 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlow Brain, Fast Planner: Latency-Resilient VLM-Augmented Urban Navigation
Jun 18, 2026Learning-based planners for sidewalk navigation can generate diverse candidate trajectories in real time, yet their scoring functions often fail to select the best trajectory in challenging situations, outputting trajectories that make the mobile robot drive onto grass, toward pedestrians, or in the wrong direction, even when better candidates exist in the same set. We call this the trajectory scoring gap: in real-world sidewalk navigation, the gap between an anchor-based planner's top choice and the best possible candidate is substantial, likely due to limited high-level scene understanding capability of the planner. Rather than replacing the planner with an end-to-end Vision-Language-Action model, we propose a VLM-Planner interface that uses a VLM to select a candidate index from the planner's proposal set and then fuse it with the planner's initial output. However, VLMs take 1--3s per query and so cannot directly drive a 5--20Hz control loop. We contribute a training-free, latency-resilient trajectory-level fusion layer that turns a stale VLM selection into real-time planner scoring via geometric similarity with exponential decay. On $\sim$2,000 challenging real-world scenarios (e.g., junctions, pedestrian encounters), VLM selection achieves 30% ADE reduction versus the planner's best selection, while the planner remains competitive in routine situations. In simulation, Score Fusion maintains >80% success rate with delays up to 5s. We demonstrate the full system on a mobile robot navigating challenging campus sidewalks with varied network latency.
Grounded World Model for Semantically Generalizable Planning
Apr 13, 2026In Model Predictive Control (MPC), world models predict the future outcomes of various action proposals, which are then scored to guide the selection of the optimal action. For visuomotor MPC, the score function is a distance metric between a predicted image and a goal image, measured in the latent space of a pretrained vision encoder like DINO and JEPA. However, it is challenging to obtain the goal image in advance of the task execution, particularly in new environments. Additionally, conveying the goal through an image offers limited interactivity compared with natural language. In this work, we propose to learn a Grounded World Model (GWM) in a vision-language-aligned latent space. As a result, each proposed action is scored based on how close its future outcome is to the task instruction, reflected by the similarity of embeddings. This approach transforms the visuomotor MPC to a VLA that surpasses VLM-based VLAs in semantic generalization. On the proposed WISER benchmark, GWM-MPC achieves a 87% success rate on the test set comprising 288 tasks that feature unseen visual signals and referring expressions, yet remain solvable with motions demonstrated during training. In contrast, traditional VLAs achieve an average success rate of 22%, even though they overfit the training set with a 90% success rate.
RAP: 3D Rasterization Augmented End-to-End Planning
Oct 05, 2025Imitation learning for end-to-end driving trains policies only on expert demonstrations. Once deployed in a closed loop, such policies lack recovery data: small mistakes cannot be corrected and quickly compound into failures. A promising direction is to generate alternative viewpoints and trajectories beyond the logged path. Prior work explores photorealistic digital twins via neural rendering or game engines, but these methods are prohibitively slow and costly, and thus mainly used for evaluation. In this work, we argue that photorealism is unnecessary for training end-to-end planners. What matters is semantic fidelity and scalability: driving depends on geometry and dynamics, not textures or lighting. Motivated by this, we propose 3D Rasterization, which replaces costly rendering with lightweight rasterization of annotated primitives, enabling augmentations such as counterfactual recovery maneuvers and cross-agent view synthesis. To transfer these synthetic views effectively to real-world deployment, we introduce a Raster-to-Real feature-space alignment that bridges the sim-to-real gap. Together, these components form Rasterization Augmented Planning (RAP), a scalable data augmentation pipeline for planning. RAP achieves state-of-the-art closed-loop robustness and long-tail generalization, ranking first on four major benchmarks: NAVSIM v1/v2, Waymo Open Dataset Vision-based E2E Driving, and Bench2Drive. Our results show that lightweight rasterization with feature alignment suffices to scale E2E training, offering a practical alternative to photorealistic rendering. Project page: https://alan-lanfeng.github.io/RAP/.
GLEAM: Learning Generalizable Exploration Policy for Active Mapping in Complex 3D Indoor Scenes
May 26, 2025Generalizable active mapping in complex unknown environments remains a critical challenge for mobile robots. Existing methods, constrained by insufficient training data and conservative exploration strategies, exhibit limited generalizability across scenes with diverse layouts and complex connectivity. To enable scalable training and reliable evaluation, we introduce GLEAM-Bench, the first large-scale benchmark designed for generalizable active mapping with 1,152 diverse 3D scenes from synthetic and real-scan datasets. Building upon this foundation, we propose GLEAM, a unified generalizable exploration policy for active mapping. Its superior generalizability comes mainly from our semantic representations, long-term navigable goals, and randomized strategies. It significantly outperforms state-of-the-art methods, achieving 66.50% coverage (+9.49%) with efficient trajectories and improved mapping accuracy on 128 unseen complex scenes. Project page: https://xiao-chen.tech/gleam/.
