 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
Effective Large Language Model Debugging with Best-first Tree Search
Jul 26, 2024



Large Language Models (LLMs) show promise in code generation tasks. However, their code-writing abilities are often limited in scope: while they can successfully implement simple functions, they struggle with more complex tasks. A fundamental difference with how an LLM writes code, compared to a human programmer, is that it cannot consistently spot and fix bugs. Debugging is a crucial skill for programmers and it enables iterative code refinement towards a correct implementation. In this work, we propose a novel algorithm to enable LLMs to debug their code via self-reflection and search where a model attempts to identify its previous mistakes. Our key contributions are 1) a best-first tree search algorithm with self-reflections (BESTER) that achieves state-of-the-art Pass@1 in three code generation benchmarks. BESTER maintains its superiority when we measure pass rates taking into account additional inference costs incurred by tree search. 2) A novel interpretability study on what self-reflections attend to in buggy programs and how they impact bug fixes, which provides a deeper understanding of the debugging process. 3) An extensive study on when self-reflections are effective in finding bugs.
CircuitVAE: Efficient and Scalable Latent Circuit Optimization
Jun 13, 2024
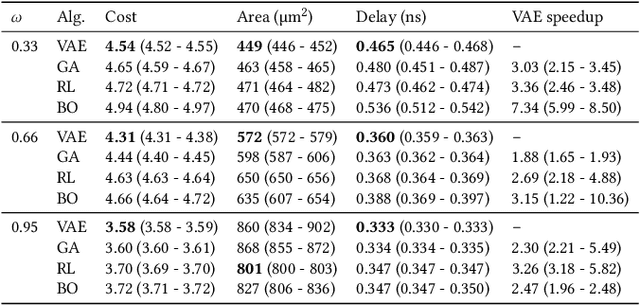
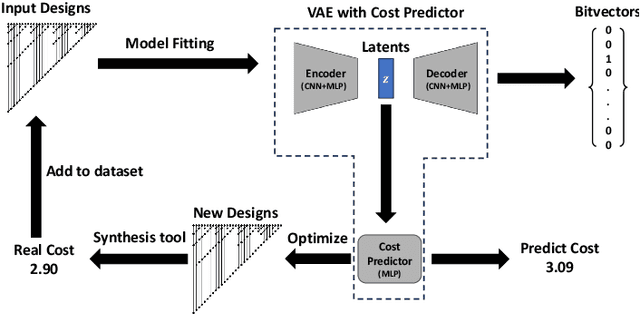
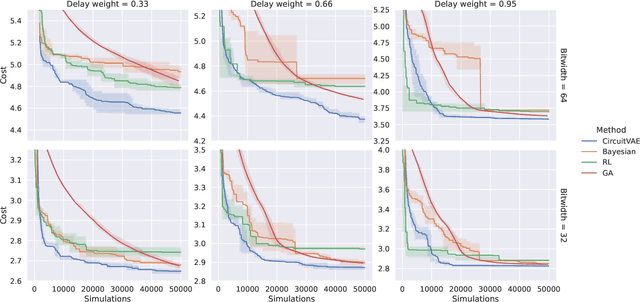
Automatically designing fast and space-efficient digital circuits is challenging because circuits are discrete, must exactly implement the desired logic, and are costly to simulate. We address these challenges with CircuitVAE, a search algorithm that embeds computation graphs in a continuous space and optimizes a learned surrogate of physical simulation by gradient descent. By carefully controlling overfitting of the simulation surrogate and ensuring diverse exploration, our algorithm is highly sample-efficient, yet gracefully scales to large problem instances and high sample budgets. We test CircuitVAE by designing binary adders across a large range of sizes, IO timing constraints, and sample budgets. Our method excels at designing large circuits, where other algorithms struggle: compared to reinforcement learning and genetic algorithms, CircuitVAE typically finds 64-bit adders which are smaller and faster using less than half the sample budget. We also find CircuitVAE can design state-of-the-art adders in a real-world chip, demonstrating that our method can outperform commercial tools in a realistic setting.
NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
May 27, 2024



Decoder-only large language model (LLM)-based embedding models are beginning to outperform BERT or T5-based embedding models in general-purpose text embedding tasks, including dense vector-based retrieval. In this work, we introduce the NV-Embed model with a variety of architectural designs and training procedures to significantly enhance the performance of LLM as a versatile embedding model, while maintaining its simplicity and reproducibility. For model architecture, we propose a latent attention layer to obtain pooled embeddings, which consistently improves retrieval and downstream task accuracy compared to mean pooling or using the last <EOS> token embedding from LLMs. To enhance representation learning, we remove the causal attention mask of LLMs during contrastive training. For model training, we introduce a two-stage contrastive instruction-tuning method. It first applies contrastive training with instructions on retrieval datasets, utilizing in-batch negatives and curated hard negative examples. At stage-2, it blends various non-retrieval datasets into instruction tuning, which not only enhances non-retrieval task accuracy but also improves retrieval performance. Combining these techniques, our NV-Embed model, using only publicly available data, has achieved a record-high score of 69.32, ranking No. 1 on the Massive Text Embedding Benchmark (MTEB) (as of May 24, 2024), with 56 tasks, encompassing retrieval, reranking, classification, clustering, and semantic textual similarity tasks. Notably, our model also attains the highest score of 59.36 on 15 retrieval tasks in the MTEB benchmark (also known as BEIR). We will open-source the model at: https://huggingface.co/nvidia/NV-Embed-v1.
ChipNeMo: Domain-Adapted LLMs for Chip Design
Nov 13, 2023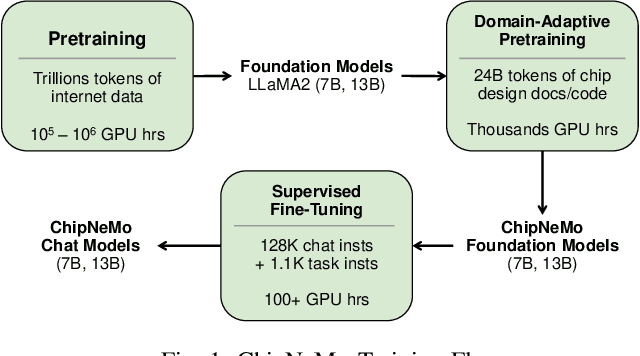
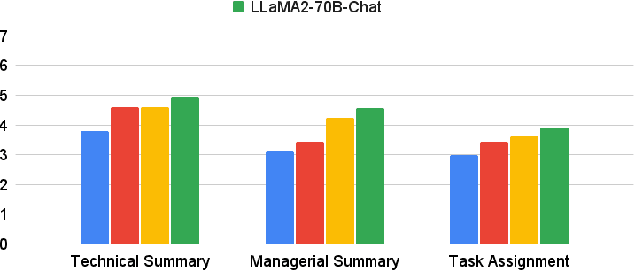
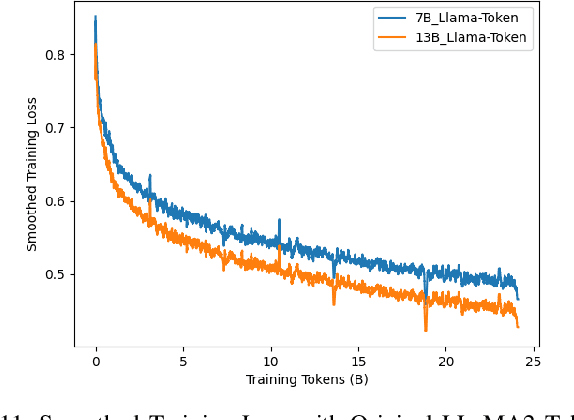
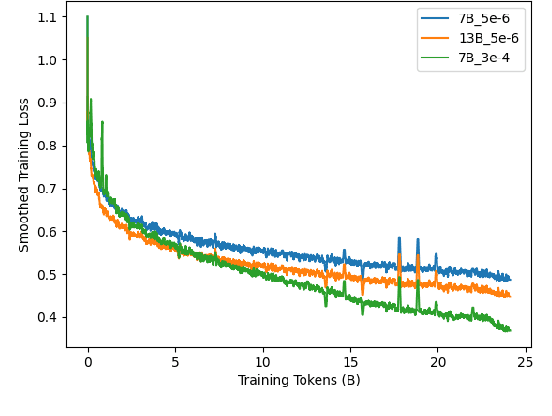
ChipNeMo aims to explore the applications of large language models (LLMs) for industrial chip design. Instead of directly deploying off-the-shelf commercial or open-source LLMs, we instead adopt the following domain adaptation techniques: custom tokenizers, domain-adaptive continued pretraining, supervised fine-tuning (SFT) with domain-specific instructions, and domain-adapted retrieval models. We evaluate these methods on three selected LLM applications for chip design: an engineering assistant chatbot, EDA script generation, and bug summarization and analysis. Our results show that these domain adaptation techniques enable significant LLM performance improvements over general-purpose base models across the three evaluated applications, enabling up to 5x model size reduction with similar or better performance on a range of design tasks. Our findings also indicate that there's still room for improvement between our current results and ideal outcomes. We believe that further investigation of domain-adapted LLM approaches will help close this gap in the future.
