 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOBA: A Material-Oriented Backdoor Attack against LiDAR-based 3D Object Detection Systems
Nov 13, 2025LiDAR-based 3D object detection is widely used in safety-critical systems. However, these systems remain vulnerable to backdoor attacks that embed hidden malicious behaviors during training. A key limitation of existing backdoor attacks is their lack of physical realizability, primarily due to the digital-to-physical domain gap. Digital triggers often fail in real-world settings because they overlook material-dependent LiDAR reflection properties. On the other hand, physically constructed triggers are often unoptimized, leading to low effectiveness or easy detectability.This paper introduces Material-Oriented Backdoor Attack (MOBA), a novel framework that bridges the digital-physical gap by explicitly modeling the material properties of real-world triggers. MOBA tackles two key challenges in physical backdoor design: 1) robustness of the trigger material under diverse environmental conditions, 2) alignment between the physical trigger's behavior and its digital simulation. First, we propose a systematic approach to selecting robust trigger materials, identifying titanium dioxide (TiO_2) for its high diffuse reflectivity and environmental resilience. Second, to ensure the digital trigger accurately mimics the physical behavior of the material-based trigger, we develop a novel simulation pipeline that features: (1) an angle-independent approximation of the Oren-Nayar BRDF model to generate realistic LiDAR intensities, and (2) a distance-aware scaling mechanism to maintain spatial consistency across varying depths. We conduct extensive experiments on state-of-the-art LiDAR-based and Camera-LiDAR fusion models, showing that MOBA achieves a 93.50% attack success rate, outperforming prior methods by over 41%. Our work reveals a new class of physically realizable threats and underscores the urgent need for defenses that account for material-level properties in real-world environments.
VERA: Explainable Video Anomaly Detection via Verbalized Learning of Vision-Language Models
Dec 02, 2024



The rapid advancement of vision-language models (VLMs) has established a new paradigm in video anomaly detection (VAD): leveraging VLMs to simultaneously detect anomalies and provide comprehendible explanations for the decisions. Existing work in this direction often assumes the complex reasoning required for VAD exceeds the capabilities of pretrained VLMs. Consequently, these approaches either incorporate specialized reasoning modules during inference or rely on instruction tuning datasets through additional training to adapt VLMs for VAD. However, such strategies often incur substantial computational costs or data annotation overhead. To address these challenges in explainable VAD, we introduce a verbalized learning framework named VERA that enables VLMs to perform VAD without model parameter modifications. Specifically, VERA automatically decomposes the complex reasoning required for VAD into reflections on simpler, more focused guiding questions capturing distinct abnormal patterns. It treats these reflective questions as learnable parameters and optimizes them through data-driven verbal interactions between learner and optimizer VLMs, using coarsely labeled training data. During inference, VERA embeds the learned questions into model prompts to guide VLMs in generating segment-level anomaly scores, which are then refined into frame-level scores via the fusion of scene and temporal contexts. Experimental results on challenging benchmarks demonstrate that the learned questions of VERA are highly adaptable, significantly improving both detection performance and explainability of VLMs for VAD.
BadFusion: 2D-Oriented Backdoor Attacks against 3D Object Detection
May 06, 2024



3D object detection plays an important role in autonomous driving; however, its vulnerability to backdoor attacks has become evident. By injecting ''triggers'' to poison the training dataset, backdoor attacks manipulate the detector's prediction for inputs containing these triggers. Existing backdoor attacks against 3D object detection primarily poison 3D LiDAR signals, where large-sized 3D triggers are injected to ensure their visibility within the sparse 3D space, rendering them easy to detect and impractical in real-world scenarios. In this paper, we delve into the robustness of 3D object detection, exploring a new backdoor attack surface through 2D cameras. Given the prevalent adoption of camera and LiDAR signal fusion for high-fidelity 3D perception, we investigate the latent potential of camera signals to disrupt the process. Although the dense nature of camera signals enables the use of nearly imperceptible small-sized triggers to mislead 2D object detection, realizing 2D-oriented backdoor attacks against 3D object detection is non-trivial. The primary challenge emerges from the fusion process that transforms camera signals into a 3D space, compromising the association with the 2D trigger to the target output. To tackle this issue, we propose an innovative 2D-oriented backdoor attack against LiDAR-camera fusion methods for 3D object detection, named BadFusion, for preserving trigger effectiveness throughout the entire fusion process. The evaluation demonstrates the effectiveness of BadFusion, achieving a significantly higher attack success rate compared to existing 2D-oriented attacks.
