 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinancial Risk Assessment via Long-term Payment Behavior Sequence Folding
Nov 22, 2024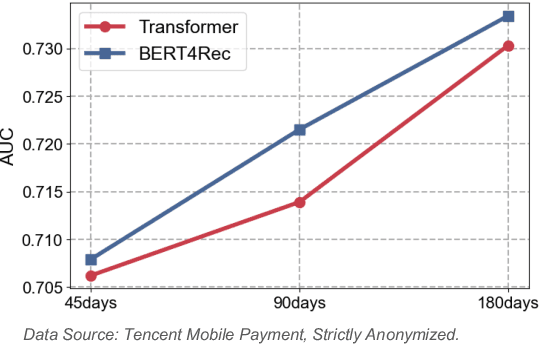
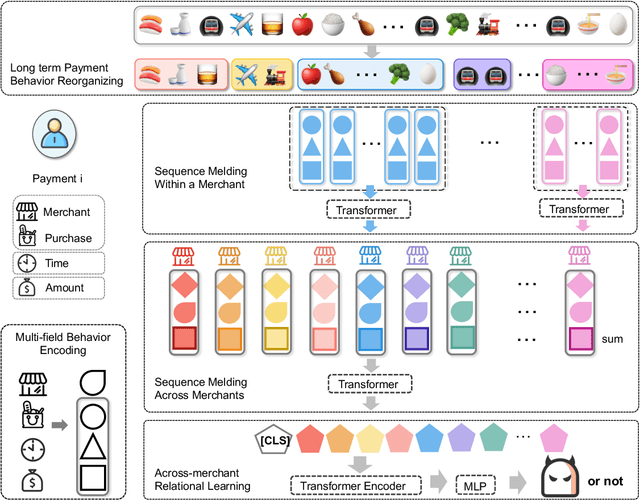
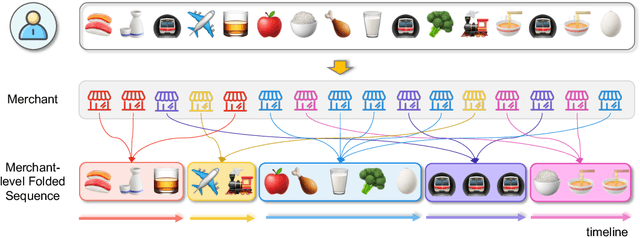
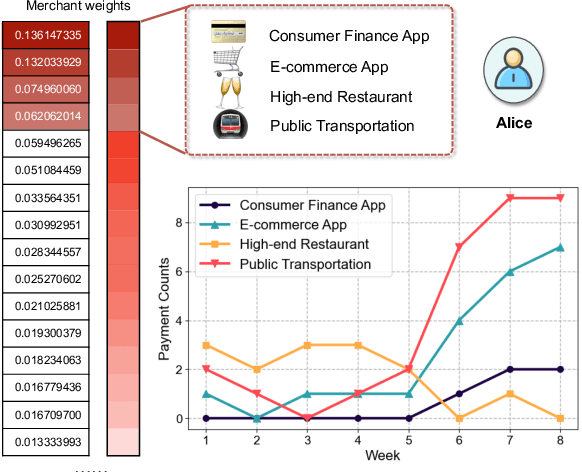
Online inclusive financial services encounter significant financial risks due to their expansive user base and low default costs. By real-world practice, we reveal that utilizing longer-term user payment behaviors can enhance models' ability to forecast financial risks. However, learning long behavior sequences is non-trivial for deep sequential models. Additionally, the diverse fields of payment behaviors carry rich information, requiring thorough exploitation. These factors collectively complicate the task of long-term user behavior modeling. To tackle these challenges, we propose a Long-term Payment Behavior Sequence Folding method, referred to as LBSF. In LBSF, payment behavior sequences are folded based on merchants, using the merchant field as an intrinsic grouping criterion, which enables informative parallelism without reliance on external knowledge. Meanwhile, we maximize the utility of payment details through a multi-field behavior encoding mechanism. Subsequently, behavior aggregation at the merchant level followed by relational learning across merchants facilitates comprehensive user financial representation. We evaluate LBSF on the financial risk assessment task using a large-scale real-world dataset. The results demonstrate that folding long behavior sequences based on internal behavioral cues effectively models long-term patterns and changes, thereby generating more accurate user financial profiles for practical applications.
