 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaSubVAE: Adaptive Subgrouping for Scalable and Robust OOD Detection
Jun 11, 2025Real-world observational data often contain existing or emerging heterogeneous subpopulations that deviate from global patterns. The majority of models tend to overlook these underrepresented groups, leading to inaccurate or even harmful predictions. Existing solutions often rely on detecting these samples as Out-of-domain (OOD) rather than adapting the model to new emerging patterns. We introduce DynaSubVAE, a Dynamic Subgrouping Variational Autoencoder framework that jointly performs representation learning and adaptive OOD detection. Unlike conventional approaches, DynaSubVAE evolves with the data by dynamically updating its latent structure to capture new trends. It leverages a novel non-parametric clustering mechanism, inspired by Gaussian Mixture Models, to discover and model latent subgroups based on embedding similarity. Extensive experiments show that DynaSubVAE achieves competitive performance in both near-OOD and far-OOD detection, and excels in class-OOD scenarios where an entire class is missing during training. We further illustrate that our dynamic subgrouping mechanism outperforms standalone clustering methods such as GMM and KMeans++ in terms of both OOD accuracy and regret precision.
When Style Breaks Safety: Defending Language Models Against Superficial Style Alignment
Jun 09, 2025Large language models (LLMs) can be prompted with specific styles (e.g., formatting responses as lists), including in jailbreak queries. Although these style patterns are semantically unrelated to the malicious intents behind jailbreak queries, their safety impact remains unclear. In this work, we seek to understand whether style patterns compromise LLM safety, how superficial style alignment increases model vulnerability, and how best to mitigate these risks during alignment. We evaluate 32 LLMs across seven jailbreak benchmarks, and find that malicious queries with style patterns inflate the attack success rate (ASR) for nearly all models. Notably, ASR inflation correlates with both the length of style patterns and the relative attention an LLM exhibits on them. We then investigate superficial style alignment, and find that fine-tuning with specific styles makes LLMs more vulnerable to jailbreaks of those same styles. Finally, we propose SafeStyle, a defense strategy that incorporates a small amount of safety training data augmented to match the distribution of style patterns in the fine-tuning data. Across three LLMs and five fine-tuning style settings, SafeStyle consistently outperforms baselines in maintaining LLM safety.
Machine Learning for Health symposium 2024 -- Findings track
Mar 02, 2025A collection of the accepted Findings papers that were presented at the 4th Machine Learning for Health symposium (ML4H 2024), which was held on December 15-16, 2024, in Vancouver, BC, Canada. ML4H 2024 invited high-quality submissions describing innovative research in a variety of health-related disciplines including healthcare, biomedicine, and public health. Works could be submitted to either the archival Proceedings track, or the non-archival Findings track. The Proceedings track targeted mature, cohesive works with technical sophistication and high-impact relevance to health. The Findings track promoted works that would spark new insights, collaborations, and discussions at ML4H. Both tracks were given the opportunity to share their work through the in-person poster session. All the manuscripts submitted to ML4H Symposium underwent a double-blind peer-review process.
