 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Style Breaks Safety: Defending Language Models Against Superficial Style Alignment
Jun 09, 2025Large language models (LLMs) can be prompted with specific styles (e.g., formatting responses as lists), including in jailbreak queries. Although these style patterns are semantically unrelated to the malicious intents behind jailbreak queries, their safety impact remains unclear. In this work, we seek to understand whether style patterns compromise LLM safety, how superficial style alignment increases model vulnerability, and how best to mitigate these risks during alignment. We evaluate 32 LLMs across seven jailbreak benchmarks, and find that malicious queries with style patterns inflate the attack success rate (ASR) for nearly all models. Notably, ASR inflation correlates with both the length of style patterns and the relative attention an LLM exhibits on them. We then investigate superficial style alignment, and find that fine-tuning with specific styles makes LLMs more vulnerable to jailbreaks of those same styles. Finally, we propose SafeStyle, a defense strategy that incorporates a small amount of safety training data augmented to match the distribution of style patterns in the fine-tuning data. Across three LLMs and five fine-tuning style settings, SafeStyle consistently outperforms baselines in maintaining LLM safety.
MaskMedPaint: Masked Medical Image Inpainting with Diffusion Models for Mitigation of Spurious Correlations
Nov 16, 2024



Spurious features associated with class labels can lead image classifiers to rely on shortcuts that don't generalize well to new domains. This is especially problematic in medical settings, where biased models fail when applied to different hospitals or systems. In such cases, data-driven methods to reduce spurious correlations are preferred, as clinicians can directly validate the modified images. While Denoising Diffusion Probabilistic Models (Diffusion Models) show promise for natural images, they are impractical for medical use due to the difficulty of describing spurious medical features. To address this, we propose Masked Medical Image Inpainting (MaskMedPaint), which uses text-to-image diffusion models to augment training images by inpainting areas outside key classification regions to match the target domain. We demonstrate that MaskMedPaint enhances generalization to target domains across both natural (Waterbirds, iWildCam) and medical (ISIC 2018, Chest X-ray) datasets, given limited unlabeled target images.
BendVLM: Test-Time Debiasing of Vision-Language Embeddings
Nov 07, 2024



Vision-language model (VLM) embeddings have been shown to encode biases present in their training data, such as societal biases that prescribe negative characteristics to members of various racial and gender identities. VLMs are being quickly adopted for a variety of tasks ranging from few-shot classification to text-guided image generation, making debiasing VLM embeddings crucial. Debiasing approaches that fine-tune the VLM often suffer from catastrophic forgetting. On the other hand, fine-tuning-free methods typically utilize a "one-size-fits-all" approach that assumes that correlation with the spurious attribute can be explained using a single linear direction across all possible inputs. In this work, we propose Bend-VLM, a nonlinear, fine-tuning-free approach for VLM embedding debiasing that tailors the debiasing operation to each unique input. This allows for a more flexible debiasing approach. Additionally, we do not require knowledge of the set of inputs a priori to inference time, making our method more appropriate for online, open-set tasks such as retrieval and text guided image generation.
Identifying Implicit Social Biases in Vision-Language Models
Nov 01, 2024Vision-language models, like CLIP (Contrastive Language Image Pretraining), are becoming increasingly popular for a wide range of multimodal retrieval tasks. However, prior work has shown that large language and deep vision models can learn historical biases contained in their training sets, leading to perpetuation of stereotypes and potential downstream harm. In this work, we conduct a systematic analysis of the social biases that are present in CLIP, with a focus on the interaction between image and text modalities. We first propose a taxonomy of social biases called So-B-IT, which contains 374 words categorized across ten types of bias. Each type can lead to societal harm if associated with a particular demographic group. Using this taxonomy, we examine images retrieved by CLIP from a facial image dataset using each word as part of a prompt. We find that CLIP frequently displays undesirable associations between harmful words and specific demographic groups, such as retrieving mostly pictures of Middle Eastern men when asked to retrieve images of a "terrorist". Finally, we conduct an analysis of the source of such biases, by showing that the same harmful stereotypes are also present in a large image-text dataset used to train CLIP models for examples of biases that we find. Our findings highlight the importance of evaluating and addressing bias in vision-language models, and suggest the need for transparency and fairness-aware curation of large pre-training datasets.
