 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixRea: Benchmarking Explicit-Implicit Reasoning in Large Language Models
May 19, 2026Large language models (LLMs) are increasingly integrated into high-stakes decision-making. Inspired by the theory of \emph{inattentional blindness} in human cognition, we investigate whether LLMs, trained on human-preferred corpora that embed attentional biases, exhibit a similar limitation: \emph{failing to attend to subtle yet important contextual cues under explicit task instructions}. To evaluate this, we introduce the task of \textbf{explicit-implicit reasoning} and present \textbf{MixRea}, a benchmark of 2,246 multiple-choice questions across 9 reasoning types with varying distributions of explicit and implicit information. Evaluation of 21 advanced LLMs shows that even the best-performing reasoning model (Gemini 2.5 Pro) achieves only 42.8\% consistency, revealing widespread inattentional blindness. To mitigate this, we propose \textbf{Potential Relation Completion Prompting (PRCP)}, a prompting method that improves reasoning by recovering overlooked causal relations. Further analysis shows that this limitation persists across diverse multi-source reasoning tasks, highlighting the need for more cognitively aligned models.
TimeCatcher: A Variational Framework for Volatility-Aware Forecasting of Non-Stationary Time Series
Jan 28, 2026Recent lightweight MLP-based models have achieved strong performance in time series forecasting by capturing stable trends and seasonal patterns. However, their effectiveness hinges on an implicit assumption of local stationarity assumption, making them prone to errors in long-term forecasting of highly non-stationary series, especially when abrupt fluctuations occur, a common challenge in domains like web traffic monitoring. To overcome this limitation, we propose TimeCatcher, a novel Volatility-Aware Variational Forecasting framework. TimeCatcher extends linear architectures with a variational encoder to capture latent dynamic patterns hidden in historical data and a volatility-aware enhancement mechanism to detect and amplify significant local variations. Experiments on nine real-world datasets from traffic, financial, energy, and weather domains show that TimeCatcher consistently outperforms state-of-the-art baselines, with particularly large improvements in long-term forecasting scenarios characterized by high volatility and sudden fluctuations. Our code is available at https://github.com/ColaPrinceCHEN/TimeCatcher.
Smart Energy Guardian: A Hybrid Deep Learning Model for Detecting Fraudulent PV Generation
May 24, 2025With the proliferation of smart grids, smart cities face growing challenges due to cyber-attacks and sophisticated electricity theft behaviors, particularly in residential photovoltaic (PV) generation systems. Traditional Electricity Theft Detection (ETD) methods often struggle to capture complex temporal dependencies and integrating multi-source data, limiting their effectiveness. In this work, we propose an efficient ETD method that accurately identifies fraudulent behaviors in residential PV generation, thus ensuring the supply-demand balance in smart cities. Our hybrid deep learning model, combining multi-scale Convolutional Neural Network (CNN), Long Short-Term Memory (LSTM), and Transformer, excels in capturing both short-term and long-term temporal dependencies. Additionally, we introduce a data embedding technique that seamlessly integrates time-series data with discrete temperature variables, enhancing detection robustness. Extensive simulation experiments using real-world data validate the effectiveness of our approach, demonstrating significant improvements in the accuracy of detecting sophisticated energy theft activities, thereby contributing to the stability and fairness of energy systems in smart cities.
Season-Independent PV Disaggregation Using Multi-Scale Net Load Temporal Feature Extraction and Weather Factor Fusion
May 24, 2025With the advancement of energy Internet and energy system integration, the increasing adoption of distributed photovoltaic (PV) systems presents new challenges on smart monitoring and measurement for utility companies, particularly in separating PV generation from net electricity load. Existing methods struggle with feature extraction from net load and capturing the relevance between weather factors. This paper proposes a PV disaggregation method that integrates Hierarchical Interpolation (HI) and multi-head self-attention mechanisms. By using HI to extract net load features and multi-head self-attention to capture the complex dependencies between weather factors, the method achieves precise PV generation predictions. Simulation experiments demonstrate the effectiveness of the proposed method in real-world data, supporting improved monitoring and management of distributed energy systems.
