 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Theoretic Multi-Model Fusion for Target-Oriented Adaptive Sampling in Materials Design
Feb 03, 2026Target-oriented discovery under limited evaluation budgets requires making reliable progress in high-dimensional, heterogeneous design spaces where each new measurement is costly, whether experimental or high-fidelity simulation. We present an information-theoretic framework for target-oriented adaptive sampling that reframes optimization as trajectory discovery: instead of approximating the full response surface, the method maintains and refines a low-entropy information state that concentrates search on target-relevant directions. The approach couples data, model beliefs, and physics/structure priors through dimension-aware information budgeting, adaptive bootstrapped distillation over a heterogeneous surrogate reservoir, and structure-aware candidate manifold analysis with Kalman-inspired multi-model fusion to balance consensus-driven exploitation and disagreement-driven exploration. Evaluated under a single unified protocol without dataset-specific tuning, the framework improves sample efficiency and reliability across 14 single- and multi-objective materials design tasks spanning candidate pools from $600$ to $4 \times 10^6$ and feature dimensions from $10$ to $10^3$, typically reaching top-performing regions within 100 evaluations. Complementary 20-dimensional synthetic benchmarks (Ackley, Rastrigin, Schwefel) further demonstrate robustness to rugged and multimodal landscapes.
Hallucination Begins Where Saliency Drops
Jan 28, 2026Recent studies have examined attention dynamics in large vision-language models (LVLMs) to detect hallucinations. However, existing approaches remain limited in reliably distinguishing hallucinated from factually grounded outputs, as they rely solely on forward-pass attention patterns and neglect gradient-based signals that reveal how token influence propagates through the network. To bridge this gap, we introduce LVLMs-Saliency, a gradient-aware diagnostic framework that quantifies the visual grounding strength of each output token by fusing attention weights with their input gradients. Our analysis uncovers a decisive pattern: hallucinations frequently arise when preceding output tokens exhibit low saliency toward the prediction of the next token, signaling a breakdown in contextual memory retention. Leveraging this insight, we propose a dual-mechanism inference-time framework to mitigate hallucinations: (1) Saliency-Guided Rejection Sampling (SGRS), which dynamically filters candidate tokens during autoregressive decoding by rejecting those whose saliency falls below a context-adaptive threshold, thereby preventing coherence-breaking tokens from entering the output sequence; and (2) Local Coherence Reinforcement (LocoRE), a lightweight, plug-and-play module that strengthens attention from the current token to its most recent predecessors, actively counteracting the contextual forgetting behavior identified by LVLMs-Saliency. Extensive experiments across multiple LVLMs demonstrate that our method significantly reduces hallucination rates while preserving fluency and task performance, offering a robust and interpretable solution for enhancing model reliability. Code is available at: https://github.com/zhangbaijin/LVLMs-Saliency
Distribution-Aligned Sequence Distillation for Superior Long-CoT Reasoning
Jan 14, 2026In this report, we introduce DASD-4B-Thinking, a lightweight yet highly capable, fully open-source reasoning model. It achieves SOTA performance among open-source models of comparable scale across challenging benchmarks in mathematics, scientific reasoning, and code generation -- even outperforming several larger models. We begin by critically reexamining a widely adopted distillation paradigm in the community: SFT on teacher-generated responses, also known as sequence-level distillation. Although a series of recent works following this scheme have demonstrated remarkable efficiency and strong empirical performance, they are primarily grounded in the SFT perspective. Consequently, these approaches focus predominantly on designing heuristic rules for SFT data filtering, while largely overlooking the core principle of distillation itself -- enabling the student model to learn the teacher's full output distribution so as to inherit its generalization capability. Specifically, we identify three critical limitations in current practice: i) Inadequate representation of the teacher's sequence-level distribution; ii) Misalignment between the teacher's output distribution and the student's learning capacity; and iii) Exposure bias arising from teacher-forced training versus autoregressive inference. In summary, these shortcomings reflect a systemic absence of explicit teacher-student interaction throughout the distillation process, leaving the essence of distillation underexploited. To address these issues, we propose several methodological innovations that collectively form an enhanced sequence-level distillation training pipeline. Remarkably, DASD-4B-Thinking obtains competitive results using only 448K training samples -- an order of magnitude fewer than those employed by most existing open-source efforts. To support community research, we publicly release our models and the training dataset.