An Information Criterion for Controlled Disentanglement of Multimodal Data
Oct 31, 2024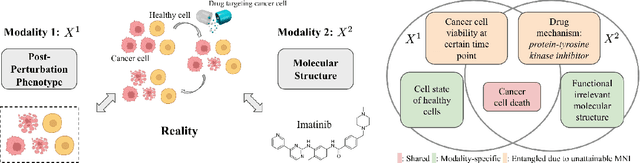
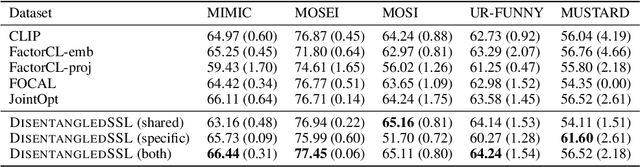
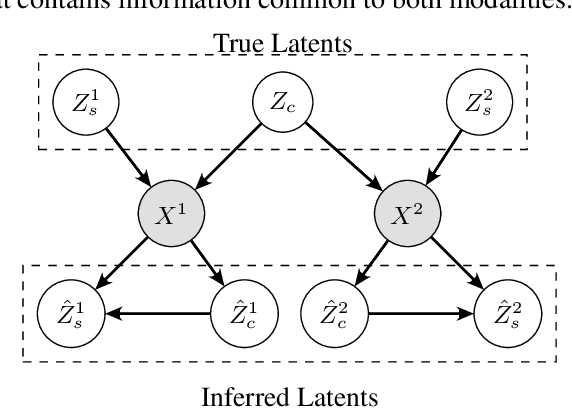
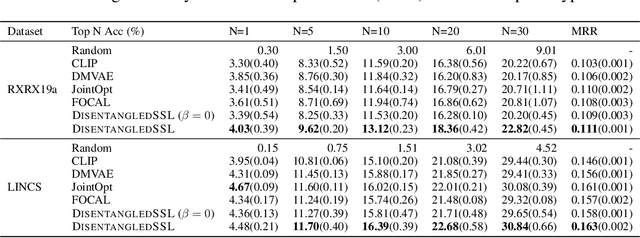
Multimodal representation learning seeks to relate and decompose information inherent in multiple modalities. By disentangling modality-specific information from information that is shared across modalities, we can improve interpretability and robustness and enable downstream tasks such as the generation of counterfactual outcomes. Separating the two types of information is challenging since they are often deeply entangled in many real-world applications. We propose Disentangled Self-Supervised Learning (DisentangledSSL), a novel self-supervised approach for learning disentangled representations. We present a comprehensive analysis of the optimality of each disentangled representation, particularly focusing on the scenario not covered in prior work where the so-called Minimum Necessary Information (MNI) point is not attainable. We demonstrate that DisentangledSSL successfully learns shared and modality-specific features on multiple synthetic and real-world datasets and consistently outperforms baselines on various downstream tasks, including prediction tasks for vision-language data, as well as molecule-phenotype retrieval tasks for biological data.
A collection of the accepted papers for the Human-Centric Representation Learning workshop at AAAI 2024
Mar 14, 2024This non-archival index is not complete, as some accepted papers chose to opt-out of inclusion. The list of all accepted papers is available on the workshop website.
Learning from Time Series under Temporal Label Noise
Feb 06, 2024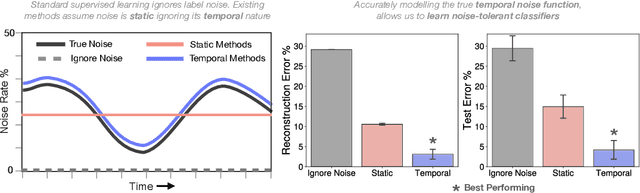

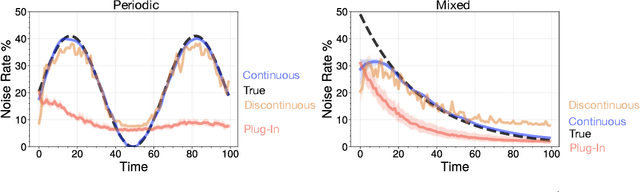
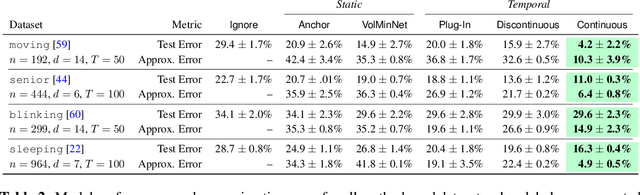
Many sequential classification tasks are affected by label noise that varies over time. Such noise can cause label quality to improve, worsen, or periodically change over time. We first propose and formalize temporal label noise, an unstudied problem for sequential classification of time series. In this setting, multiple labels are recorded in sequence while being corrupted by a time-dependent noise function. We first demonstrate the importance of modelling the temporal nature of the label noise function and how existing methods will consistently underperform. We then propose methods that can train noise-tolerant classifiers by estimating the temporal label noise function directly from data. We show that our methods lead to state-of-the-art performance in the presence of diverse temporal label noise functions using real and synthetic data.