Task Reconstruction and Extrapolation for $π_0$ using Text Latent
May 06, 2025Vision-language-action models (VLAs) often achieve high performance on demonstrated tasks but struggle significantly when required to extrapolate, combining skills learned from different tasks in novel ways. For instance, VLAs might successfully put the cream cheese in the bowl and put the bowl on top of the cabinet, yet still fail to put the cream cheese on top of the cabinet. In this work, we demonstrate that behaviors from distinct tasks can be effectively recombined by manipulating the VLA's internal representations at inference time. Concretely, we identify the text latent by averaging the text tokens' hidden states across all demonstrated trajectories for a specific base task. For executing an extrapolated task, we can temporally interpolate the text latent of the two base tasks and add it back to the text hidden states, so sub-behaviors from the two tasks will be activated sequentially. We evaluate this approach using the newly created libero-ood benchmark, featuring 20 tasks extrapolated from standard LIBERO suites. The results on libero-ood show that all SOTA VLAs achieve < 15% success rate, while $\pi0$ with text latent interpolation reaches an 83% success rate. Further qualitative analysis reveals a tendency for VLAs to exhibit spatial overfitting, mapping object names to demonstrated locations rather than achieving genuine object and goal understanding. Additionally, we find that decoding the text latent yields human-unreadable prompts that can nevertheless instruct the VLA to achieve a 70% success rate on standard LIBERO suites, enabling private instruction or backdoor attacks.
Towards Autonomous Micromobility through Scalable Urban Simulation
May 01, 2025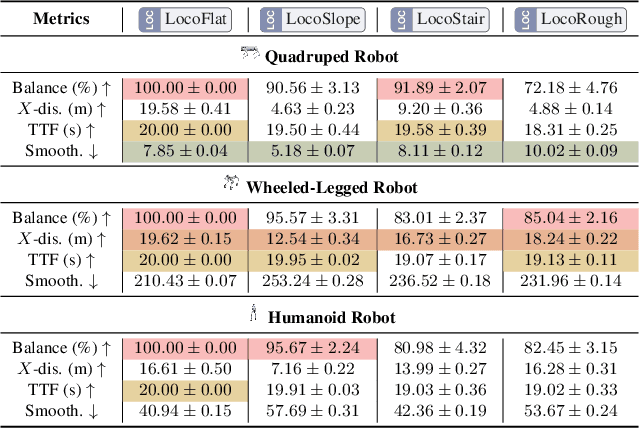

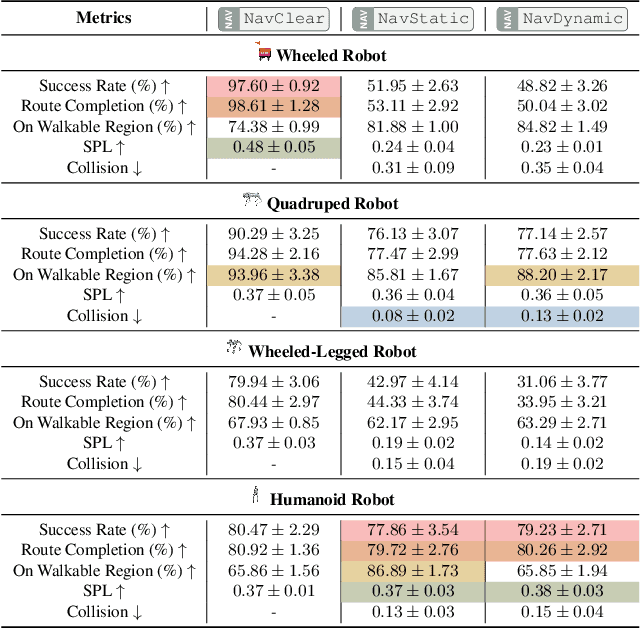
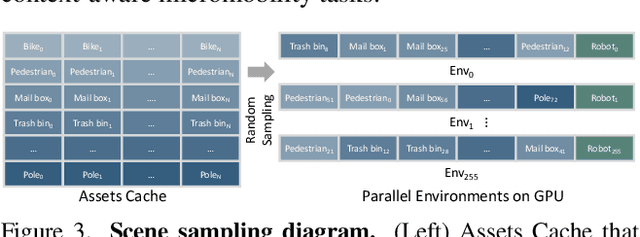
Micromobility, which utilizes lightweight mobile machines moving in urban public spaces, such as delivery robots and mobility scooters, emerges as a promising alternative to vehicular mobility. Current micromobility depends mostly on human manual operation (in-person or remote control), which raises safety and efficiency concerns when navigating busy urban environments full of unpredictable obstacles and pedestrians. Assisting humans with AI agents in maneuvering micromobility devices presents a viable solution for enhancing safety and efficiency. In this work, we present a scalable urban simulation solution to advance autonomous micromobility. First, we build URBAN-SIM - a high-performance robot learning platform for large-scale training of embodied agents in interactive urban scenes. URBAN-SIM contains three critical modules: Hierarchical Urban Generation pipeline, Interactive Dynamics Generation strategy, and Asynchronous Scene Sampling scheme, to improve the diversity, realism, and efficiency of robot learning in simulation. Then, we propose URBAN-BENCH - a suite of essential tasks and benchmarks to gauge various capabilities of the AI agents in achieving autonomous micromobility. URBAN-BENCH includes eight tasks based on three core skills of the agents: Urban Locomotion, Urban Navigation, and Urban Traverse. We evaluate four robots with heterogeneous embodiments, such as the wheeled and legged robots, across these tasks. Experiments on diverse terrains and urban structures reveal each robot's strengths and limitations.