MVOC: a training-free multiple video object composition method with diffusion models
Jun 22, 2024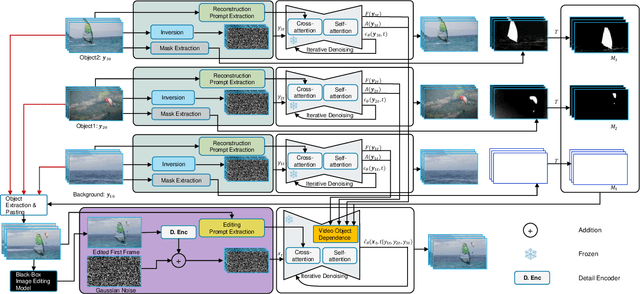
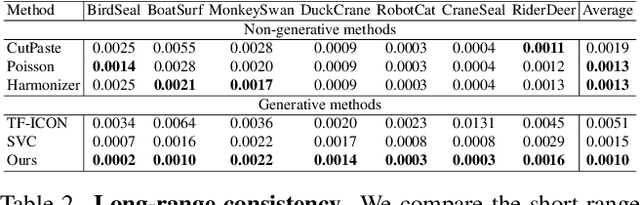
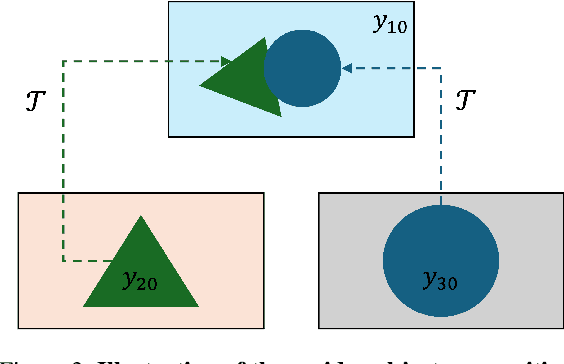

Video composition is the core task of video editing. Although image composition based on diffusion models has been highly successful, it is not straightforward to extend the achievement to video object composition tasks, which not only exhibit corresponding interaction effects but also ensure that the objects in the composited video maintain motion and identity consistency, which is necessary to composite a physical harmony video. To address this challenge, we propose a Multiple Video Object Composition (MVOC) method based on diffusion models. Specifically, we first perform DDIM inversion on each video object to obtain the corresponding noise features. Secondly, we combine and edit each object by image editing methods to obtain the first frame of the composited video. Finally, we use the image-to-video generation model to composite the video with feature and attention injections in the Video Object Dependence Module, which is a training-free conditional guidance operation for video generation, and enables the coordination of features and attention maps between various objects that can be non-independent in the composited video. The final generative model not only constrains the objects in the generated video to be consistent with the original object motion and identity, but also introduces interaction effects between objects. Extensive experiments have demonstrated that the proposed method outperforms existing state-of-the-art approaches. Project page: https://sobeymil.github.io/mvoc.com.
FedCRL: Personalized Federated Learning with Contrastive Shared Representations for Label Heterogeneity in Non-IID Data
Apr 27, 2024



To deal with heterogeneity resulting from label distribution skew and data scarcity in distributed machine learning scenarios, this paper proposes a novel Personalized Federated Learning (PFL) algorithm, named Federated Contrastive Representation Learning (FedCRL). FedCRL introduces contrastive representation learning (CRL) on shared representations to facilitate knowledge acquisition of clients. Specifically, both local model parameters and averaged values of local representations are considered as shareable information to the server, both of which are then aggregated globally. CRL is applied between local representations and global representations to regularize personalized training by drawing similar representations closer and separating dissimilar ones, thereby enhancing local models with external knowledge and avoiding being harmed by label distribution skew. Additionally, FedCRL adopts local aggregation between each local model and the global model to tackle data scarcity. A loss-wise weighting mechanism is introduced to guide the local aggregation using each local model's contrastive loss to coordinate the global model involvement in each client, thus helping clients with scarce data. Our simulations demonstrate FedCRL's effectiveness in mitigating label heterogeneity by achieving accuracy improvements over existing methods on datasets with varying degrees of label heterogeneity.
