 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Feature Importance Scores for Automated Feature Engineering
Jun 06, 2024Feature engineering has demonstrated substantial utility for many machine learning workflows, such as in the small data regime or when distribution shifts are severe. Thus automating this capability can relieve much manual effort and improve model performance. Towards this, we propose AutoMAN, or Automated Mask-based Feature Engineering, an automated feature engineering framework that achieves high accuracy, low latency, and can be extended to heterogeneous and time-varying data. AutoMAN is based on effectively exploring the candidate transforms space, without explicitly manifesting transformed features. This is achieved by learning feature importance masks, which can be extended to support other modalities such as time series. AutoMAN learns feature transform importance end-to-end, incorporating a dataset's task target directly into feature engineering, resulting in state-of-the-art performance with significantly lower latency compared to alternatives.
ASPEST: Bridging the Gap Between Active Learning and Selective Prediction
Apr 07, 2023Selective prediction aims to learn a reliable model that abstains from making predictions when the model uncertainty is high. These predictions can then be deferred to a human expert for further evaluation. In many real-world scenarios, however, the distribution of test data is different from the training data. This results in more inaccurate predictions, necessitating increased human labeling, which is difficult and expensive in many scenarios. Active learning circumvents this difficulty by only querying the most informative examples and, in several cases, has been shown to lower the overall labeling effort. In this work, we bridge the gap between selective prediction and active learning, proposing a new learning paradigm called active selective prediction which learns to query more informative samples from the shifted target domain while increasing accuracy and coverage. For this new problem, we propose a simple but effective solution, ASPEST, that trains ensembles of model snapshots using self-training with their aggregated outputs as pseudo labels. Extensive experiments on several image, text and structured datasets with domain shifts demonstrate that active selective prediction can significantly outperform prior work on selective prediction and active learning (e.g. on the MNIST$\to$SVHN benchmark with the labeling budget of 100, ASPEST improves the AUC metric from 79.36% to 88.84%) and achieves more optimal utilization of humans in the loop.
Data-Efficient and Interpretable Tabular Anomaly Detection
Mar 03, 2022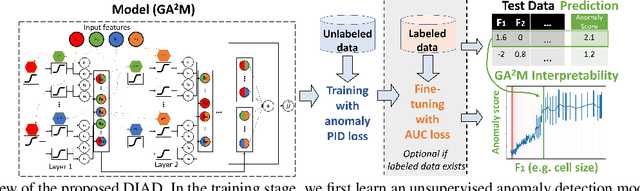
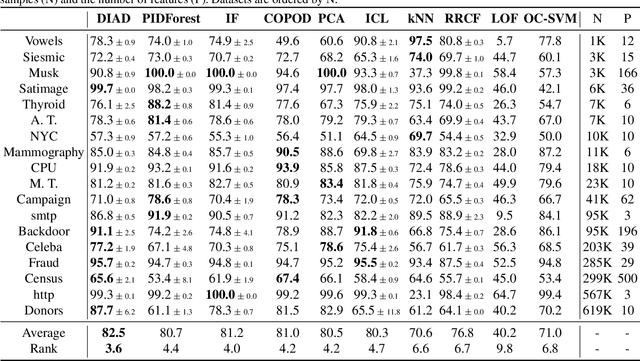
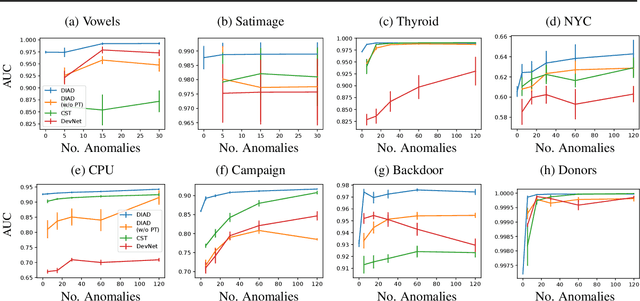
Anomaly detection (AD) plays an important role in numerous applications. We focus on two understudied aspects of AD that are critical for integration into real-world applications. First, most AD methods cannot incorporate labeled data that are often available in practice in small quantities and can be crucial to achieve high AD accuracy. Second, most AD methods are not interpretable, a bottleneck that prevents stakeholders from understanding the reason behind the anomalies. In this paper, we propose a novel AD framework that adapts a white-box model class, Generalized Additive Models, to detect anomalies using a partial identification objective which naturally handles noisy or heterogeneous features. In addition, the proposed framework, DIAD, can incorporate a small amount of labeled data to further boost anomaly detection performances in semi-supervised settings. We demonstrate the superiority of our framework compared to previous work in both unsupervised and semi-supervised settings using diverse tabular datasets. For example, under 5 labeled anomalies DIAD improves from 86.2\% to 89.4\% AUC by learning AD from unlabeled data. We also present insightful interpretations that explain why DIAD deems certain samples as anomalies.