Learning from Active Human Involvement through Proxy Value Propagation
Feb 05, 2025Learning from active human involvement enables the human subject to actively intervene and demonstrate to the AI agent during training. The interaction and corrective feedback from human brings safety and AI alignment to the learning process. In this work, we propose a new reward-free active human involvement method called Proxy Value Propagation for policy optimization. Our key insight is that a proxy value function can be designed to express human intents, wherein state-action pairs in the human demonstration are labeled with high values, while those agents' actions that are intervened receive low values. Through the TD-learning framework, labeled values of demonstrated state-action pairs are further propagated to other unlabeled data generated from agents' exploration. The proxy value function thus induces a policy that faithfully emulates human behaviors. Human-in-the-loop experiments show the generality and efficiency of our method. With minimal modification to existing reinforcement learning algorithms, our method can learn to solve continuous and discrete control tasks with various human control devices, including the challenging task of driving in Grand Theft Auto V. Demo video and code are available at: https://metadriverse.github.io/pvp
MetaUrban: A Simulation Platform for Embodied AI in Urban Spaces
Jul 11, 2024



Public urban spaces like streetscapes and plazas serve residents and accommodate social life in all its vibrant variations. Recent advances in Robotics and Embodied AI make public urban spaces no longer exclusive to humans. Food delivery bots and electric wheelchairs have started sharing sidewalks with pedestrians, while diverse robot dogs and humanoids have recently emerged in the street. Ensuring the generalizability and safety of these forthcoming mobile machines is crucial when navigating through the bustling streets in urban spaces. In this work, we present MetaUrban, a compositional simulation platform for Embodied AI research in urban spaces. MetaUrban can construct an infinite number of interactive urban scenes from compositional elements, covering a vast array of ground plans, object placements, pedestrians, vulnerable road users, and other mobile agents' appearances and dynamics. We design point navigation and social navigation tasks as the pilot study using MetaUrban for embodied AI research and establish various baselines of Reinforcement Learning and Imitation Learning. Experiments demonstrate that the compositional nature of the simulated environments can substantially improve the generalizability and safety of the trained mobile agents. MetaUrban will be made publicly available to provide more research opportunities and foster safe and trustworthy embodied AI in urban spaces.
Learning H-Infinity Locomotion Control
Apr 22, 2024Stable locomotion in precipitous environments is an essential capability of quadruped robots, demanding the ability to resist various external disturbances. However, recent learning-based policies only use basic domain randomization to improve the robustness of learned policies, which cannot guarantee that the robot has adequate disturbance resistance capabilities. In this paper, we propose to model the learning process as an adversarial interaction between the actor and a newly introduced disturber and ensure their optimization with $H_{\infty}$ constraint. In contrast to the actor that maximizes the discounted overall reward, the disturber is responsible for generating effective external forces and is optimized by maximizing the error between the task reward and its oracle, i.e., "cost" in each iteration. To keep joint optimization between the actor and the disturber stable, our $H_{\infty}$ constraint mandates the bound of ratio between the cost to the intensity of the external forces. Through reciprocal interaction throughout the training phase, the actor can acquire the capability to navigate increasingly complex physical disturbances. We verify the robustness of our approach on quadrupedal locomotion tasks with Unitree Aliengo robot, and also a more challenging task with Unitree A1 robot, where the quadruped is expected to perform locomotion merely on its hind legs as if it is a bipedal robot. The simulated quantitative results show improvement against baselines, demonstrating the effectiveness of the method and each design choice. On the other hand, real-robot experiments qualitatively exhibit how robust the policy is when interfering with various disturbances on various terrains, including stairs, high platforms, slopes, and slippery terrains. All code, checkpoints, and real-world deployment guidance will be made public.