Temporal-Aware Deep Reinforcement Learning for Energy Storage Bidding in Energy and Contingency Reserve Markets
Feb 29, 2024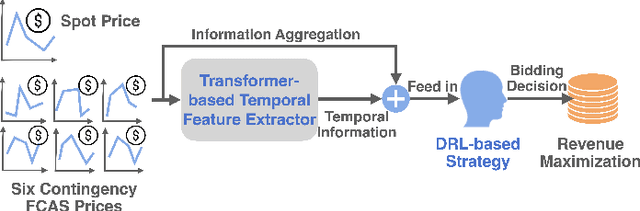
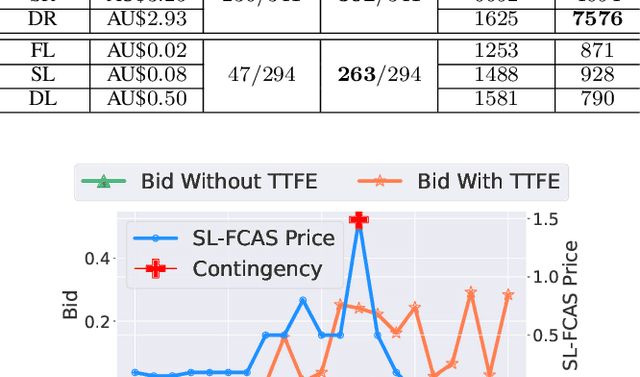
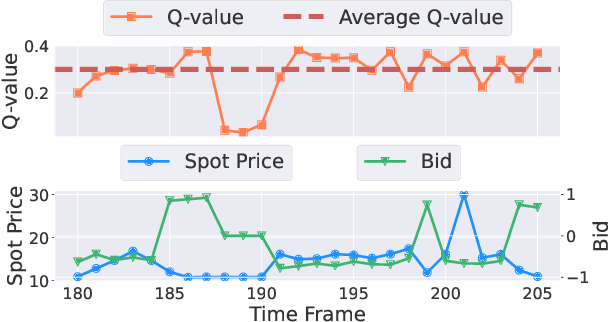
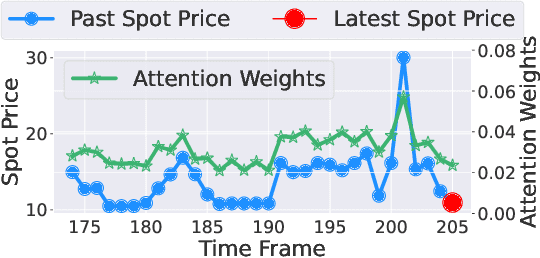
The battery energy storage system (BESS) has immense potential for enhancing grid reliability and security through its participation in the electricity market. BESS often seeks various revenue streams by taking part in multiple markets to unlock its full potential, but effective algorithms for joint-market participation under price uncertainties are insufficiently explored in the existing research. To bridge this gap, we develop a novel BESS joint bidding strategy that utilizes deep reinforcement learning (DRL) to bid in the spot and contingency frequency control ancillary services (FCAS) markets. Our approach leverages a transformer-based temporal feature extractor to effectively respond to price fluctuations in seven markets simultaneously and helps DRL learn the best BESS bidding strategy in joint-market participation. Additionally, unlike conventional "black-box" DRL model, our approach is more interpretable and provides valuable insights into the temporal bidding behavior of BESS in the dynamic electricity market. We validate our method using realistic market prices from the Australian National Electricity Market. The results show that our strategy outperforms benchmarks, including both optimization-based and other DRL-based strategies, by substantial margins. Our findings further suggest that effective temporal-aware bidding can significantly increase profits in the spot and contingency FCAS markets compared to individual market participation.