MVOC: a training-free multiple video object composition method with diffusion models
Jun 22, 2024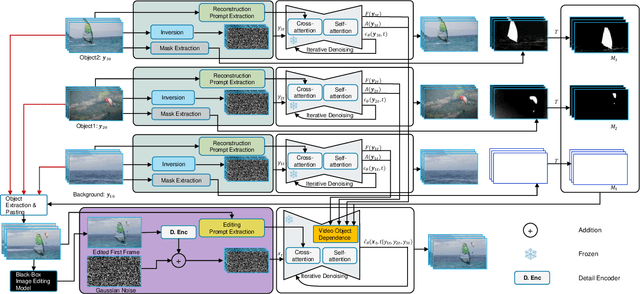
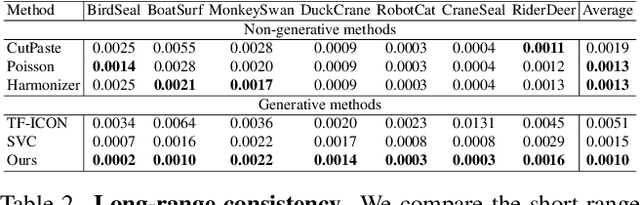
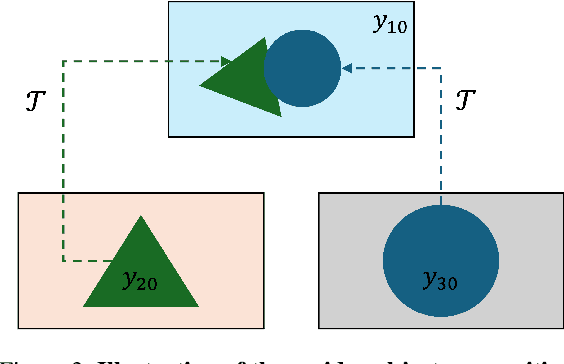

Video composition is the core task of video editing. Although image composition based on diffusion models has been highly successful, it is not straightforward to extend the achievement to video object composition tasks, which not only exhibit corresponding interaction effects but also ensure that the objects in the composited video maintain motion and identity consistency, which is necessary to composite a physical harmony video. To address this challenge, we propose a Multiple Video Object Composition (MVOC) method based on diffusion models. Specifically, we first perform DDIM inversion on each video object to obtain the corresponding noise features. Secondly, we combine and edit each object by image editing methods to obtain the first frame of the composited video. Finally, we use the image-to-video generation model to composite the video with feature and attention injections in the Video Object Dependence Module, which is a training-free conditional guidance operation for video generation, and enables the coordination of features and attention maps between various objects that can be non-independent in the composited video. The final generative model not only constrains the objects in the generated video to be consistent with the original object motion and identity, but also introduces interaction effects between objects. Extensive experiments have demonstrated that the proposed method outperforms existing state-of-the-art approaches. Project page: https://sobeymil.github.io/mvoc.com.