A Holistic Framework Towards Vision-based Traffic Signal Control with Microscopic Simulation
Mar 11, 2024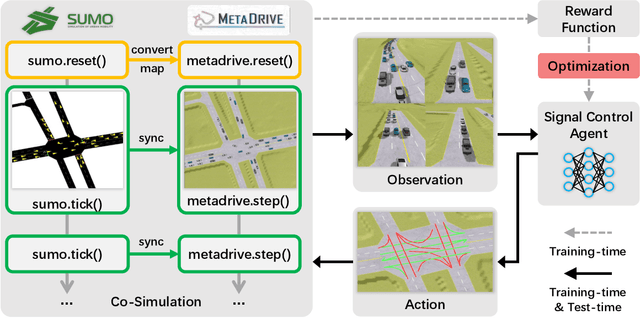
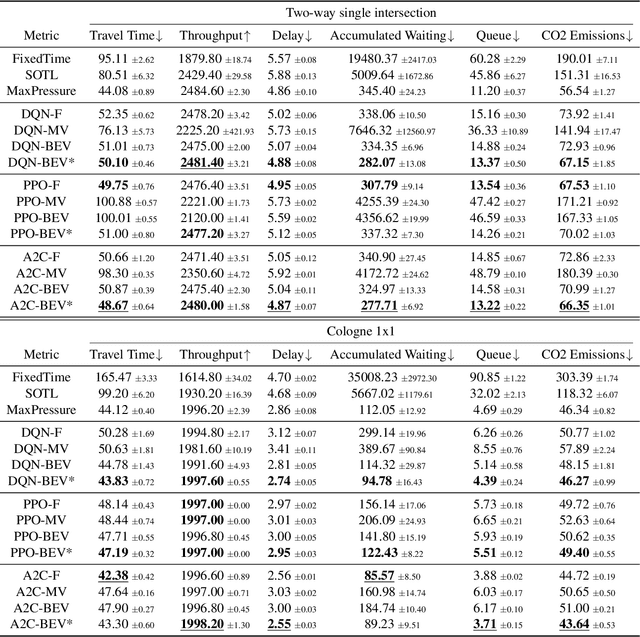
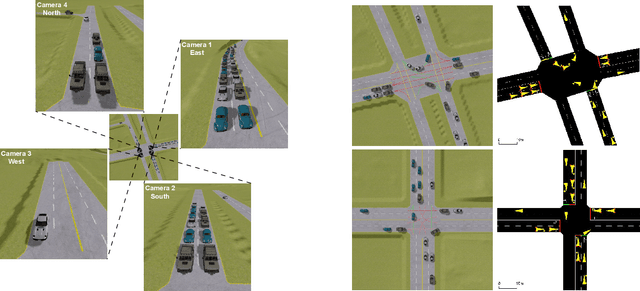
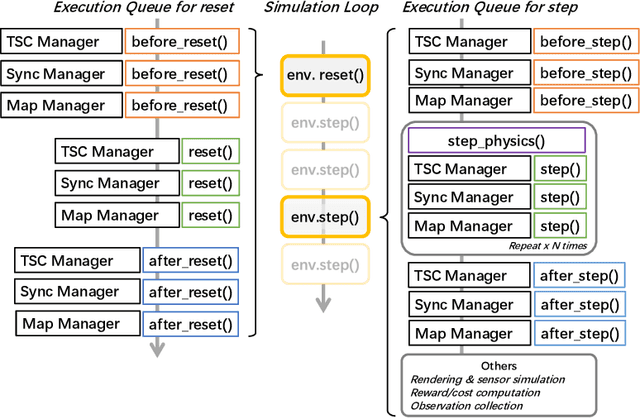
Traffic signal control (TSC) is crucial for reducing traffic congestion that leads to smoother traffic flow, reduced idling time, and mitigated CO2 emissions. In this study, we explore the computer vision approach for TSC that modulates on-road traffic flows through visual observation. Unlike traditional feature-based approaches, vision-based methods depend much less on heuristics and predefined features, bringing promising potentials for end-to-end learning and optimization of traffic signals. Thus, we introduce a holistic traffic simulation framework called TrafficDojo towards vision-based TSC and its benchmarking by integrating the microscopic traffic flow provided in SUMO into the driving simulator MetaDrive. This proposed framework offers a versatile traffic environment for in-depth analysis and comprehensive evaluation of traffic signal controllers across diverse traffic conditions and scenarios. We establish and compare baseline algorithms including both traditional and Reinforecment Learning (RL) approaches. This work sheds insights into the design and development of vision-based TSC approaches and open up new research opportunities. All the code and baselines will be made publicly available.