A Holistic Framework Towards Vision-based Traffic Signal Control with Microscopic Simulation
Mar 11, 2024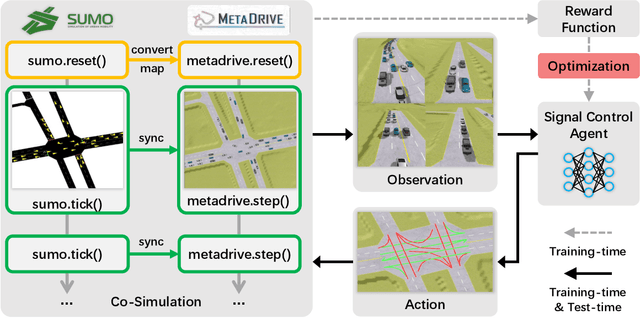
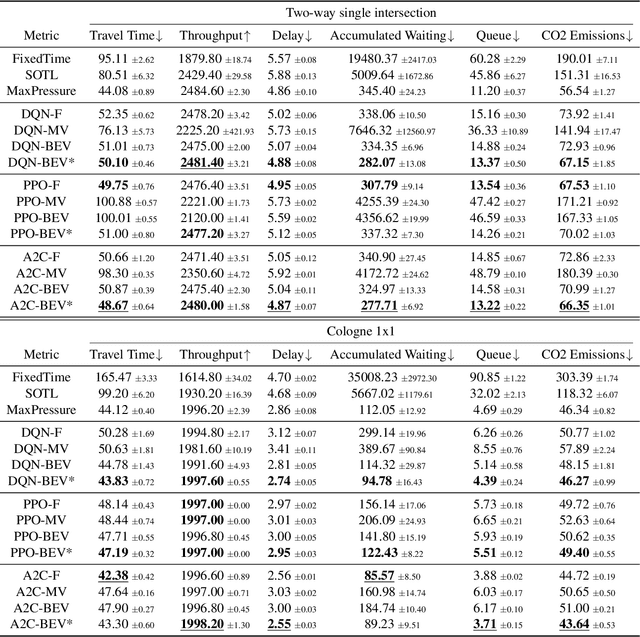
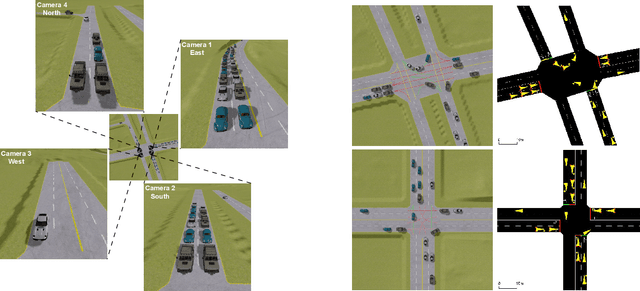
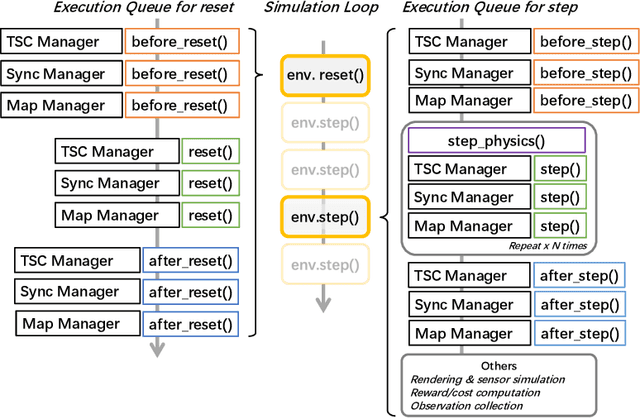
Traffic signal control (TSC) is crucial for reducing traffic congestion that leads to smoother traffic flow, reduced idling time, and mitigated CO2 emissions. In this study, we explore the computer vision approach for TSC that modulates on-road traffic flows through visual observation. Unlike traditional feature-based approaches, vision-based methods depend much less on heuristics and predefined features, bringing promising potentials for end-to-end learning and optimization of traffic signals. Thus, we introduce a holistic traffic simulation framework called TrafficDojo towards vision-based TSC and its benchmarking by integrating the microscopic traffic flow provided in SUMO into the driving simulator MetaDrive. This proposed framework offers a versatile traffic environment for in-depth analysis and comprehensive evaluation of traffic signal controllers across diverse traffic conditions and scenarios. We establish and compare baseline algorithms including both traditional and Reinforecment Learning (RL) approaches. This work sheds insights into the design and development of vision-based TSC approaches and open up new research opportunities. All the code and baselines will be made publicly available.
