 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKScope: A Framework for Characterizing the Knowledge Status of Language Models
Jun 09, 2025Characterizing a large language model's (LLM's) knowledge of a given question is challenging. As a result, prior work has primarily examined LLM behavior under knowledge conflicts, where the model's internal parametric memory contradicts information in the external context. However, this does not fully reflect how well the model knows the answer to the question. In this paper, we first introduce a taxonomy of five knowledge statuses based on the consistency and correctness of LLM knowledge modes. We then propose KScope, a hierarchical framework of statistical tests that progressively refines hypotheses about knowledge modes and characterizes LLM knowledge into one of these five statuses. We apply KScope to nine LLMs across four datasets and systematically establish: (1) Supporting context narrows knowledge gaps across models. (2) Context features related to difficulty, relevance, and familiarity drive successful knowledge updates. (3) LLMs exhibit similar feature preferences when partially correct or conflicted, but diverge sharply when consistently wrong. (4) Context summarization constrained by our feature analysis, together with enhanced credibility, further improves update effectiveness and generalizes across LLMs.
When Style Breaks Safety: Defending Language Models Against Superficial Style Alignment
Jun 09, 2025Large language models (LLMs) can be prompted with specific styles (e.g., formatting responses as lists), including in jailbreak queries. Although these style patterns are semantically unrelated to the malicious intents behind jailbreak queries, their safety impact remains unclear. In this work, we seek to understand whether style patterns compromise LLM safety, how superficial style alignment increases model vulnerability, and how best to mitigate these risks during alignment. We evaluate 32 LLMs across seven jailbreak benchmarks, and find that malicious queries with style patterns inflate the attack success rate (ASR) for nearly all models. Notably, ASR inflation correlates with both the length of style patterns and the relative attention an LLM exhibits on them. We then investigate superficial style alignment, and find that fine-tuning with specific styles makes LLMs more vulnerable to jailbreaks of those same styles. Finally, we propose SafeStyle, a defense strategy that incorporates a small amount of safety training data augmented to match the distribution of style patterns in the fine-tuning data. Across three LLMs and five fine-tuning style settings, SafeStyle consistently outperforms baselines in maintaining LLM safety.
MedBrowseComp: Benchmarking Medical Deep Research and Computer Use
May 20, 2025Large language models (LLMs) are increasingly envisioned as decision-support tools in clinical practice, yet safe clinical reasoning demands integrating heterogeneous knowledge bases -- trials, primary studies, regulatory documents, and cost data -- under strict accuracy constraints. Existing evaluations often rely on synthetic prompts, reduce the task to single-hop factoid queries, or conflate reasoning with open-ended generation, leaving their real-world utility unclear. To close this gap, we present MedBrowseComp, the first benchmark that systematically tests an agent's ability to reliably retrieve and synthesize multi-hop medical facts from live, domain-specific knowledge bases. MedBrowseComp contains more than 1,000 human-curated questions that mirror clinical scenarios where practitioners must reconcile fragmented or conflicting information to reach an up-to-date conclusion. Applying MedBrowseComp to frontier agentic systems reveals performance shortfalls as low as ten percent, exposing a critical gap between current LLM capabilities and the rigor demanded in clinical settings. MedBrowseComp therefore offers a clear testbed for reliable medical information seeking and sets concrete goals for future model and toolchain upgrades. You can visit our project page at: https://moreirap12.github.io/mbc-browse-app/
Speak Easy: Eliciting Harmful Jailbreaks from LLMs with Simple Interactions
Feb 06, 2025



Despite extensive safety alignment efforts, large language models (LLMs) remain vulnerable to jailbreak attacks that elicit harmful behavior. While existing studies predominantly focus on attack methods that require technical expertise, two critical questions remain underexplored: (1) Are jailbroken responses truly useful in enabling average users to carry out harmful actions? (2) Do safety vulnerabilities exist in more common, simple human-LLM interactions? In this paper, we demonstrate that LLM responses most effectively facilitate harmful actions when they are both actionable and informative--two attributes easily elicited in multi-step, multilingual interactions. Using this insight, we propose HarmScore, a jailbreak metric that measures how effectively an LLM response enables harmful actions, and Speak Easy, a simple multi-step, multilingual attack framework. Notably, by incorporating Speak Easy into direct request and jailbreak baselines, we see an average absolute increase of 0.319 in Attack Success Rate and 0.426 in HarmScore in both open-source and proprietary LLMs across four safety benchmarks. Our work reveals a critical yet often overlooked vulnerability: Malicious users can easily exploit common interaction patterns for harmful intentions.