Time-Varying Correlation Networks for Interpretable Change Point Detection
Nov 08, 2022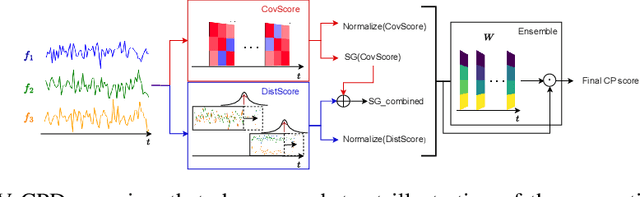
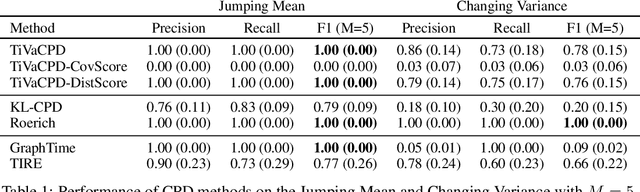
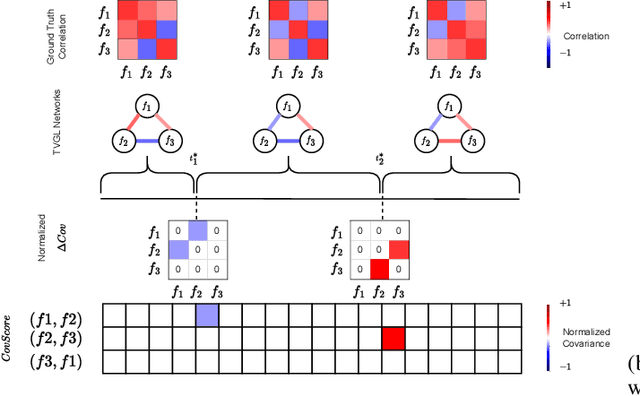
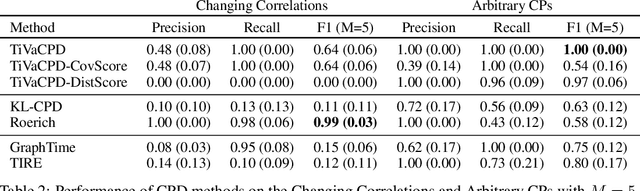
Change point detection (CPD) methods aim to detect abrupt changes in time-series data. Recent CPD methods have demonstrated their potential in identifying changes in underlying statistical distributions but often fail to capture complex changes in the correlation structure in time-series data. These methods also fail to generalize effectively, as even within the same time-series, different kinds of change points (CPs) may arise that are best characterized by different types of time-series perturbations. To address this issue, we propose TiVaCPD, a CPD methodology that uses a time-varying graphical lasso based method to identify changes in correlation patterns between features over time, and combines that with an aggregate Kernel Maximum Mean Discrepancy (MMD) test to identify subtle changes in the underlying statistical distributions of dynamically established time windows. We evaluate the performance of TiVaCPD in identifying and characterizing various types of CPs in time-series and show that our method outperforms current state-of-the-art CPD methods for all categories of CPs.
Decoupling Local and Global Representations of Time Series
Feb 11, 2022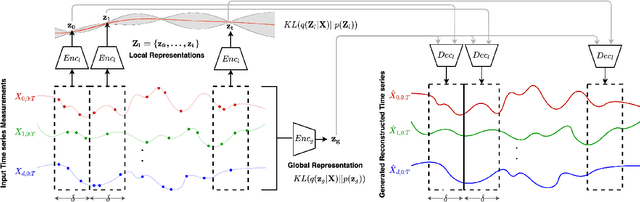
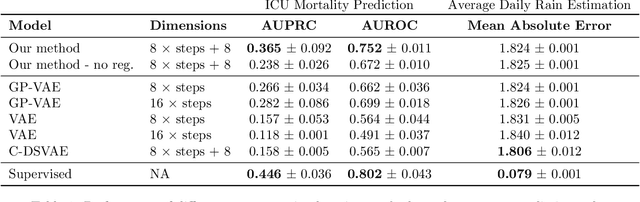
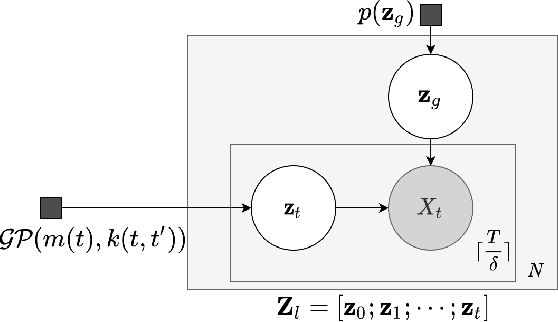
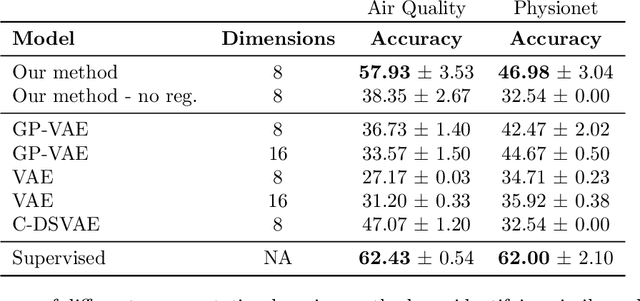
Real-world time series data are often generated from several sources of variation. Learning representations that capture the factors contributing to this variability enables a better understanding of the data via its underlying generative process and improves performance on downstream machine learning tasks. This paper proposes a novel generative approach for learning representations for the global and local factors of variation in time series. The local representation of each sample models non-stationarity over time with a stochastic process prior, and the global representation of the sample encodes the time-independent characteristics. To encourage decoupling between the representations, we introduce counterfactual regularization that minimizes the mutual information between the two variables. In experiments, we demonstrate successful recovery of the true local and global variability factors on simulated data, and show that representations learned using our method yield superior performance on downstream tasks on real-world datasets. We believe that the proposed way of defining representations is beneficial for data modelling and yields better insights into the complexity of real-world data.