UPST-NeRF: Universal Photorealistic Style Transfer of Neural Radiance Fields for 3D Scene
Aug 21, 2022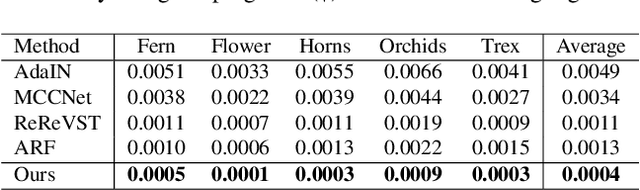
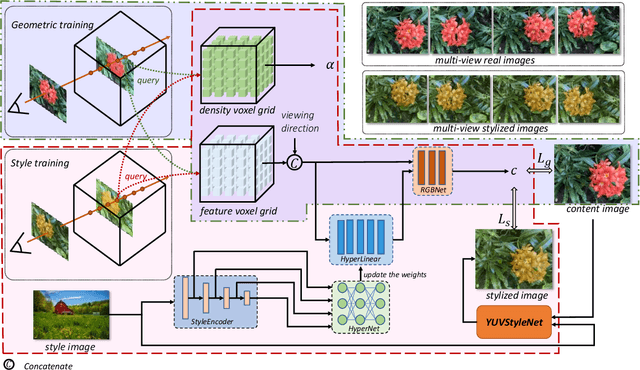
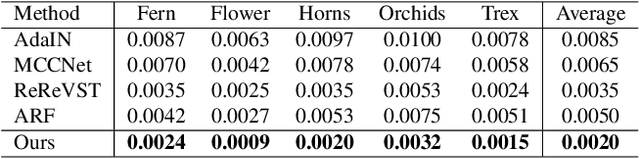
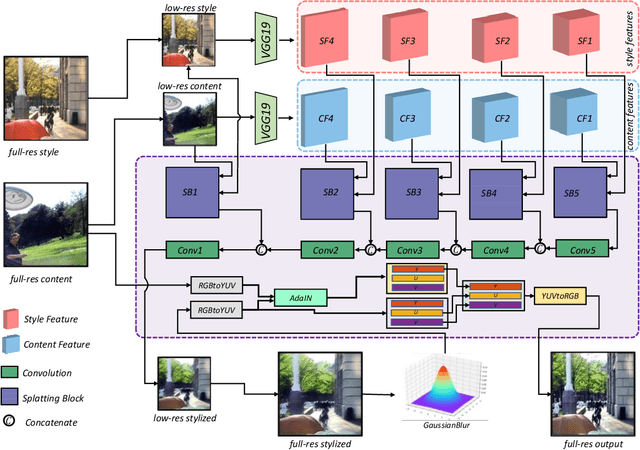
3D scenes photorealistic stylization aims to generate photorealistic images from arbitrary novel views according to a given style image while ensuring consistency when rendering from different viewpoints. Some existing stylization methods with neural radiance fields can effectively predict stylized scenes by combining the features of the style image with multi-view images to train 3D scenes. However, these methods generate novel view images that contain objectionable artifacts. Besides, they cannot achieve universal photorealistic stylization for a 3D scene. Therefore, a styling image must retrain a 3D scene representation network based on a neural radiation field. We propose a novel 3D scene photorealistic style transfer framework to address these issues. It can realize photorealistic 3D scene style transfer with a 2D style image. We first pre-trained a 2D photorealistic style transfer network, which can meet the photorealistic style transfer between any given content image and style image. Then, we use voxel features to optimize a 3D scene and get the geometric representation of the scene. Finally, we jointly optimize a hyper network to realize the scene photorealistic style transfer of arbitrary style images. In the transfer stage, we use a pre-trained 2D photorealistic network to constrain the photorealistic style of different views and different style images in the 3D scene. The experimental results show that our method not only realizes the 3D photorealistic style transfer of arbitrary style images but also outperforms the existing methods in terms of visual quality and consistency. Project page:https://semchan.github.io/UPST_NeRF.
Cross-ethnicity Face Anti-spoofing Recognition Challenge: A Review
Apr 23, 2020

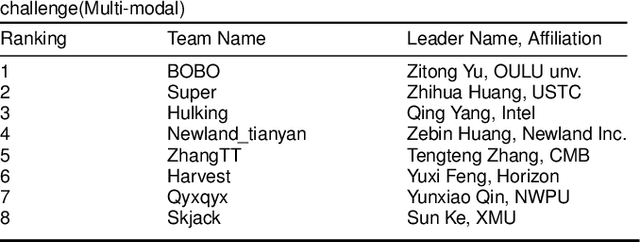
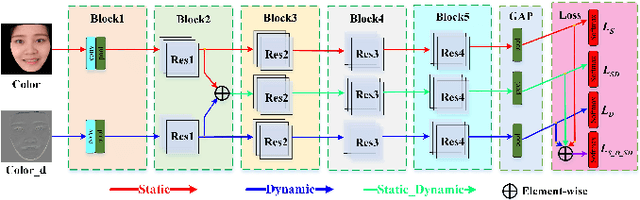
Face anti-spoofing is critical to prevent face recognition systems from a security breach. The biometrics community has %possessed achieved impressive progress recently due the excellent performance of deep neural networks and the availability of large datasets. Although ethnic bias has been verified to severely affect the performance of face recognition systems, it still remains an open research problem in face anti-spoofing. Recently, a multi-ethnic face anti-spoofing dataset, CASIA-SURF CeFA, has been released with the goal of measuring the ethnic bias. It is the largest up to date cross-ethnicity face anti-spoofing dataset covering $3$ ethnicities, $3$ modalities, $1,607$ subjects, 2D plus 3D attack types, and the first dataset including explicit ethnic labels among the recently released datasets for face anti-spoofing. We organized the Chalearn Face Anti-spoofing Attack Detection Challenge which consists of single-modal (e.g., RGB) and multi-modal (e.g., RGB, Depth, Infrared (IR)) tracks around this novel resource to boost research aiming to alleviate the ethnic bias. Both tracks have attracted $340$ teams in the development stage, and finally 11 and 8 teams have submitted their codes in the single-modal and multi-modal face anti-spoofing recognition challenges, respectively. All the results were verified and re-ran by the organizing team, and the results were used for the final ranking. This paper presents an overview of the challenge, including its design, evaluation protocol and a summary of results. We analyze the top ranked solutions and draw conclusions derived from the competition. In addition we outline future work directions.
