 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Healthcare System Visitation Flow by Integrating Hospital Attributes and Population Socioeconomics with Human Mobility Data
Jan 22, 2026Healthcare visitation patterns are influenced by a complex interplay of hospital attributes, population socioeconomics, and spatial factors. However, existing research often adopts a fragmented approach, examining these determinants in isolation. This study addresses this gap by integrating hospital capacities, occupancy rates, reputation, and popularity with population SES and spatial mobility patterns to predict visitation flows and analyze influencing factors. Utilizing four years of SafeGraph mobility data and user experience data from Google Maps Reviews, five flow prediction models, Naive Regression, Gradient Boosting, Multilayer Perceptrons (MLPs), Deep Gravity, and Heterogeneous Graph Neural Networks (HGNN),were trained and applied to simulate visitation flows in Houston, Texas, U.S. The Shapley additive explanation (SHAP) analysis and the Partial Dependence Plot (PDP) method were employed to examine the combined impacts of different factors on visitation patterns. The findings reveal that Deep Gravity outperformed other models. Hospital capacities, ICU occupancy rates, ratings, and popularity significantly influence visitation patterns, with their effects varying across different travel distances. Short-distance visits are primarily driven by convenience, whereas long-distance visits are influenced by hospital ratings. White-majority areas exhibited lower sensitivity to hospital ratings for short-distance visits, while Asian populations and those with higher education levels prioritized hospital rating in their visitation decisions. SES further influence these patterns, as areas with higher proportions of Hispanic, Black, under-18, and over-65 populations tend to have more frequent hospital visits, potentially reflecting greater healthcare needs or limited access to alternative medical services.
TokenSqueeze: Performance-Preserving Compression for Reasoning LLMs
Nov 17, 2025Emerging reasoning LLMs such as OpenAI-o1 and DeepSeek-R1 have achieved strong performance on complex reasoning tasks by generating long chain-of-thought (CoT) traces. However, these long CoTs result in increased token usage, leading to higher inference latency and memory consumption. As a result, balancing accuracy and reasoning efficiency has become essential for deploying reasoning LLMs in practical applications. Existing long-to-short (Long2Short) methods aim to reduce inference length but often sacrifice accuracy, revealing a need for an approach that maintains performance while lowering token costs. To address this efficiency-accuracy tradeoff, we propose TokenSqueeze, a novel Long2Short method that condenses reasoning paths while preserving performance and relying exclusively on self-generated data. First, to prevent performance degradation caused by excessive compression of reasoning depth, we propose to select self-generated samples whose reasoning depth is adaptively matched to the complexity of the problem. To further optimize the linguistic expression without altering the underlying reasoning paths, we introduce a distribution-aligned linguistic refinement method that enhances the clarity and conciseness of the reasoning path while preserving its logical integrity. Comprehensive experimental results demonstrate the effectiveness of TokenSqueeze in reducing token usage while maintaining accuracy. Notably, DeepSeek-R1-Distill-Qwen-7B fine-tuned using our proposed method achieved a 50\% average token reduction while preserving accuracy on the MATH500 benchmark. TokenSqueeze exclusively utilizes the model's self-generated data, enabling efficient and high-fidelity reasoning without relying on manually curated short-answer datasets across diverse applications. Our code is available at https://github.com/zhangyx1122/TokenSqueeze.
Enhancing Spatial Reasoning through Visual and Textual Thinking
Jul 28, 2025The spatial reasoning task aims to reason about the spatial relationships in 2D and 3D space, which is a fundamental capability for Visual Question Answering (VQA) and robotics. Although vision language models (VLMs) have developed rapidly in recent years, they are still struggling with the spatial reasoning task. In this paper, we introduce a method that can enhance Spatial reasoning through Visual and Textual thinking Simultaneously (SpatialVTS). In the spatial visual thinking phase, our model is trained to generate location-related specific tokens of essential targets automatically. Not only are the objects mentioned in the problem addressed, but also the potential objects related to the reasoning are considered. During the spatial textual thinking phase, Our model conducts long-term thinking based on visual cues and dialogues, gradually inferring the answers to spatial reasoning problems. To effectively support the model's training, we perform manual corrections to the existing spatial reasoning dataset, eliminating numerous incorrect labels resulting from automatic annotation, restructuring the data input format to enhance generalization ability, and developing thinking processes with logical reasoning details. Without introducing additional information (such as masks or depth), our model's overall average level in several spatial understanding tasks has significantly improved compared with other models.