Decoupling Local and Global Representations of Time Series
Feb 11, 2022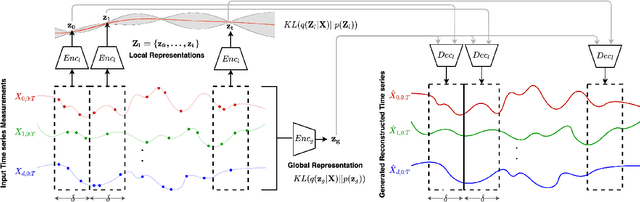
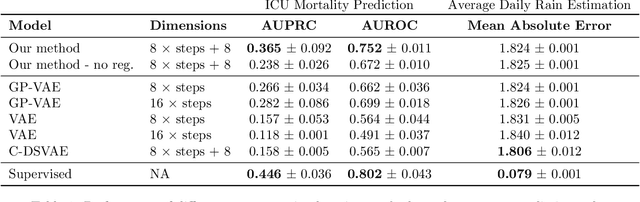
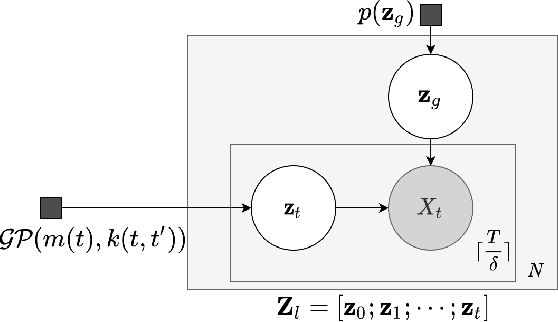
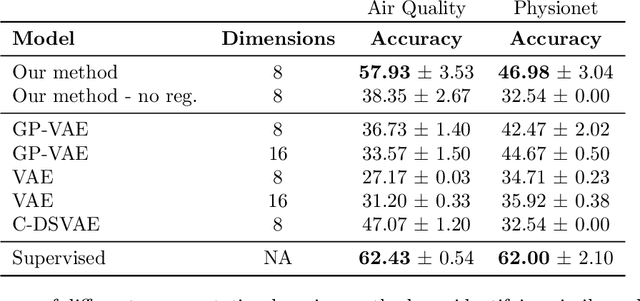
Real-world time series data are often generated from several sources of variation. Learning representations that capture the factors contributing to this variability enables a better understanding of the data via its underlying generative process and improves performance on downstream machine learning tasks. This paper proposes a novel generative approach for learning representations for the global and local factors of variation in time series. The local representation of each sample models non-stationarity over time with a stochastic process prior, and the global representation of the sample encodes the time-independent characteristics. To encourage decoupling between the representations, we introduce counterfactual regularization that minimizes the mutual information between the two variables. In experiments, we demonstrate successful recovery of the true local and global variability factors on simulated data, and show that representations learned using our method yield superior performance on downstream tasks on real-world datasets. We believe that the proposed way of defining representations is beneficial for data modelling and yields better insights into the complexity of real-world data.