A Spatiotemporal Correspondence Approach to Unsupervised LiDAR Segmentation with Traffic Applications
Aug 23, 2023



We address the problem of unsupervised semantic segmentation of outdoor LiDAR point clouds in diverse traffic scenarios. The key idea is to leverage the spatiotemporal nature of a dynamic point cloud sequence and introduce drastically stronger augmentation by establishing spatiotemporal correspondences across multiple frames. We dovetail clustering and pseudo-label learning in this work. Essentially, we alternate between clustering points into semantic groups and optimizing models using point-wise pseudo-spatiotemporal labels with a simple learning objective. Therefore, our method can learn discriminative features in an unsupervised learning fashion. We show promising segmentation performance on Semantic-KITTI, SemanticPOSS, and FLORIDA benchmark datasets covering scenarios in autonomous vehicle and intersection infrastructure, which is competitive when compared against many existing fully supervised learning methods. This general framework can lead to a unified representation learning approach for LiDAR point clouds incorporating domain knowledge.
An Efficient Semi-Automated Scheme for Infrastructure LiDAR Annotation
Jan 25, 2023



Most existing perception systems rely on sensory data acquired from cameras, which perform poorly in low light and adverse weather conditions. To resolve this limitation, we have witnessed advanced LiDAR sensors become popular in perception tasks in autonomous driving applications. Nevertheless, their usage in traffic monitoring systems is less ubiquitous. We identify two significant obstacles in cost-effectively and efficiently developing such a LiDAR-based traffic monitoring system: (i) public LiDAR datasets are insufficient for supporting perception tasks in infrastructure systems, and (ii) 3D annotations on LiDAR point clouds are time-consuming and expensive. To fill this gap, we present an efficient semi-automated annotation tool that automatically annotates LiDAR sequences with tracking algorithms while offering a fully annotated infrastructure LiDAR dataset -- FLORIDA (Florida LiDAR-based Object Recognition and Intelligent Data Annotation) -- which will be made publicly available. Our advanced annotation tool seamlessly integrates multi-object tracking (MOT), single-object tracking (SOT), and suitable trajectory post-processing techniques. Specifically, we introduce a human-in-the-loop schema in which annotators recursively fix and refine annotations imperfectly predicted by our tool and incrementally add them to the training dataset to obtain better SOT and MOT models. By repeating the process, we significantly increase the overall annotation speed by three to four times and obtain better qualitative annotations than a state-of-the-art annotation tool. The human annotation experiments verify the effectiveness of our annotation tool. In addition, we provide detailed statistics and object detection evaluation results for our dataset in serving as a benchmark for perception tasks at traffic intersections.
Expressing linear equality constraints in feedforward neural networks
Nov 08, 2022


We seek to impose linear, equality constraints in feedforward neural networks. As top layer predictors are usually nonlinear, this is a difficult task if we seek to deploy standard convex optimization methods and strong duality. To overcome this, we introduce a new saddle-point Lagrangian with auxiliary predictor variables on which constraints are imposed. Elimination of the auxiliary variables leads to a dual minimization problem on the Lagrange multipliers introduced to satisfy the linear constraints. This minimization problem is combined with the standard learning problem on the weight matrices. From this theoretical line of development, we obtain the surprising interpretation of Lagrange parameters as additional, penultimate layer hidden units with fixed weights stemming from the constraints. Consequently, standard minimization approaches can be used despite the inclusion of Lagrange parameters -- a very satisfying, albeit unexpected, discovery. Examples ranging from multi-label classification to constrained autoencoders are envisaged in the future.