Enhancing Multiple Dimensions of Trustworthiness in LLMs via Sparse Activation Control
Nov 04, 2024



As the development and application of Large Language Models (LLMs) continue to advance rapidly, enhancing their trustworthiness and aligning them with human preferences has become a critical area of research. Traditional methods rely heavily on extensive data for Reinforcement Learning from Human Feedback (RLHF), but representation engineering offers a new, training-free approach. This technique leverages semantic features to control the representation of LLM's intermediate hidden states, enabling the model to meet specific requirements such as increased honesty or heightened safety awareness. However, a significant challenge arises when attempting to fulfill multiple requirements simultaneously. It proves difficult to encode various semantic contents, like honesty and safety, into a singular semantic feature, restricting its practicality. In this work, we address this issue through ``Sparse Activation Control''. By delving into the intrinsic mechanisms of LLMs, we manage to identify and pinpoint components that are closely related to specific tasks within the model, i.e., attention heads. These heads display sparse characteristics that allow for near-independent control over different tasks. Our experiments, conducted on the open-source Llama series models, have yielded encouraging results. The models were able to align with human preferences on issues of safety, factuality, and bias concurrently.
SFTMix: Elevating Language Model Instruction Tuning with Mixup Recipe
Oct 07, 2024



To induce desired behaviors in large language models (LLMs) for interaction-driven tasks, the instruction-tuning stage typically trains LLMs on instruction-response pairs using the next-token prediction (NTP) loss. Previous work aiming to improve instruction-tuning performance often emphasizes the need for higher-quality supervised fine-tuning (SFT) datasets, which typically involves expensive data filtering with proprietary LLMs or labor-intensive data generation by human annotators. However, these approaches do not fully leverage the datasets' intrinsic properties, resulting in high computational and labor costs, thereby limiting scalability and performance gains. In this paper, we propose SFTMix, a novel recipe that elevates instruction-tuning performance beyond the conventional NTP paradigm, without the need for well-curated datasets. Observing that LLMs exhibit uneven confidence across the semantic representation space, we argue that examples with different confidence levels should play distinct roles during the instruction-tuning process. Based on this insight, SFTMix leverages training dynamics to identify examples with varying confidence levels, then applies a Mixup-based regularization to mitigate overfitting on confident examples while propagating supervision signals to improve learning on relatively unconfident ones. This approach enables SFTMix to significantly outperform NTP across a wide range of instruction-following and healthcare domain-specific SFT tasks, demonstrating its adaptability to diverse LLM families and scalability to datasets of any size. Comprehensive ablation studies further verify the robustness of SFTMix's design choices, underscoring its versatility in consistently enhancing performance across different LLMs and datasets in broader natural language processing applications.
In the Name of Fairness: Assessing the Bias in Clinical Record De-identification
May 18, 2023Data sharing is crucial for open science and reproducible research, but the legal sharing of clinical data requires the removal of protected health information from electronic health records. This process, known as de-identification, is often achieved through the use of machine learning algorithms by many commercial and open-source systems. While these systems have shown compelling results on average, the variation in their performance across different demographic groups has not been thoroughly examined. In this work, we investigate the bias of de-identification systems on names in clinical notes via a large-scale empirical analysis. To achieve this, we create 16 name sets that vary along four demographic dimensions: gender, race, name popularity, and the decade of popularity. We insert these names into 100 manually curated clinical templates and evaluate the performance of nine public and private de-identification methods. Our findings reveal that there are statistically significant performance gaps along a majority of the demographic dimensions in most methods. We further illustrate that de-identification quality is affected by polysemy in names, gender context, and clinical note characteristics. To mitigate the identified gaps, we propose a simple and method-agnostic solution by fine-tuning de-identification methods with clinical context and diverse names. Overall, it is imperative to address the bias in existing methods immediately so that downstream stakeholders can build high-quality systems to serve all demographic parties fairly.