Distance-Based Learning from Errors for Confidence Calibration
Dec 03, 2019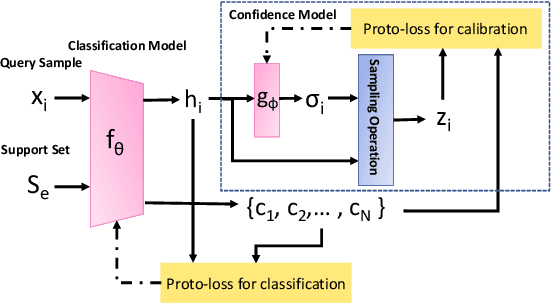
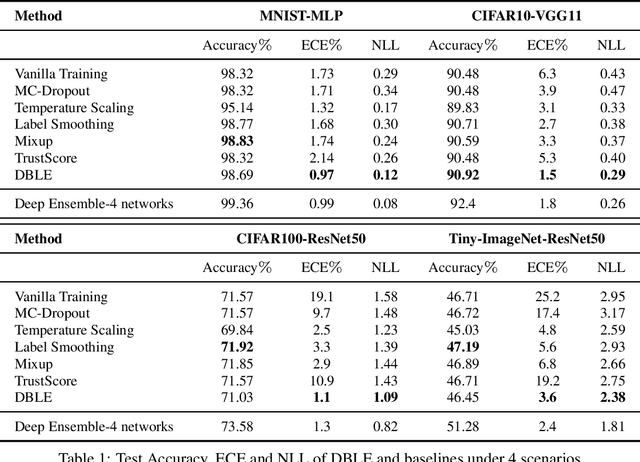
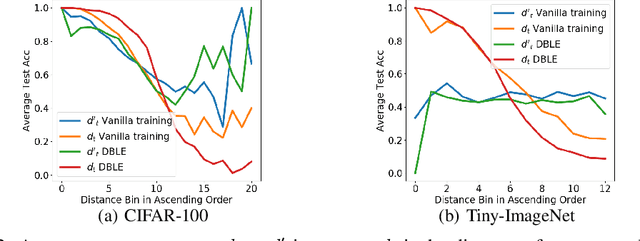

Deep neural networks (DNNs) are poorly-calibrated when trained in conventional ways. To improve confidence calibration of DNNs, we propose a novel training method, distance-based learning from errors (DBLE). DBLE bases its confidence estimation on distances in the representation space. We first adapt prototypical learning for training of a classification model for DBLE. It yields a representation space where the distance from a test sample to its ground-truth class center can calibrate the model performance. At inference, however, these distances are not available due to the lack of ground-truth labels. To circumvent this by approximately inferring the distance for every test sample, we propose to train a confidence model jointly with the classification model by merely learning from mis-classified training samples, which we show to be highly beneficial for effective learning. On multiple datasets and DNN architectures, we demonstrate that DBLE outperforms alternative single-modal confidence calibration approaches. DBLE also achieves comparable performance with computationally-expensive ensemble approaches with lower computational cost and lower number of parameters.