CheMatAgent: Enhancing LLMs for Chemistry and Materials Science through Tree-Search Based Tool Learning
Jun 12, 2025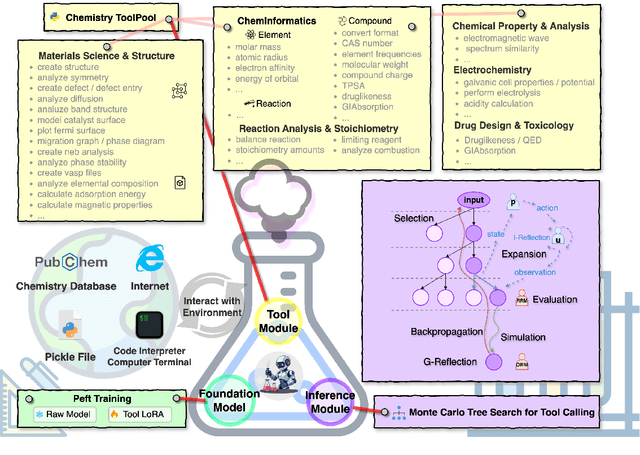
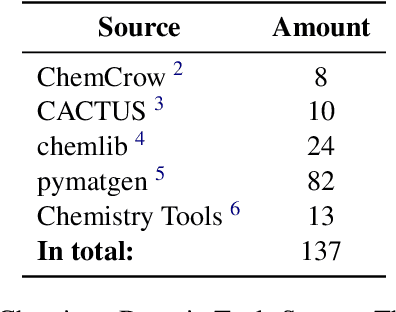
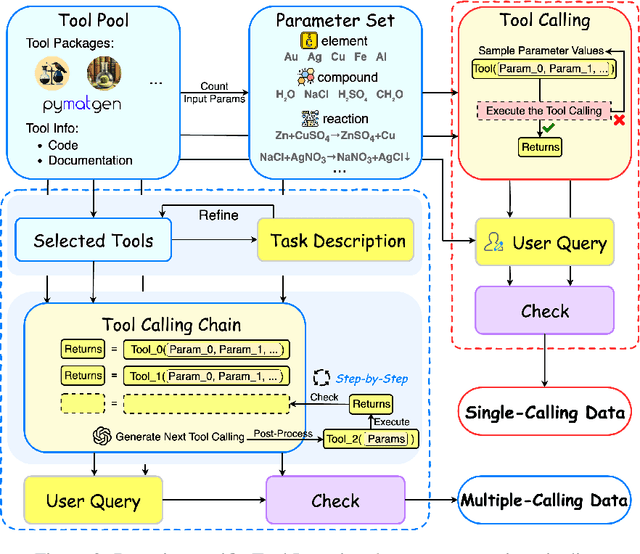
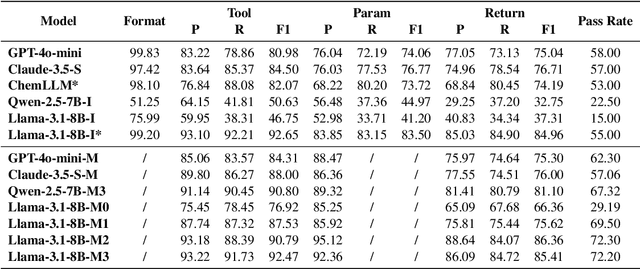
Large language models (LLMs) have recently demonstrated promising capabilities in chemistry tasks while still facing challenges due to outdated pretraining knowledge and the difficulty of incorporating specialized chemical expertise. To address these issues, we propose an LLM-based agent that synergistically integrates 137 external chemical tools created ranging from basic information retrieval to complex reaction predictions, and a dataset curation pipeline to generate the dataset ChemToolBench that facilitates both effective tool selection and precise parameter filling during fine-tuning and evaluation. We introduce a Hierarchical Evolutionary Monte Carlo Tree Search (HE-MCTS) framework, enabling independent optimization of tool planning and execution. By leveraging self-generated data, our approach supports step-level fine-tuning (FT) of the policy model and training task-adaptive PRM and ORM that surpass GPT-4o. Experimental evaluations demonstrate that our approach significantly improves performance in Chemistry QA and discovery tasks, offering a robust solution to integrate specialized tools with LLMs for advanced chemical applications. All datasets and code are available at https://github.com/AI4Chem/ChemistryAgent .