TAXI: Evaluating Categorical Knowledge Editing for Language Models
Apr 23, 2024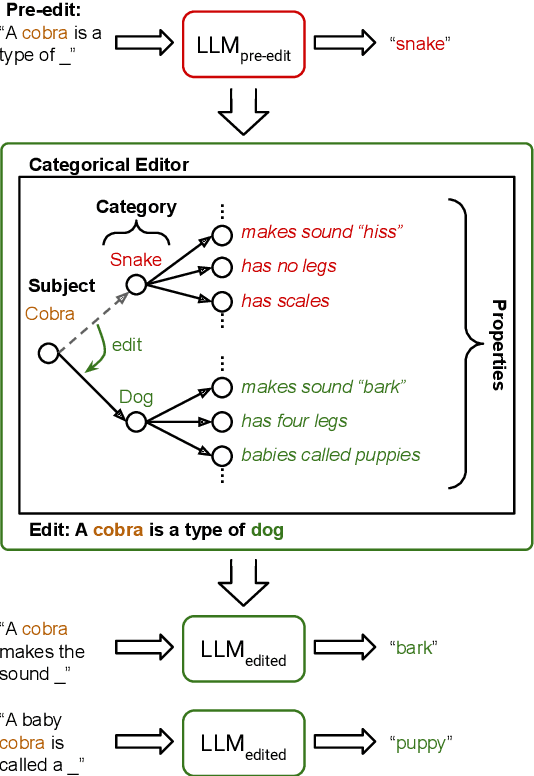
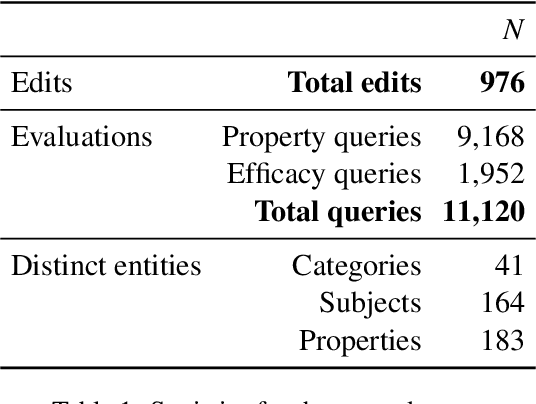

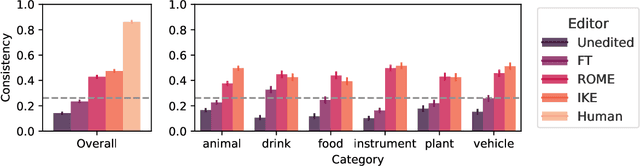
Humans rarely learn one fact in isolation. Instead, learning a new fact induces knowledge of other facts about the world. For example, in learning a korat is a type of cat, you also infer it is a mammal and has claws, ensuring your model of the world is consistent. Knowledge editing aims to inject new facts into language models to improve their factuality, but current benchmarks fail to evaluate consistency, which is critical to ensure efficient, accurate, and generalizable edits. We manually create TAXI, a new benchmark dataset specifically created to evaluate consistency. TAXI contains 11,120 multiple-choice queries for 976 edits spanning 41 categories (e.g., Dogs), 164 subjects (e.g., Labrador), and 183 properties (e.g., is a mammal). We then use TAXI to evaluate popular editors' consistency, measuring how often editing a subject's category appropriately edits its properties. We find that 1) the editors achieve marginal, yet non-random consistency, 2) their consistency far underperforms human baselines, and 3) consistency is more achievable when editing atypical subjects. Our code and data are available at https://github.com/derekpowell/taxi.
Learning from Time Series under Temporal Label Noise
Feb 06, 2024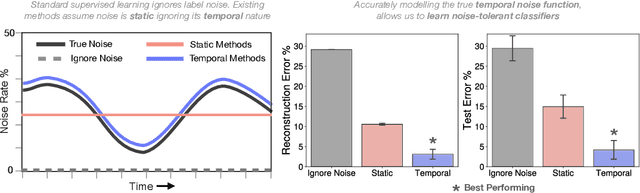

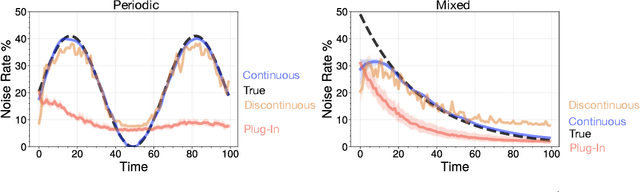
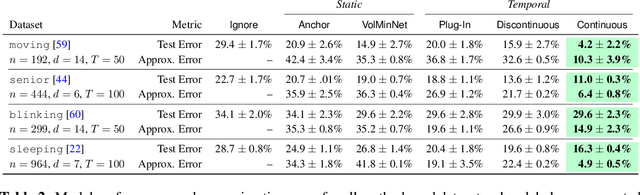
Many sequential classification tasks are affected by label noise that varies over time. Such noise can cause label quality to improve, worsen, or periodically change over time. We first propose and formalize temporal label noise, an unstudied problem for sequential classification of time series. In this setting, multiple labels are recorded in sequence while being corrupted by a time-dependent noise function. We first demonstrate the importance of modelling the temporal nature of the label noise function and how existing methods will consistently underperform. We then propose methods that can train noise-tolerant classifiers by estimating the temporal label noise function directly from data. We show that our methods lead to state-of-the-art performance in the presence of diverse temporal label noise functions using real and synthetic data.