Unsupervised Representation Learning for Time Series with Temporal Neighborhood Coding
Jun 01, 2021



Time series are often complex and rich in information but sparsely labeled and therefore challenging to model. In this paper, we propose a self-supervised framework for learning generalizable representations for non-stationary time series. Our approach, called Temporal Neighborhood Coding (TNC), takes advantage of the local smoothness of a signal's generative process to define neighborhoods in time with stationary properties. Using a debiased contrastive objective, our framework learns time series representations by ensuring that in the encoding space, the distribution of signals from within a neighborhood is distinguishable from the distribution of non-neighboring signals. Our motivation stems from the medical field, where the ability to model the dynamic nature of time series data is especially valuable for identifying, tracking, and predicting the underlying patients' latent states in settings where labeling data is practically impossible. We compare our method to recently developed unsupervised representation learning approaches and demonstrate superior performance on clustering and classification tasks for multiple datasets.
What went wrong and when? Instance-wise Feature Importance for Time-series Models
Mar 05, 2020
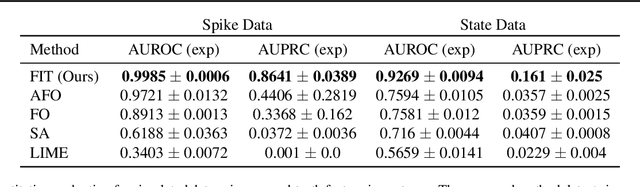

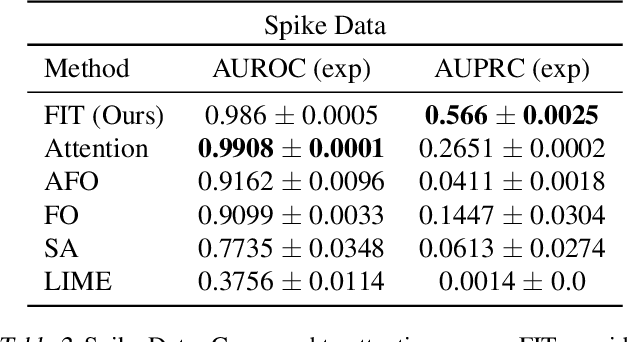
Multivariate time series models are poised to be used for decision support in high-stakes applications, such as healthcare. In these contexts, it is important to know which features at which times most influenced a prediction. We demonstrate a general approach for assigning importance to observations in multivariate time series, based on their counterfactual influence on future predictions. Specifically, we define the importance of an observation as the change in the predictive distribution, had the observation not been seen. We integrate over plausible counterfactuals by sampling from the corresponding conditional distributions of generative time series models. We compare our importance metric to gradient-based explanations, attention mechanisms, and other baselines in simulated and clinical ICU data, and show that our approach generates the most precise explanations. Our method is inexpensive, model agnostic, and can be used with arbitrarily complex time series models and predictors.