GeoCAD: Local Geometry-Controllable CAD Generation
Jun 12, 2025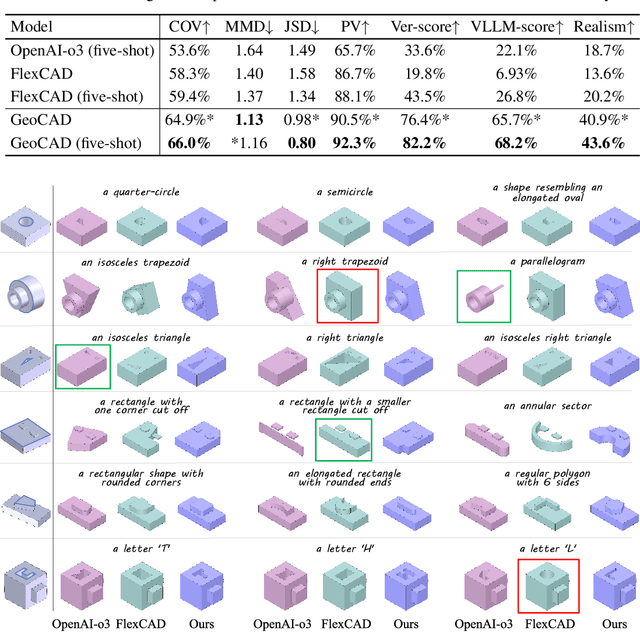
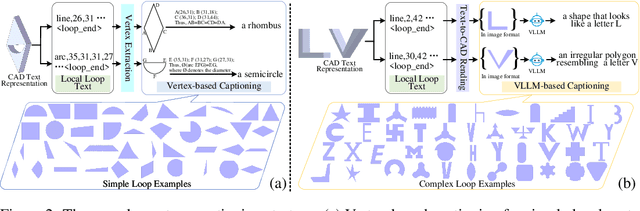
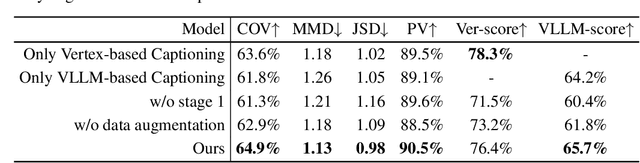

Local geometry-controllable computer-aided design (CAD) generation aims to modify local parts of CAD models automatically, enhancing design efficiency. It also ensures that the shapes of newly generated local parts follow user-specific geometric instructions (e.g., an isosceles right triangle or a rectangle with one corner cut off). However, existing methods encounter challenges in achieving this goal. Specifically, they either lack the ability to follow textual instructions or are unable to focus on the local parts. To address this limitation, we introduce GeoCAD, a user-friendly and local geometry-controllable CAD generation method. Specifically, we first propose a complementary captioning strategy to generate geometric instructions for local parts. This strategy involves vertex-based and VLLM-based captioning for systematically annotating simple and complex parts, respectively. In this way, we caption $\sim$221k different local parts in total. In the training stage, given a CAD model, we randomly mask a local part. Then, using its geometric instruction and the remaining parts as input, we prompt large language models (LLMs) to predict the masked part. During inference, users can specify any local part for modification while adhering to a variety of predefined geometric instructions. Extensive experiments demonstrate the effectiveness of GeoCAD in generation quality, validity and text-to-CAD consistency. Code will be available at https://github.com/Zhanwei-Z/GeoCAD.
