 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegretful Decisions under Label Noise
Apr 12, 2025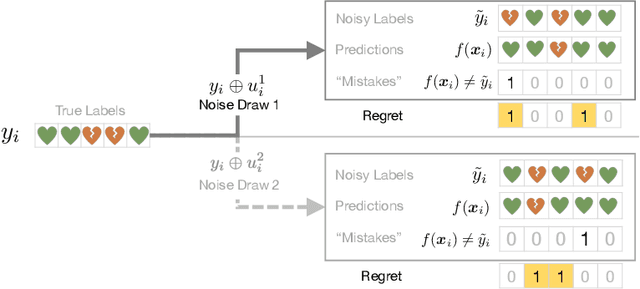


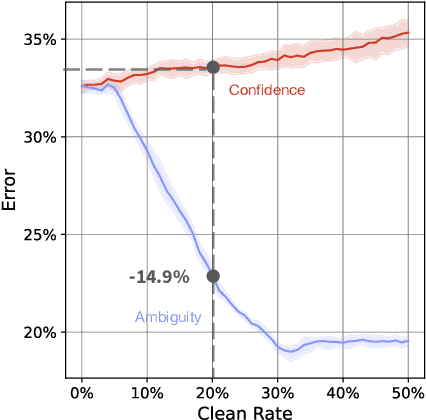
Machine learning models are routinely used to support decisions that affect individuals -- be it to screen a patient for a serious illness or to gauge their response to treatment. In these tasks, we are limited to learning models from datasets with noisy labels. In this paper, we study the instance-level impact of learning under label noise. We introduce a notion of regret for this regime which measures the number of unforeseen mistakes due to noisy labels. We show that standard approaches to learning under label noise can return models that perform well at a population level while subjecting individuals to a lottery of mistakes. We present a versatile approach to estimate the likelihood of mistakes at the individual level from a noisy dataset by training models over plausible realizations of datasets without label noise. This is supported by a comprehensive empirical study of label noise in clinical prediction tasks. Our results reveal how failure to anticipate mistakes can compromise model reliability and adoption, and demonstrate how we can address these challenges by anticipating and avoiding regretful decisions.
Learning from Time Series under Temporal Label Noise
Feb 06, 2024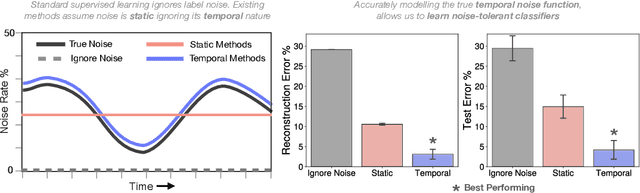

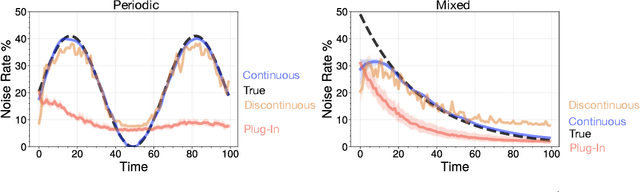
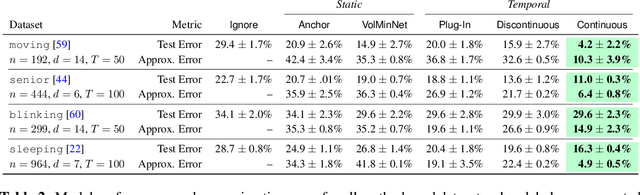
Many sequential classification tasks are affected by label noise that varies over time. Such noise can cause label quality to improve, worsen, or periodically change over time. We first propose and formalize temporal label noise, an unstudied problem for sequential classification of time series. In this setting, multiple labels are recorded in sequence while being corrupted by a time-dependent noise function. We first demonstrate the importance of modelling the temporal nature of the label noise function and how existing methods will consistently underperform. We then propose methods that can train noise-tolerant classifiers by estimating the temporal label noise function directly from data. We show that our methods lead to state-of-the-art performance in the presence of diverse temporal label noise functions using real and synthetic data.