EPNAS: Efficient Progressive Neural Architecture Search
Jul 07, 2019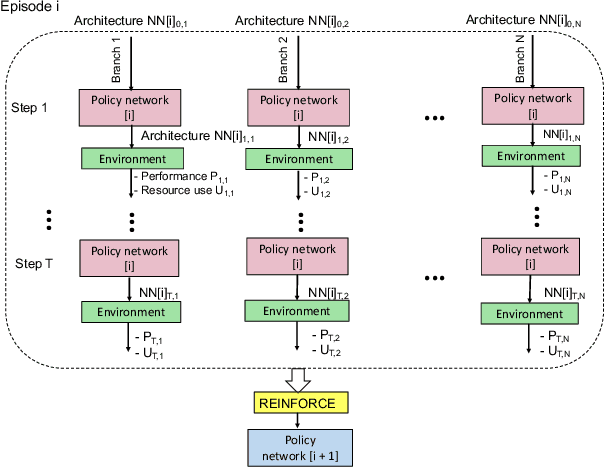
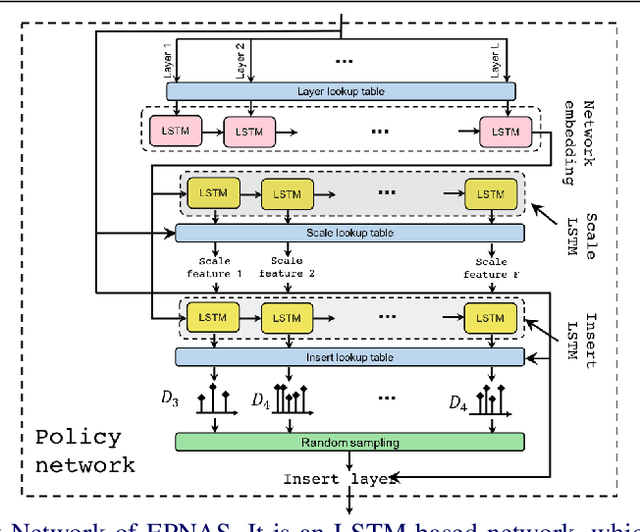
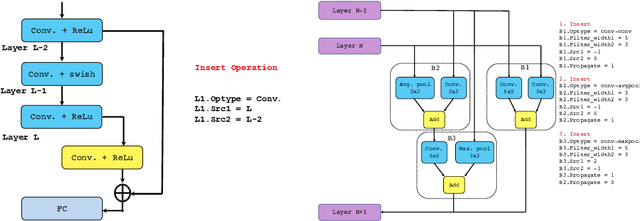
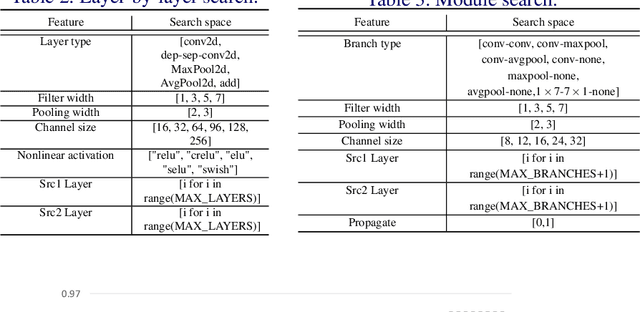
In this paper, we propose Efficient Progressive Neural Architecture Search (EPNAS), a neural architecture search (NAS) that efficiently handles large search space through a novel progressive search policy with performance prediction based on REINFORCE~\cite{Williams.1992.PG}. EPNAS is designed to search target networks in parallel, which is more scalable on parallel systems such as GPU/TPU clusters. More importantly, EPNAS can be generalized to architecture search with multiple resource constraints, \eg, model size, compute complexity or intensity, which is crucial for deployment in widespread platforms such as mobile and cloud. We compare EPNAS against other state-of-the-art (SoTA) network architectures (\eg, MobileNetV2~\cite{mobilenetv2}) and efficient NAS algorithms (\eg, ENAS~\cite{pham2018efficient}, and PNAS~\cite{Liu2017b}) on image recognition tasks using CIFAR10 and ImageNet. On both datasets, EPNAS is superior \wrt architecture searching speed and recognition accuracy.
Deep Voice 2: Multi-Speaker Neural Text-to-Speech
Sep 20, 2017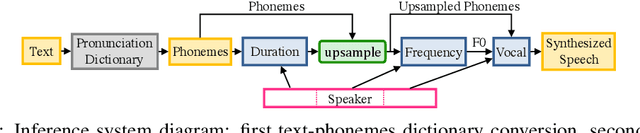
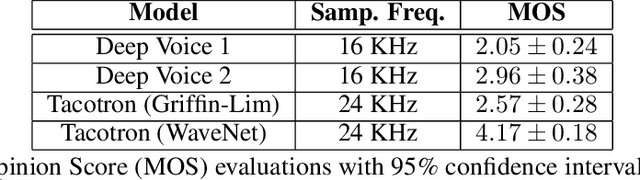


We introduce a technique for augmenting neural text-to-speech (TTS) with lowdimensional trainable speaker embeddings to generate different voices from a single model. As a starting point, we show improvements over the two state-ofthe-art approaches for single-speaker neural TTS: Deep Voice 1 and Tacotron. We introduce Deep Voice 2, which is based on a similar pipeline with Deep Voice 1, but constructed with higher performance building blocks and demonstrates a significant audio quality improvement over Deep Voice 1. We improve Tacotron by introducing a post-processing neural vocoder, and demonstrate a significant audio quality improvement. We then demonstrate our technique for multi-speaker speech synthesis for both Deep Voice 2 and Tacotron on two multi-speaker TTS datasets. We show that a single neural TTS system can learn hundreds of unique voices from less than half an hour of data per speaker, while achieving high audio quality synthesis and preserving the speaker identities almost perfectly.