Uncertainty Quantification with Pre-trained Language Models: A Large-Scale Empirical Analysis
Oct 10, 2022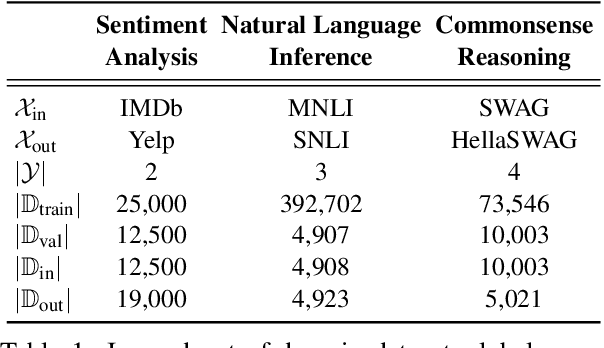
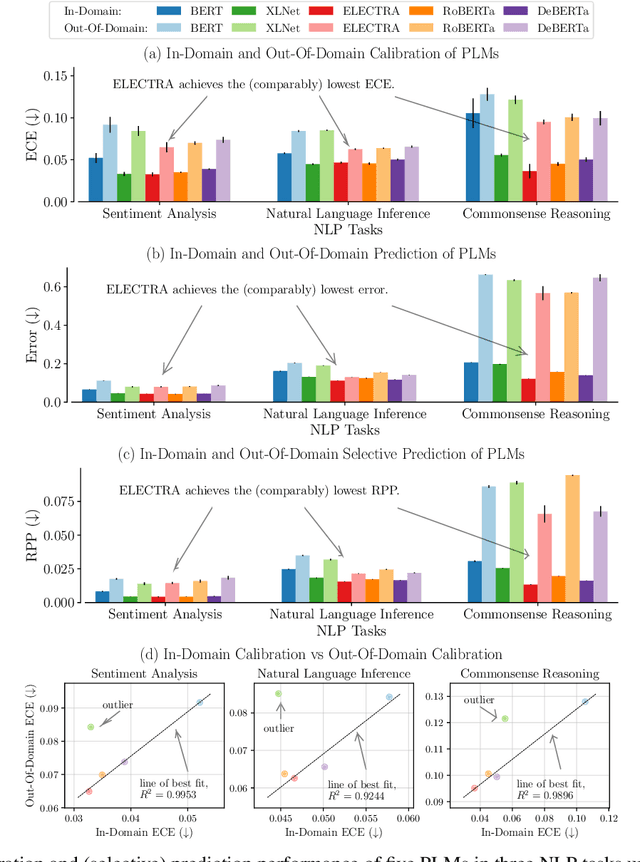

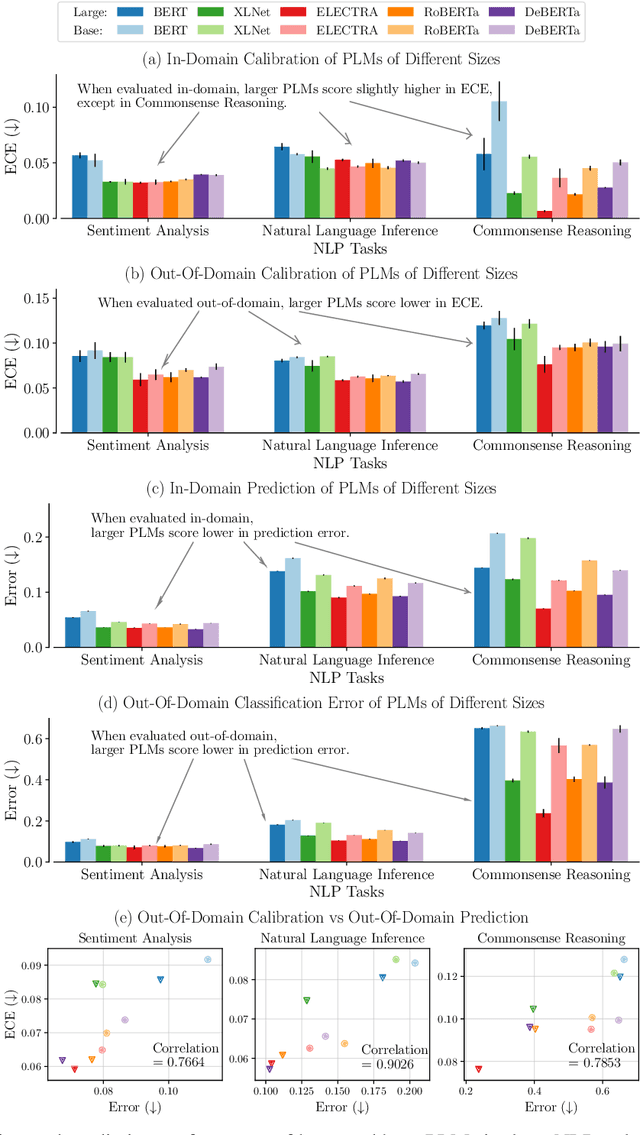
Pre-trained language models (PLMs) have gained increasing popularity due to their compelling prediction performance in diverse natural language processing (NLP) tasks. When formulating a PLM-based prediction pipeline for NLP tasks, it is also crucial for the pipeline to minimize the calibration error, especially in safety-critical applications. That is, the pipeline should reliably indicate when we can trust its predictions. In particular, there are various considerations behind the pipeline: (1) the choice and (2) the size of PLM, (3) the choice of uncertainty quantifier, (4) the choice of fine-tuning loss, and many more. Although prior work has looked into some of these considerations, they usually draw conclusions based on a limited scope of empirical studies. There still lacks a holistic analysis on how to compose a well-calibrated PLM-based prediction pipeline. To fill this void, we compare a wide range of popular options for each consideration based on three prevalent NLP classification tasks and the setting of domain shift. In response, we recommend the following: (1) use ELECTRA for PLM encoding, (2) use larger PLMs if possible, (3) use Temp Scaling as the uncertainty quantifier, and (4) use Focal Loss for fine-tuning.
SAIS: Supervising and Augmenting Intermediate Steps for Document-Level Relation Extraction
Sep 24, 2021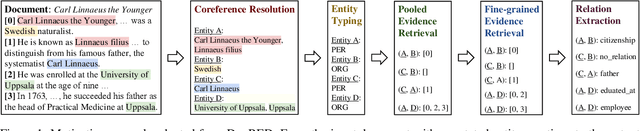


Stepping from sentence-level to document-level relation extraction, the research community confronts increasing text length and more complicated entity interactions. Consequently, it is more challenging to encode the key sources of information--relevant contexts and entity types. However, existing methods only implicitly learn to model these critical information sources while being trained for relation extraction. As a result, they suffer the problems of ineffective supervision and uninterpretable model predictions. In