Bootstrapping Code Translation with Weighted Multilanguage Exploration
Jan 07, 2026Code translation across multiple programming languages is essential yet challenging due to two vital obstacles: scarcity of parallel data paired with executable test oracles, and optimization imbalance when handling diverse language pairs. We propose BootTrans, a bootstrapping method that resolves both obstacles. Its key idea is to leverage the functional invariance and cross-lingual portability of test suites, adapting abundant pivot-language unit tests to serve as universal verification oracles for multilingual RL training. Our method introduces a dual-pool architecture with seed and exploration pools to progressively expand training data via execution-guided experience collection. Furthermore, we design a language-aware weighting mechanism that dynamically prioritizes harder translation directions based on relative performance across sibling languages, mitigating optimization imbalance. Extensive experiments on the HumanEval-X and TransCoder-Test benchmarks demonstrate substantial improvements over baseline LLMs across all translation directions, with ablations validating the effectiveness of both bootstrapping and weighting components.
Where Did This Sentence Come From? Tracing Provenance in LLM Reasoning Distillation
Dec 24, 2025Reasoning distillation has attracted increasing attention. It typically leverages a large teacher model to generate reasoning paths, which are then used to fine-tune a student model so that it mimics the teacher's behavior in training contexts. However, previous approaches have lacked a detailed analysis of the origins of the distilled model's capabilities. It remains unclear whether the student can maintain consistent behaviors with the teacher in novel test-time contexts, or whether it regresses to its original output patterns, raising concerns about the generalization of distillation models. To analyse this question, we introduce a cross-model Reasoning Distillation Provenance Tracing framework. For each action (e.g., a sentence) produced by the distilled model, we obtain the predictive probabilities assigned by the teacher, the original student, and the distilled model under the same context. By comparing these probabilities, we classify each action into different categories. By systematically disentangling the provenance of each action, we experimentally demonstrate that, in test-time contexts, the distilled model can indeed generate teacher-originated actions, which correlate with and plausibly explain observed performance on distilled model. Building on this analysis, we further propose a teacher-guided data selection method. Unlike prior approach that rely on heuristics, our method directly compares teacher-student divergences on the training data, providing a principled selection criterion. We validate the effectiveness of our approach across multiple representative teacher models and diverse student models. The results highlight the utility of our provenance-tracing framework and underscore its promise for reasoning distillation. We hope to share Reasoning Distillation Provenance Tracing and our insights into reasoning distillation with the community.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
FEAT: A Multi-Agent Forensic AI System with Domain-Adapted Large Language Model for Automated Cause-of-Death Analysis
Aug 11, 2025Forensic cause-of-death determination faces systemic challenges, including workforce shortages and diagnostic variability, particularly in high-volume systems like China's medicolegal infrastructure. We introduce FEAT (ForEnsic AgenT), a multi-agent AI framework that automates and standardizes death investigations through a domain-adapted large language model. FEAT's application-oriented architecture integrates: (i) a central Planner for task decomposition, (ii) specialized Local Solvers for evidence analysis, (iii) a Memory & Reflection module for iterative refinement, and (iv) a Global Solver for conclusion synthesis. The system employs tool-augmented reasoning, hierarchical retrieval-augmented generation, forensic-tuned LLMs, and human-in-the-loop feedback to ensure legal and medical validity. In evaluations across diverse Chinese case cohorts, FEAT outperformed state-of-the-art AI systems in both long-form autopsy analyses and concise cause-of-death conclusions. It demonstrated robust generalization across six geographic regions and achieved high expert concordance in blinded validations. Senior pathologists validated FEAT's outputs as comparable to those of human experts, with improved detection of subtle evidentiary nuances. To our knowledge, FEAT is the first LLM-based AI agent system dedicated to forensic medicine, offering scalable, consistent death certification while maintaining expert-level rigor. By integrating AI efficiency with human oversight, this work could advance equitable access to reliable medicolegal services while addressing critical capacity constraints in forensic systems.
Towards Probabilistic Question Answering Over Tabular Data
Jun 25, 2025Current approaches for question answering (QA) over tabular data, such as NL2SQL systems, perform well for factual questions where answers are directly retrieved from tables. However, they fall short on probabilistic questions requiring reasoning under uncertainty. In this paper, we introduce a new benchmark LUCARIO and a framework for probabilistic QA over large tabular data. Our method induces Bayesian Networks from tables, translates natural language queries into probabilistic queries, and uses large language models (LLMs) to generate final answers. Empirical results demonstrate significant improvements over baselines, highlighting the benefits of hybrid symbolic-neural reasoning.
