 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multiple Dimensions of Trustworthiness in LLMs via Sparse Activation Control
Nov 04, 2024



As the development and application of Large Language Models (LLMs) continue to advance rapidly, enhancing their trustworthiness and aligning them with human preferences has become a critical area of research. Traditional methods rely heavily on extensive data for Reinforcement Learning from Human Feedback (RLHF), but representation engineering offers a new, training-free approach. This technique leverages semantic features to control the representation of LLM's intermediate hidden states, enabling the model to meet specific requirements such as increased honesty or heightened safety awareness. However, a significant challenge arises when attempting to fulfill multiple requirements simultaneously. It proves difficult to encode various semantic contents, like honesty and safety, into a singular semantic feature, restricting its practicality. In this work, we address this issue through ``Sparse Activation Control''. By delving into the intrinsic mechanisms of LLMs, we manage to identify and pinpoint components that are closely related to specific tasks within the model, i.e., attention heads. These heads display sparse characteristics that allow for near-independent control over different tasks. Our experiments, conducted on the open-source Llama series models, have yielded encouraging results. The models were able to align with human preferences on issues of safety, factuality, and bias concurrently.
Interpreting and Improving Large Language Models in Arithmetic Calculation
Sep 03, 2024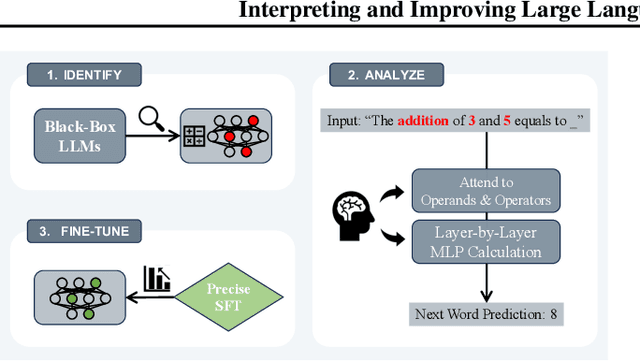
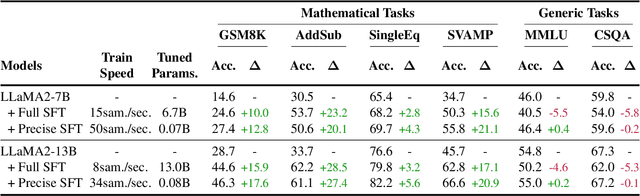
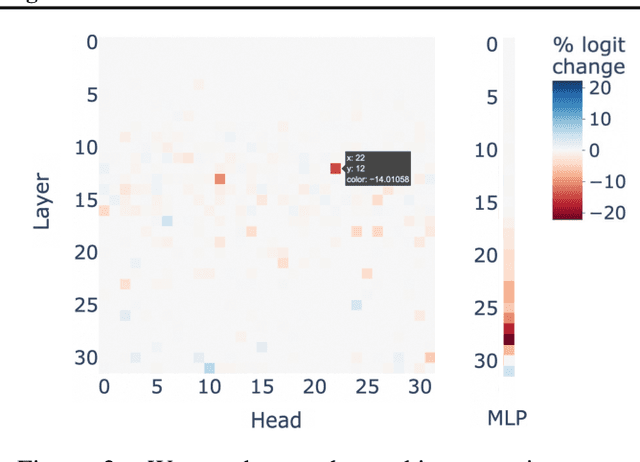
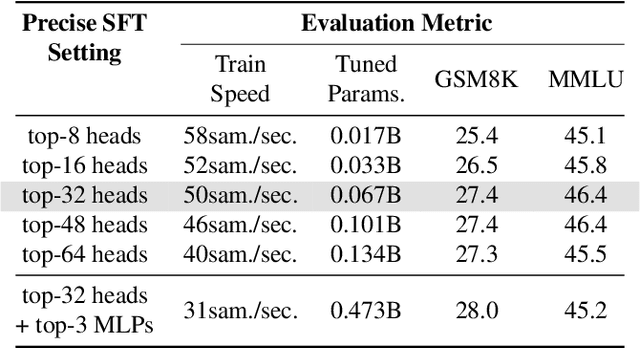
Large language models (LLMs) have demonstrated remarkable potential across numerous applications and have shown an emergent ability to tackle complex reasoning tasks, such as mathematical computations. However, even for the simplest arithmetic calculations, the intrinsic mechanisms behind LLMs remain mysterious, making it challenging to ensure reliability. In this work, we delve into uncovering a specific mechanism by which LLMs execute calculations. Through comprehensive experiments, we find that LLMs frequently involve a small fraction (< 5%) of attention heads, which play a pivotal role in focusing on operands and operators during calculation processes. Subsequently, the information from these operands is processed through multi-layer perceptrons (MLPs), progressively leading to the final solution. These pivotal heads/MLPs, though identified on a specific dataset, exhibit transferability across different datasets and even distinct tasks. This insight prompted us to investigate the potential benefits of selectively fine-tuning these essential heads/MLPs to boost the LLMs' computational performance. We empirically find that such precise tuning can yield notable enhancements on mathematical prowess, without compromising the performance on non-mathematical tasks. Our work serves as a preliminary exploration into the arithmetic calculation abilities inherent in LLMs, laying a solid foundation to reveal more intricate mathematical tasks.