contrast, we propose to explicitly teach the model to capture relevant contexts and entity types by supervising and augmenting intermediate steps (SAIS) for relation extraction. Based on a broad spectrum of carefully designed tasks, our proposed SAIS method not only extracts relations of better quality due to more effective supervision, but also retrieves the corresponding supporting evidence more accurately so as to enhance interpretability. By assessing model uncertainty, SAIS further boosts the performance via evidence-based data augmentation and ensemble inference while reducing the computational cost. Eventually, SAIS delivers state-of-the-art relation extraction results on three benchmarks (DocRED, CDR, and GDA) and achieves 5.04% relative gains in F1 score compared to the runner-up in evidence retrieval on DocRED.
Amortized Auto-Tuning: Cost-Efficient Transfer Optimization for Hyperparameter Recommendation
Jun 17, 2021



With the surge in the number of hyperparameters and training times of modern machine learning models, hyperparameter tuning is becoming increasingly expensive. Although methods have been proposed to speed up tuning via knowledge transfer, they typically require the final performance of hyperparameters and do not focus on low-fidelity information. Nevertheless, this common practice is suboptimal and can incur an unnecessary use of resources. It is more cost-efficient to instead leverage the low-fidelity tuning observations to measure inter-task similarity and transfer knowledge from existing to new tasks accordingly. However, performing multi-fidelity tuning comes with its own challenges in the transfer setting: the noise in the additional observations and the need for performance forecasting. Therefore, we conduct a thorough analysis of the multi-task multi-fidelity Bayesian optimization framework, which leads to the best instantiation--amortized auto-tuning (AT2). We further present an offline-computed 27-task hyperparameter recommendation (HyperRec) database to serve the community. Extensive experiments on HyperRec and other real-world databases illustrate the effectiveness of our AT2 method.