Learning Canonical Embeddings for Unsupervised Shape Correspondence with Locally Linear Transformations
Sep 07, 2022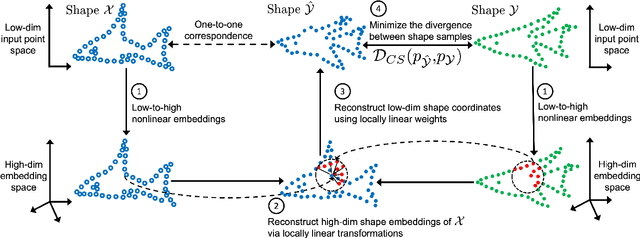
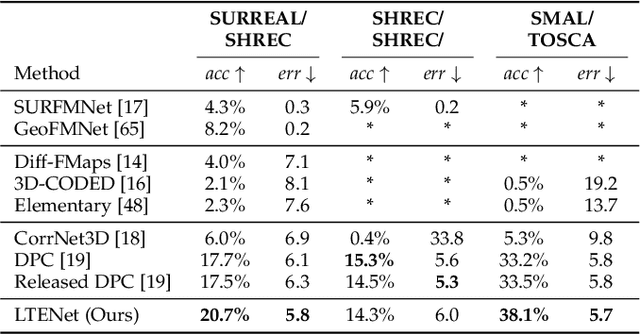
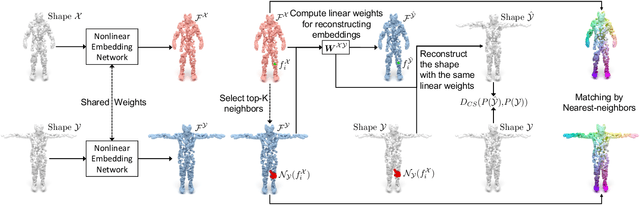

We present a new approach to unsupervised shape correspondence learning between pairs of point clouds. We make the first attempt to adapt the classical locally linear embedding algorithm (LLE) -- originally designed for nonlinear dimensionality reduction -- for shape correspondence. The key idea is to find dense correspondences between shapes by first obtaining high-dimensional neighborhood-preserving embeddings of low-dimensional point clouds and subsequently aligning the source and target embeddings using locally linear transformations. We demonstrate that learning the embedding using a new LLE-inspired point cloud reconstruction objective results in accurate shape correspondences. More specifically, the approach comprises an end-to-end learnable framework of extracting high-dimensional neighborhood-preserving embeddings, estimating locally linear transformations in the embedding space, and reconstructing shapes via divergence measure-based alignment of probabilistic density functions built over reconstructed and target shapes. Our approach enforces embeddings of shapes in correspondence to lie in the same universal/canonical embedding space, which eventually helps regularize the learning process and leads to a simple nearest neighbors approach between shape embeddings for finding reliable correspondences. Comprehensive experiments show that the new method makes noticeable improvements over state-of-the-art approaches on standard shape correspondence benchmark datasets covering both human and nonhuman shapes.
Slot Order Matters for Compositional Scene Understanding
Jun 03, 2022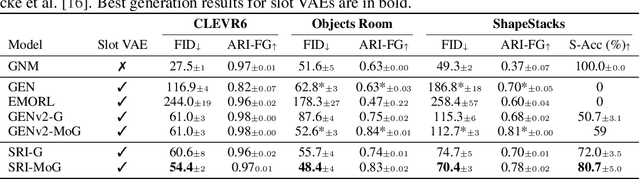
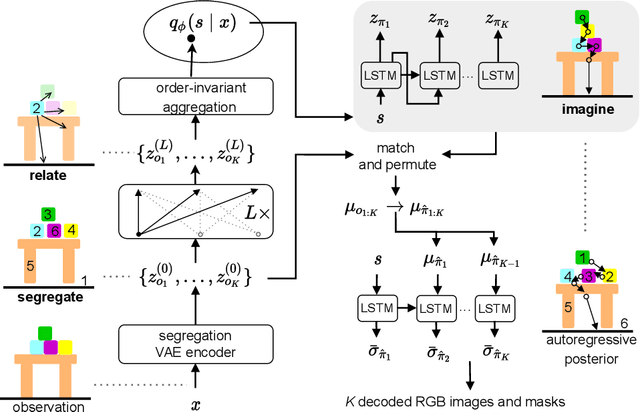


Empowering agents with a compositional understanding of their environment is a promising next step toward solving long-horizon planning problems. On the one hand, we have seen encouraging progress on variational inference algorithms for obtaining sets of object-centric latent representations ("slots") from unstructured scene observations. On the other hand, generating scenes from slots has received less attention, in part because it is complicated by the lack of a canonical object order. A canonical object order is useful for learning the object correlations necessary to generate physically plausible scenes similar to how raster scan order facilitates learning pixel correlations for pixel-level autoregressive image generation. In this work, we address this lack by learning a fixed object order for a hierarchical variational autoencoder with a single level of autoregressive slots and a global scene prior. We cast autoregressive slot inference as a set-to-sequence modeling problem. We introduce an auxiliary loss to train the slot prior to generate objects in a fixed order. During inference, we align a set of inferred slots to the object order obtained from a slot prior rollout. To ensure the rolled out objects are meaningful for the given scene, we condition the prior on an inferred global summary of the input. Experiments on compositional environments and ablations demonstrate that our model with global prior, inference with aligned slot order, and auxiliary loss achieves state-of-the-art sample quality.
