility. First, we build URBAN-SIM - a high-performance robot learning platform for large-scale training of embodied agents in interactive urban scenes. URBAN-SIM contains three critical modules: Hierarchical Urban Generation pipeline, Interactive Dynamics Generation strategy, and Asynchronous Scene Sampling scheme, to improve the diversity, realism, and efficiency of robot learning in simulation. Then, we propose URBAN-BENCH - a suite of essential tasks and benchmarks to gauge various capabilities of the AI agents in achieving autonomous micromobility. URBAN-BENCH includes eight tasks based on three core skills of the agents: Urban Locomotion, Urban Navigation, and Urban Traverse. We evaluate four robots with heterogeneous embodiments, such as the wheeled and legged robots, across these tasks. Experiments on diverse terrains and urban structures reveal each robot's strengths and limitations.
MetaUrban: A Simulation Platform for Embodied AI in Urban Spaces
Jul 11, 2024



Public urban spaces like streetscapes and plazas serve residents and accommodate social life in all its vibrant variations. Recent advances in Robotics and Embodied AI make public urban spaces no longer exclusive to humans. Food delivery bots and electric wheelchairs have started sharing sidewalks with pedestrians, while diverse robot dogs and humanoids have recently emerged in the street. Ensuring the generalizability and safety of these forthcoming mobile machines is crucial when navigating through the bustling streets in urban spaces. In this work, we present MetaUrban, a compositional simulation platform for Embodied AI research in urban spaces. MetaUrban can construct an infinite number of interactive urban scenes from compositional elements, covering a vast array of ground plans, object placements, pedestrians, vulnerable road users, and other mobile agents' appearances and dynamics. We design point navigation and social navigation tasks as the pilot study using MetaUrban for embodied AI research and establish various baselines of Reinforcement Learning and Imitation Learning. Experiments demonstrate that the compositional nature of the simulated environments can substantially improve the generalizability and safety of the trained mobile agents. MetaUrban will be made publicly available to provide more research opportunities and foster safe and trustworthy embodied AI in urban spaces.
Few-Shot Scenario Testing for Autonomous Vehicles Based on Neighborhood Coverage and Similarity
Feb 02, 2024Testing and evaluating the safety performance of autonomous vehicles (AVs) is essential before the large-scale deployment. Practically, the acceptable cost of testing specific AV model can be restricted within an extremely small limit because of testing cost or time. With existing testing methods, the limitations imposed by strictly restricted testing numbers often result in significant uncertainties or challenges in quantifying testing results. In this paper, we formulate this problem for the first time the "few-shot testing" (FST) problem and propose a systematic FST framework to address this challenge. To alleviate the considerable uncertainty inherent in a small testing scenario set and optimize scenario utilization, we frame the FST problem as an optimization problem and search for a small scenario set based on neighborhood coverage and similarity. By leveraging the prior information on surrogate models (SMs), we dynamically adjust the testing scenario set and the contribution of each scenario to the testing result under the guidance of better generalization ability on AVs. With certain hypotheses on SMs, a theoretical upper bound of testing error is established to verify the sufficiency of testing accuracy within given limited number of tests. The experiments of the cut-in scenario using FST method demonstrate a notable reduction in testing error and variance compared to conventional testing methods, especially for situations with a strict limitation on the number of scenarios.
OrthoPlanes: A Novel Representation for Better 3D-Awareness of GANs
Sep 27, 2023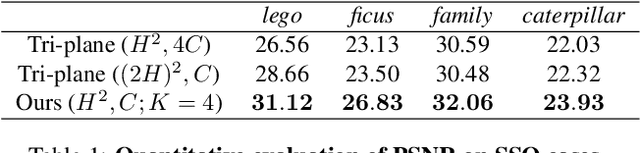
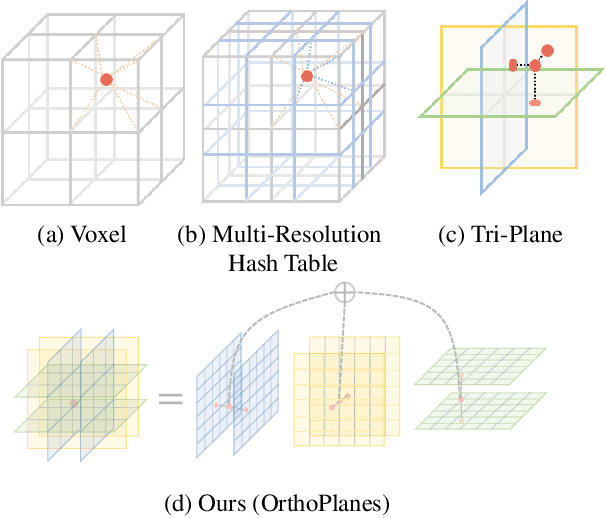
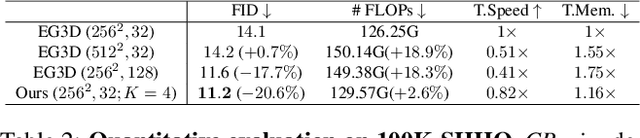