* 15 pages
PokerGPT: An End-to-End Lightweight Solver for Multi-Player Texas Hold'em via Large Language Model
Jan 04, 2024Poker, also known as Texas Hold'em, has always been a typical research target within imperfect information games (IIGs). IIGs have long served as a measure of artificial intelligence (AI) development. Representative prior works, such as DeepStack and Libratus heavily rely on counterfactual regret minimization (CFR) to tackle heads-up no-limit Poker. However, it is challenging for subsequent researchers to learn CFR from previous models and apply it to other real-world applications due to the expensive computational cost of CFR iterations. Additionally, CFR is difficult to apply to multi-player games due to the exponential growth of the game tree size. In this work, we introduce PokerGPT, an end-to-end solver for playing Texas Hold'em with arbitrary number of players and gaining high win rates, established on a lightweight large language model (LLM). PokerGPT only requires simple textual information of Poker games for generating decision-making advice, thus guaranteeing the convenient interaction between AI and humans. We mainly transform a set of textual records acquired from real games into prompts, and use them to fine-tune a lightweight pre-trained LLM using reinforcement learning human feedback technique. To improve fine-tuning performance, we conduct prompt engineering on raw data, including filtering useful information, selecting behaviors of players with high win rates, and further processing them into textual instruction using multiple prompt engineering techniques. Through the experiments, we demonstrate that PokerGPT outperforms previous approaches in terms of win rate, model size, training time, and response speed, indicating the great potential of LLMs in solving IIGs.
HyperLips: Hyper Control Lips with High Resolution Decoder for Talking Face Generation
Oct 15, 2023
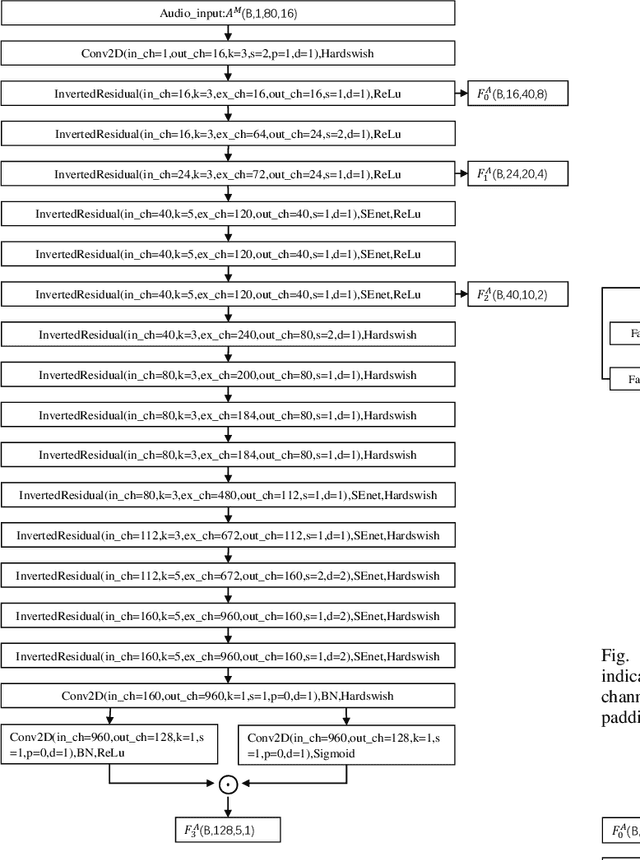


Talking face generation has a wide range of potential applications in the field of virtual digital humans. However, rendering high-fidelity facial video while ensuring lip synchronization is still a challenge for existing audio-driven talking face generation approaches. To address this issue, we propose HyperLips, a two-stage framework consisting of a hypernetwork for controlling lips and a high-resolution decoder for rendering high-fidelity faces. In the first stage, we construct a base face generation network that uses the hypernetwork to control the encoding latent code of the visual face information over audio. First, FaceEncoder is used to obtain latent code by extracting