 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVOC: a training-free multiple video object composition method with diffusion models
Jun 22, 2024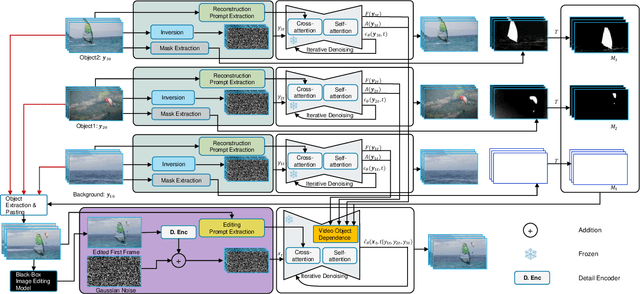
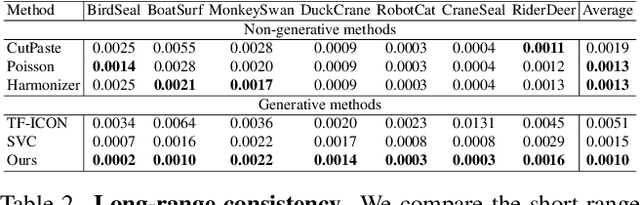
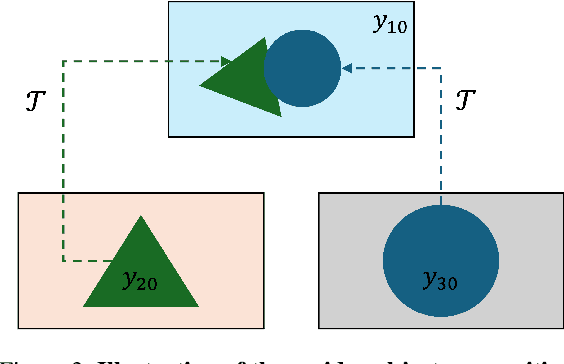

Video composition is the core task of video editing. Although image composition based on diffusion models has been highly successful, it is not straightforward to extend the achievement to video object composition tasks, which not only exhibit corresponding interaction effects but also ensure that the objects in the composited video maintain motion and identity consistency, which is necessary to composite a physical harmony video. To address this challenge, we propose a Multiple Video Object Composition (MVOC) method based on diffusion models. Specifically, we first perform DDIM inversion on each video object to obtain the corresponding noise features. Secondly, we combine and edit each object by image editing methods to obtain the first frame of the composited video. Finally, we use the image-to-video generation model to composite the video with feature and attention injections in the Video Object Dependence Module, which is a training-free conditional guidance operation for video generation, and enables the coordination of features and attention maps between various objects that can be non-independent in the composited video. The final generative model not only constrains the objects in the generated video to be consistent with the original object motion and identity, but also introduces interaction effects between objects. Extensive experiments have demonstrated that the proposed method outperforms existing state-of-the-art approaches. Project page: https://sobeymil.github.io/mvoc.com.