Supervised classification-based stock prediction and portfolio optimization
Jun 03, 2014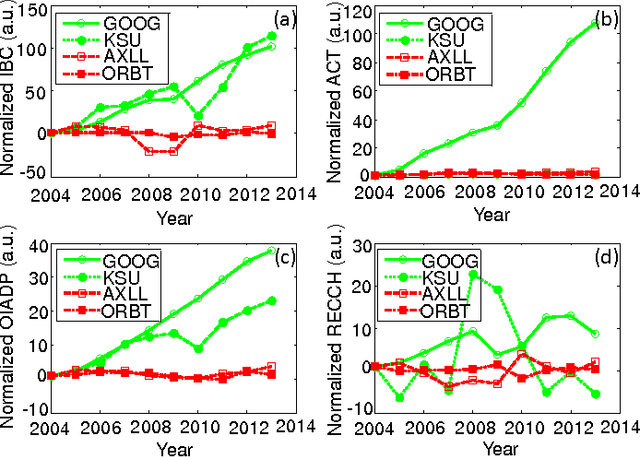
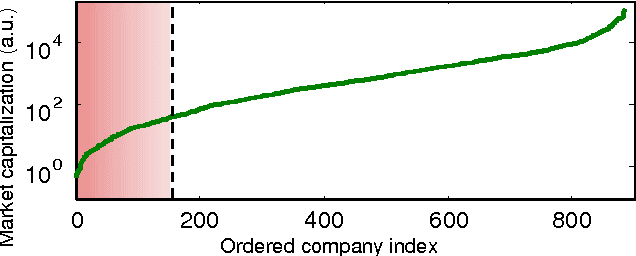
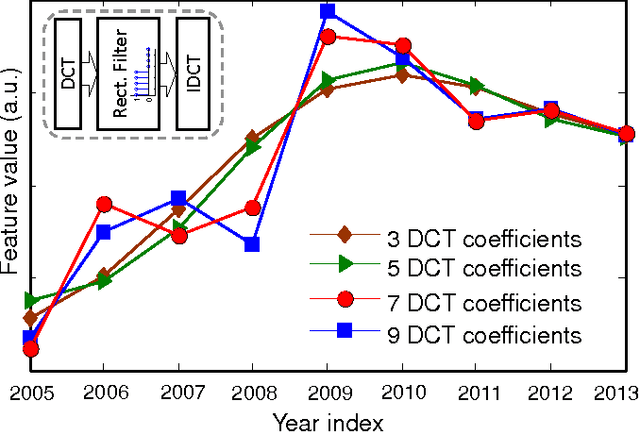
As the number of publicly traded companies as well as the amount of their financial data grows rapidly, it is highly desired to have tracking, analysis, and eventually stock selections automated. There have been few works focusing on estimating the stock prices of individual companies. However, many of those have worked with very small number of financial parameters. In this work, we apply machine learning techniques to address automated stock picking, while using a larger number of financial parameters for individual companies than the previous studies. Our approaches are based on the supervision of prediction parameters using company fundamentals, time-series properties, and correlation information between different stocks. We examine a variety of supervised learning techniques and found that using stock fundamentals is a useful approach for the classification problem, when combined with the high dimensional data handling capabilities of support vector machine. The portfolio our system suggests by predicting the behavior of stocks results in a 3% larger growth on average than the overall market within a 3-month time period, as the out-of-sample test suggests.