A Single Shot Text Detector with Scale-adaptive Anchors
Jul 05, 2018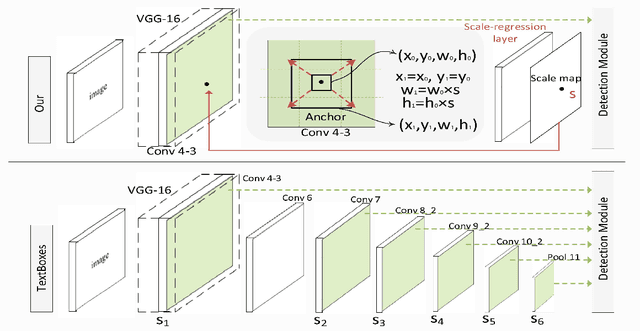

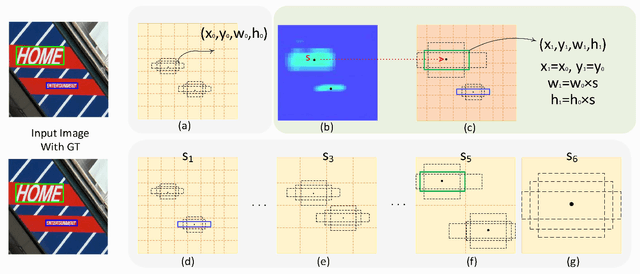
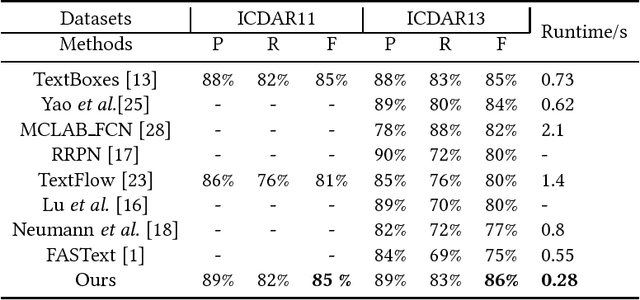
Currently, most top-performing text detection networks tend to employ fixed-size anchor boxes to guide the search for text instances. They usually rely on a large amount of anchors with different scales to discover texts in scene images, thus leading to high computational cost. In this paper, we propose an end-to-end box-based text detector with scale-adaptive anchors, which can dynamically adjust the scales of anchors according to the sizes of underlying texts by introducing an additional scale regression layer. The proposed scale-adaptive anchors allow us to use a few number of anchors to handle multi-scale texts and therefore significantly improve the computational efficiency. Moreover, compared to discrete scales used in previous methods, the learned continuous scales are more reliable, especially for small texts detection. Additionally, we propose Anchor convolution to better exploit necessary feature information by dynamically adjusting the sizes of receptive fields according to the learned scales. Extensive experiments demonstrate that the proposed detector is fast, taking only $0.28$ second per image, while outperforming most state-of-the-art methods in accuracy.