Self-Supervised Robust Scene Flow Estimation via the Alignment of Probability Density Functions
Mar 23, 2022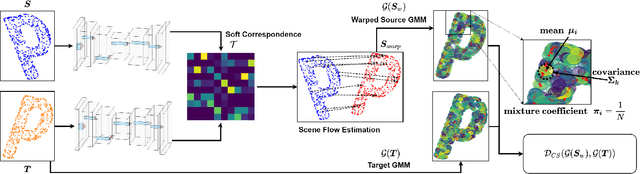
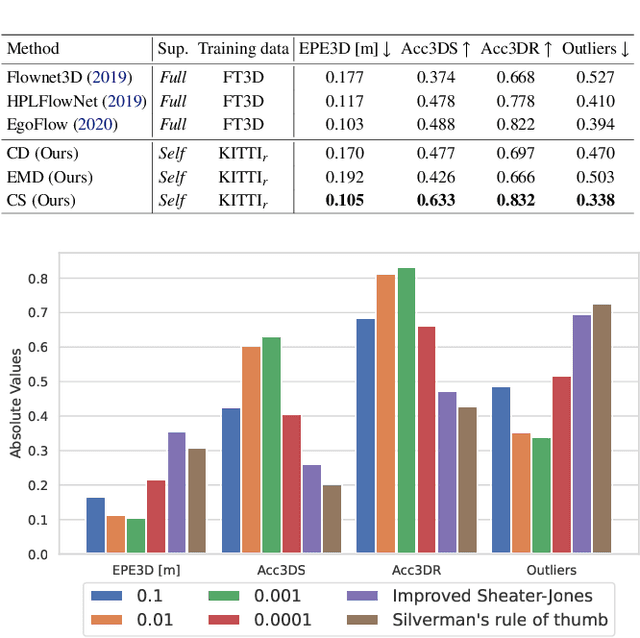
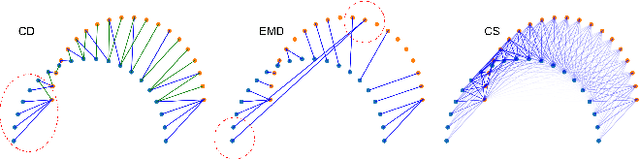
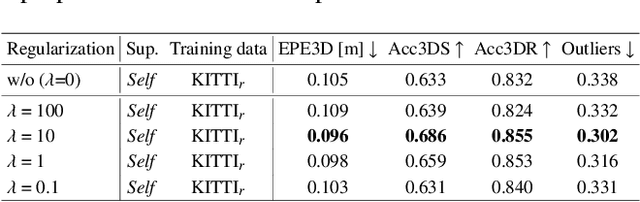
In this paper, we present a new self-supervised scene flow estimation approach for a pair of consecutive point clouds. The key idea of our approach is to represent discrete point clouds as continuous probability density functions using Gaussian mixture models. Scene flow estimation is therefore converted into the problem of recovering motion from the alignment of probability density functions, which we achieve using a closed-form expression of the classic Cauchy-Schwarz divergence. Unlike existing nearest-neighbor-based approaches that use hard pairwise correspondences, our proposed approach establishes soft and implicit point correspondences between point clouds and generates more robust and accurate scene flow in the presence of missing correspondences and outliers. Comprehensive experiments show that our method makes noticeable gains over the Chamfer Distance and the Earth Mover's Distance in real-world environments and achieves state-of-the-art performance among self-supervised learning methods on FlyingThings3D and KITTI, even outperforming some supervised methods with ground truth annotations.