ChemAgent: Enhancing LLMs for Chemistry and Materials Science through Tree-Search Based Tool Learning
Jun 09, 2025Large language models (LLMs) have recently demonstrated promising capabilities in chemistry tasks while still facing challenges due to outdated pretraining knowledge and the difficulty of incorporating specialized chemical expertise. To address these issues, we propose an LLM-based agent that synergistically integrates 137 external chemical tools created ranging from basic information retrieval to complex reaction predictions, and a dataset curation pipeline to generate the dataset ChemToolBench that facilitates both effective tool selection and precise parameter filling during fine-tuning and evaluation. We introduce a Hierarchical Evolutionary Monte Carlo Tree Search (HE-MCTS) framework, enabling independent optimization of tool planning and execution. By leveraging self-generated data, our approach supports step-level fine-tuning (FT) of the policy model and training task-adaptive PRM and ORM that surpass GPT-4o. Experimental evaluations demonstrate that our approach significantly improves performance in Chemistry QA and discovery tasks, offering a robust solution to integrate specialized tools with LLMs for advanced chemical applications. All datasets and code are available at https://github.com/AI4Chem/ChemistryAgent .
Beyond Templates: Dynamic Adaptation of Reasoning Demonstrations via Feasibility-Aware Exploration
May 27, 2025Large language models (LLMs) have shown remarkable reasoning capabilities, yet aligning such abilities to small language models (SLMs) remains a challenge due to distributional mismatches and limited model capacity. Existing reasoning datasets, typically designed for powerful LLMs, often lead to degraded performance when directly applied to weaker models. In this work, we introduce Dynamic Adaptation of Reasoning Trajectories (DART), a novel data adaptation framework that bridges the capability gap between expert reasoning trajectories and diverse SLMs. Instead of uniformly imitating expert steps, DART employs a selective imitation strategy guided by step-wise adaptability estimation via solution simulation. When expert steps surpass the student's capacity -- signaled by an Imitation Gap -- the student autonomously explores alternative reasoning paths, constrained by outcome consistency. We validate DART across multiple reasoning benchmarks and model scales, demonstrating that it significantly improves generalization and data efficiency over static fine-tuning. Our method enhances supervision quality by aligning training signals with the student's reasoning capabilities, offering a scalable solution for reasoning alignment in resource-constrained models.
Hyperlocal disaster damage assessment using bi-temporal street-view imagery and pre-trained vision models
Apr 12, 2025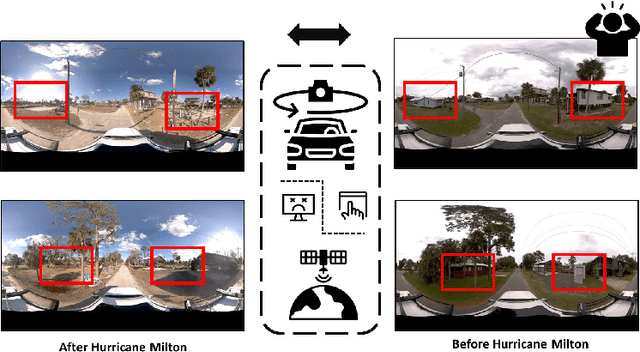
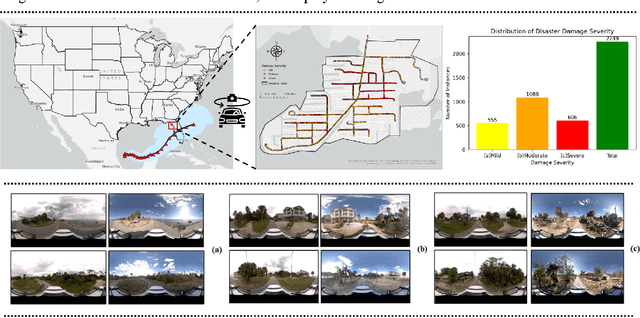
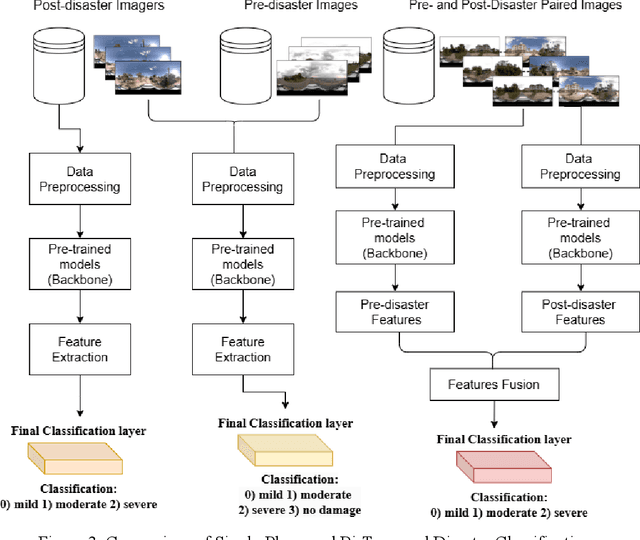
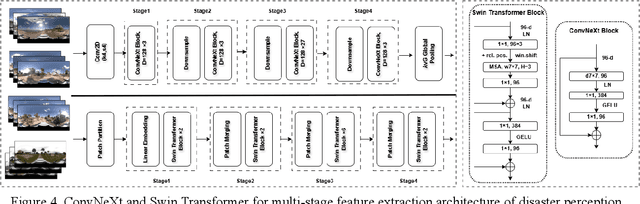