Stop&Hop: Early Classification of Irregular Time Series
Aug 21, 2022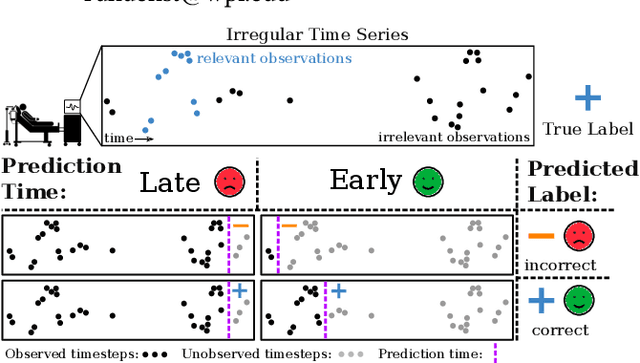
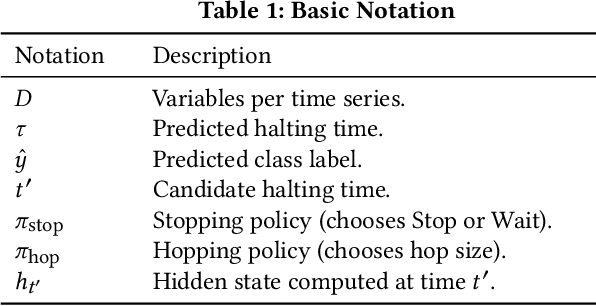
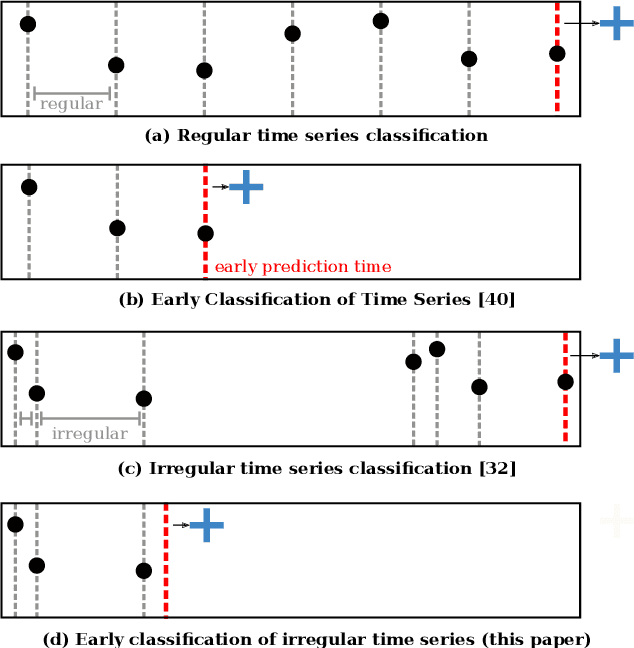
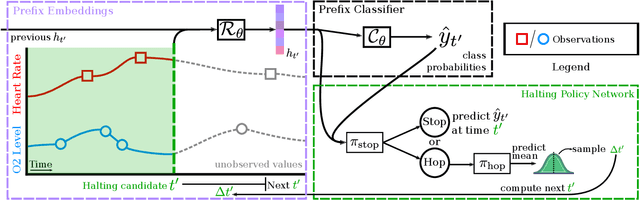
Early classification algorithms help users react faster to their machine learning model's predictions. Early warning systems in hospitals, for example, let clinicians improve their patients' outcomes by accurately predicting infections. While early classification systems are advancing rapidly, a major gap remains: existing systems do not consider irregular time series, which have uneven and often-long gaps between their observations. Such series are notoriously pervasive in impactful domains like healthcare. We bridge this gap and study early classification of irregular time series, a new setting for early classifiers that opens doors to more real-world problems. Our solution, Stop&Hop, uses a continuous-time recurrent network to model ongoing irregular time series in real time, while an irregularity-aware halting policy, trained with reinforcement learning, predicts when to stop and classify the streaming series. By taking real-valued step sizes, the halting policy flexibly decides exactly when to stop ongoing series in real time. This way, Stop&Hop seamlessly integrates information contained in the timing of observations, a new and vital source for early classification in this setting, with the time series values to provide early classifications for irregular time series. Using four synthetic and three real-world datasets, we demonstrate that Stop&Hop consistently makes earlier and more-accurate predictions than state-of-the-art alternatives adapted to this new problem. Our code is publicly available at https://github.com/thartvigsen/StopAndHop.