Efficient Reasoning Through Suppression of Self-Affirmation Reflections in Large Reasoning Models
Jun 14, 2025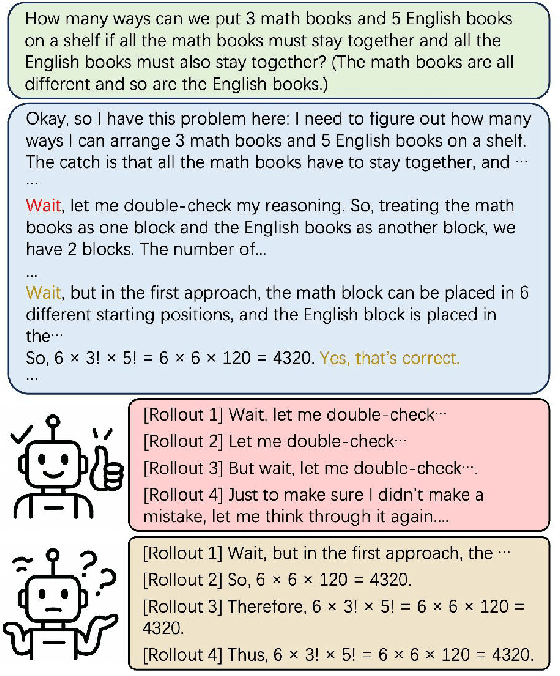
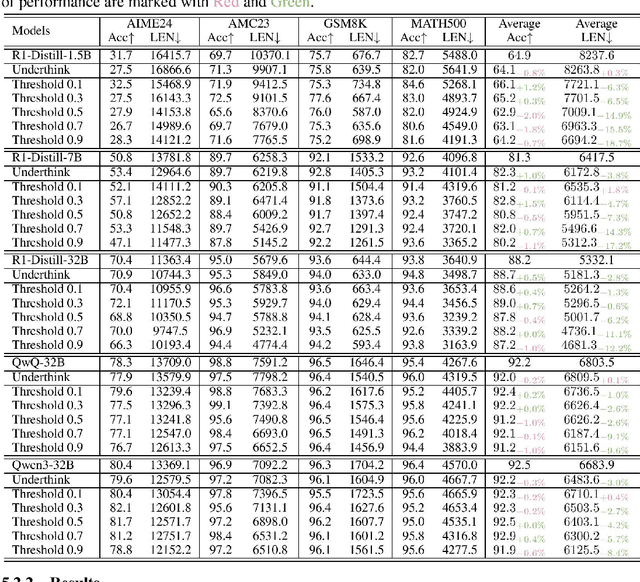
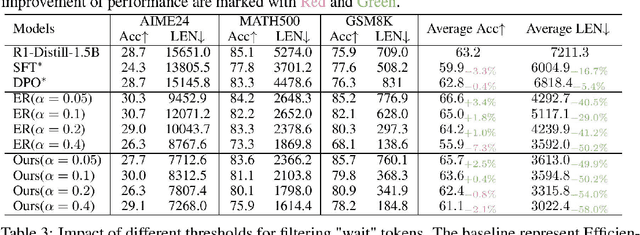
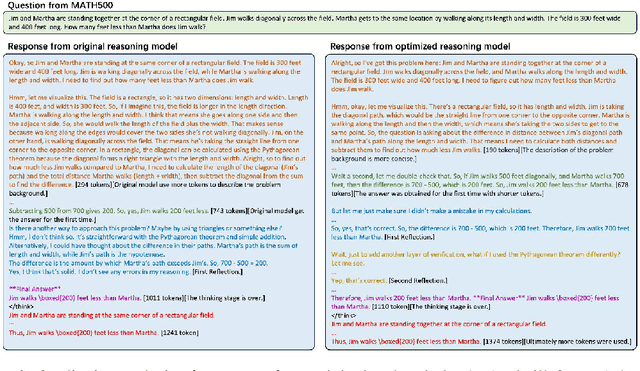
While recent advances in large reasoning models have demonstrated remarkable performance, efficient reasoning remains critical due to the rapid growth of output length. Existing optimization approaches highlights a tendency toward "overthinking", yet lack fine-grained analysis. In this work, we focus on Self-Affirmation Reflections: redundant reflective steps that affirm prior content and often occurs after the already correct reasoning steps. Observations of both original and optimized reasoning models reveal pervasive self-affirmation reflections. Notably, these reflections sometimes lead to longer outputs in optimized models than their original counterparts. Through detailed analysis, we uncover an intriguing pattern: compared to other reflections, the leading words (i.e., the first word of sentences) in self-affirmation reflections exhibit a distinct probability bias. Motivated by this insight, we can locate self-affirmation reflections and conduct a train-free experiment demonstrating that suppressing self-affirmation reflections reduces output length without degrading accuracy across multiple models (R1-Distill-Models, QwQ-32B, and Qwen3-32B). Furthermore, we also improve current train-based method by explicitly suppressing such reflections. In our experiments, we achieve length compression of 18.7\% in train-free settings and 50.2\% in train-based settings for R1-Distill-Qwen-1.5B. Moreover, our improvements are simple yet practical and can be directly applied to existing inference frameworks, such as vLLM. We believe that our findings will provide community insights for achieving more precise length compression and step-level efficient reasoning.