Street-view images offer unique advantages for disaster damage estimation as they capture impacts from a visual perspective and provide detailed, on-the-ground insights. Despite several investigations attempting to analyze street-view images for damage estimation, they mainly focus on post-disaster images. The potential of time-series street-view images remains underexplored. Pre-disaster images provide valuable benchmarks for accurate damage estimations at building and street levels. These images could aid annotators in objectively labeling post-disaster impacts, improving the reliability of labeled data sets for model training, and potentially enhancing the model performance in damage evaluation. The goal of this study is to estimate hyperlocal, on-the-ground disaster damages using bi-temporal street-view images and advanced pre-trained vision models. Street-view images before and after 2024 Hurricane Milton in Horseshoe Beach, Florida, were collected for experiments. The objectives are: (1) to assess the performance gains of incorporating pre-disaster street-view images as a no-damage category in fine-tuning pre-trained models, including Swin Transformer and ConvNeXt, for damage level classification; (2) to design and evaluate a dual-channel algorithm that reads pair-wise pre- and post-disaster street-view images for hyperlocal damage assessment. The results indicate that incorporating pre-disaster street-view images and employing a dual-channel processing framework can significantly enhance damage assessment accuracy. The accuracy improves from 66.14% with the Swin Transformer baseline to 77.11% with the dual-channel Feature-Fusion ConvNeXt model. This research enables rapid, operational damage assessments at hyperlocal spatial resolutions, providing valuable insights to support effective decision-making in disaster management and resilience planning.
Toward building next-generation Geocoding systems: a systematic review
Mar 24, 2025Geocoding systems are widely used in both scientific research for spatial analysis and everyday life through location-based services. The quality of geocoded data significantly impacts subsequent processes and applications, underscoring the need for next-generation systems. In response to this demand, this review first examines the evolving requirements for geocoding inputs and outputs across various scenarios these systems must address. It then provides a detailed analysis of how to construct such systems by breaking them down into key functional components and reviewing a broad spectrum of existing approaches, from traditional rule-based methods to advanced techniques in information retrieval, natural language processing, and large language models. Finally, we identify opportunities to improve next-generation geocoding systems in light of recent technological advances.
InsQABench: Benchmarking Chinese Insurance Domain Question Answering with Large Language Models
Jan 19, 2025The application of large language models (LLMs) has achieved remarkable success in various fields, but their effectiveness in specialized domains like the Chinese insurance industry remains underexplored. The complexity of insurance knowledge, encompassing specialized terminology and diverse data types, poses significant challenges for both models and users. To address this, we introduce InsQABench, a benchmark dataset for the Chinese insurance sector, structured into three categories: Insurance Commonsense Knowledge, Insurance Structured Database, and Insurance Unstructured Documents, reflecting real-world insurance question-answering tasks.We also propose two methods, SQL-ReAct and RAG-ReAct, to tackle challenges in structured and unstructured data tasks. Evaluations show that while LLMs struggle with domain-specific terminology and nuanced clause texts, fine-tuning on InsQABench significantly improves performance. Our benchmark establishes a solid foundation for advancing LLM applications in the insurance domain, with data and code available at https://github.com/HaileyFamo/InsQABench.git.