features from the visual face information taken from the video source containing the face frame.Then, HyperConv, which weighting parameters are updated by HyperNet with the audio features as input, will modify the latent code to synchronize the lip movement with the audio. Finally, FaceDecoder will decode the modified and synchronized latent code into visual face content. In the second stage, we obtain higher quality face videos through a high-resolution decoder. To further improve the quality of face generation, we trained a high-resolution decoder, HRDecoder, using face images and detected sketches generated from the first stage as input.Extensive quantitative and qualitative experiments show that our method outperforms state-of-the-art work with more realistic, high-fidelity, and lip synchronization. Project page: https://semchan.github.io/HyperLips Project/
FedTADBench: Federated Time-Series Anomaly Detection Benchmark
Dec 19, 2022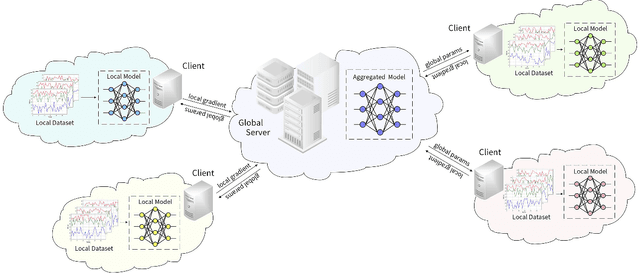
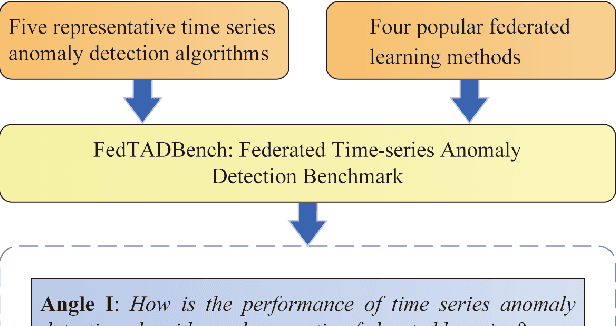
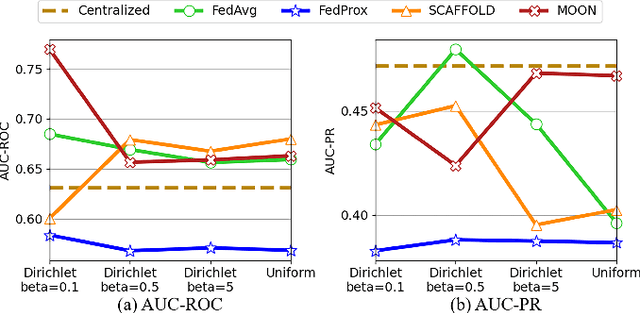
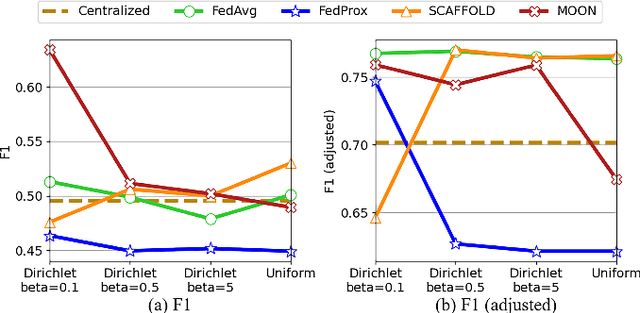
Time series anomaly detection strives to uncover potential abnormal behaviors and patterns from temporal data, and has fundamental significance in diverse application scenarios. Constructing an effective detection model usually requires adequate training data stored in a centralized manner, however, this requirement sometimes could not be satisfied in realistic scenarios. As a prevailing approach to address the above problem, federated learning has demonstrated its power to cooperate with the distributed data available while protecting the privacy of data providers. However, it is still unclear that how existing time series anomaly detection algorithms perform with decentralized data storage and privacy protection through federated learning. To study this, we conduct a federated time series anomaly detection benchmark, named FedTADBench, which involves five representative time series anomaly detection algorithms and four popular federated learning methods. We would like to answer the following questions: (1)How is the performance of time series anomaly detection algorithms when meeting federated learning? (2) Which federated learning method is the most appropriate one for time series anomaly detection? (3) How do federated time series anomaly detection approaches perform on different partitions of data in clients? Numbers of results as well as corresponding analysis are provided from extensive experiments with various settings. The source code of our benchmark is publicly available at https://github.com/fanxingliu2020/FedTADBench.