GeoCAD: Local Geometry-Controllable CAD Generation
Jun 12, 2025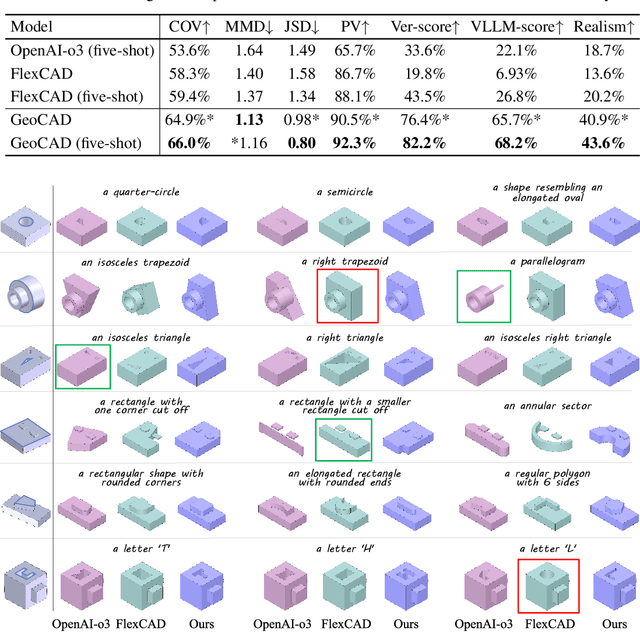
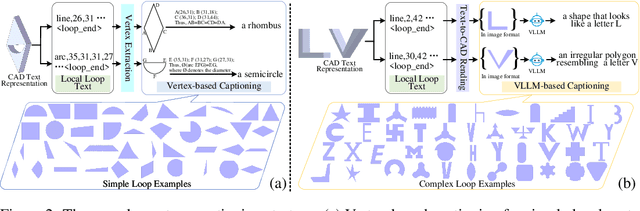
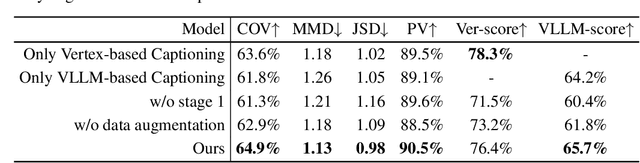

Local geometry-controllable computer-aided design (CAD) generation aims to modify local parts of CAD models automatically, enhancing design efficiency. It also ensures that the shapes of newly generated local parts follow user-specific geometric instructions (e.g., an isosceles right triangle or a rectangle with one corner cut off). However, existing methods encounter challenges in achieving this goal. Specifically, they either lack the ability to follow textual instructions or are unable to focus on the local parts. To address this limitation, we introduce GeoCAD, a user-friendly and local geometry-controllable CAD generation method. Specifically, we first propose a complementary captioning strategy to generate geometric instructions for local parts. This strategy involves vertex-based and VLLM-based captioning for systematically annotating simple and complex parts, respectively. In this way, we caption $\sim$221k different local parts in total. In the training stage, given a CAD model, we randomly mask a local part. Then, using its geometric instruction and the remaining parts as input, we prompt large language models (LLMs) to predict the masked part. During inference, users can specify any local part for modification while adhering to a variety of predefined geometric instructions. Extensive experiments demonstrate the effectiveness of GeoCAD in generation quality, validity and text-to-CAD consistency. Code will be available at https://github.com/Zhanwei-Z/GeoCAD.