We present a new method for generating realistic and view-consistent images with fine geometry from 2D image collections. Our method proposes a hybrid explicit-implicit representation called \textbf{OrthoPlanes}, which encodes fine-grained 3D information in feature maps that can be efficiently generated by modifying 2D StyleGANs. Compared to previous representations, our method has better scalability and expressiveness with clear and explicit information. As a result, our method can handle more challenging view-angles and synthesize articulated objects with high spatial degree of freedom. Experiments demonstrate that our method achieves state-of-the-art results on FFHQ and SHHQ datasets, both quantitatively and qualitatively. Project page: \url{https://orthoplanes.github.io/}.
DNA-Rendering: A Diverse Neural Actor Repository for High-Fidelity Human-centric Rendering
Jul 19, 2023
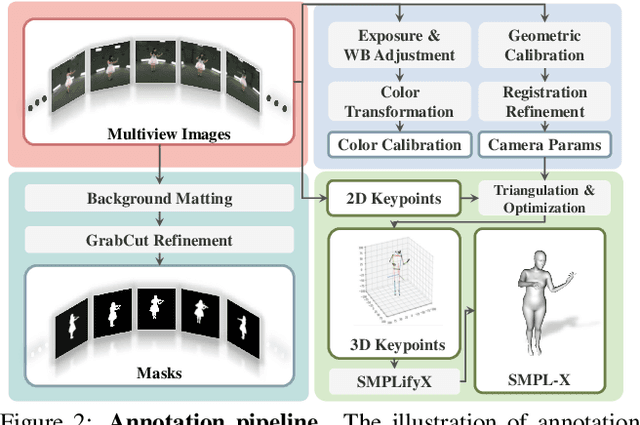
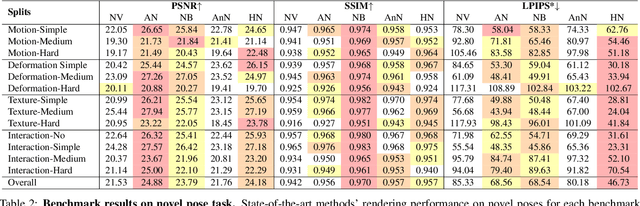

Realistic human-centric rendering plays a key role in both computer vision and computer graphics. Rapid progress has been made in the algorithm aspect over the years, yet existing human-centric rendering datasets and benchmarks are rather impoverished in terms of diversity, which are crucial for rendering effect. Researchers are usually constrained to explore and evaluate a small set of rendering problems on current datasets, while real-world applications require methods to be robust across different scenarios. In this work, we present DNA-Rendering, a large-scale, high-fidelity repository of human performance data for neural actor rendering. DNA-Rendering presents several alluring attributes. First, our dataset contains over 1500 human subjects, 5000 motion sequences, and 67.5M frames' data volume. Second, we provide rich assets for each subject -- 2D/3D human body keypoints, foreground masks, SMPLX models, cloth/accessory materials, multi-view images, and videos. These assets boost the current method's accuracy on downstream rendering tasks. Third, we construct a professional multi-view system to capture data, which contains 60 synchronous cameras with max 4096 x 3000 resolution, 15 fps speed, and stern camera calibration steps, ensuring high-quality resources for task training and evaluation. Along with the dataset, we provide a large-scale and quantitative benchmark in full-scale, with multiple tasks to evaluate the existing progress of novel view synthesis, novel pose animation synthesis, and novel identity rendering methods. In this manuscript, we describe our DNA-Rendering effort as a revealing of new observations, challenges, and future directions to human-centric rendering. The dataset, code, and benchmarks will be publicly available at https://dna-rendering.github.io/