PrefixRL: Optimization of Parallel Prefix Circuits using Deep Reinforcement Learning
May 14, 2022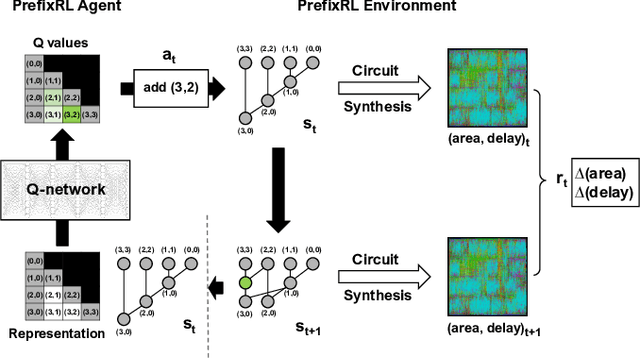
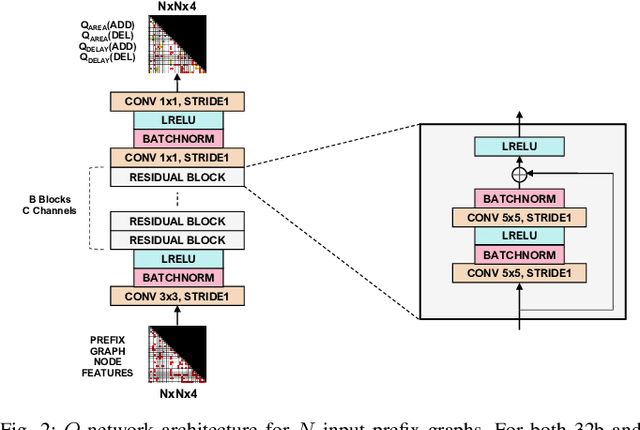
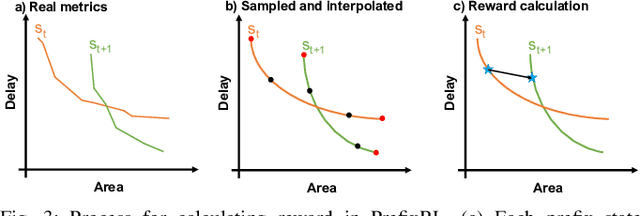
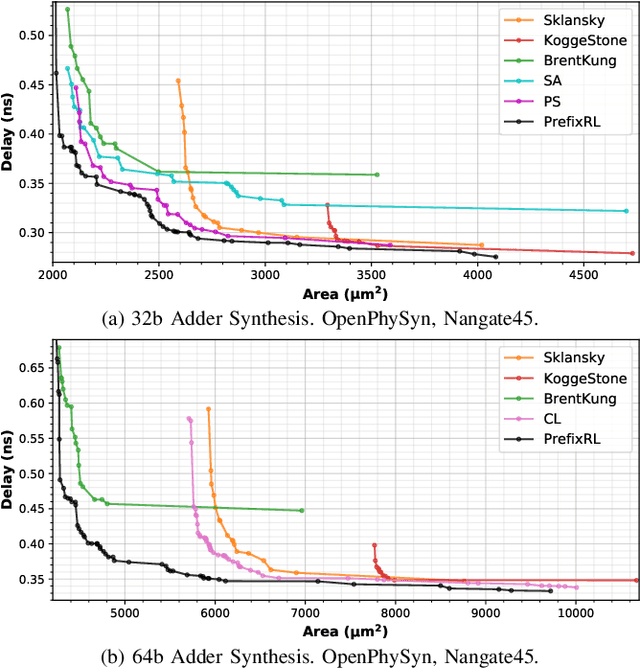
In this work, we present a reinforcement learning (RL) based approach to designing parallel prefix circuits such as adders or priority encoders that are fundamental to high-performance digital design. Unlike prior methods, our approach designs solutions tabula rasa purely through learning with synthesis in the loop. We design a grid-based state-action representation and an RL environment for constructing legal prefix circuits. Deep Convolutional RL agents trained on this environment produce prefix adder circuits that Pareto-dominate existing baselines with up to 16.0% and 30.2% lower area for the same delay in the 32b and 64b settings respectively. We observe that agents trained with open-source synthesis tools and cell library can design adder circuits that achieve lower area and delay than commercial tool adders in an industrial cell library.
* Copyright 2021 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Generative Adversarial Simulator
Nov 23, 2020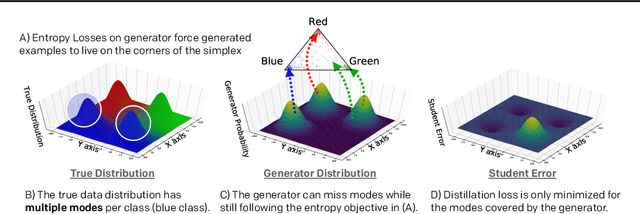
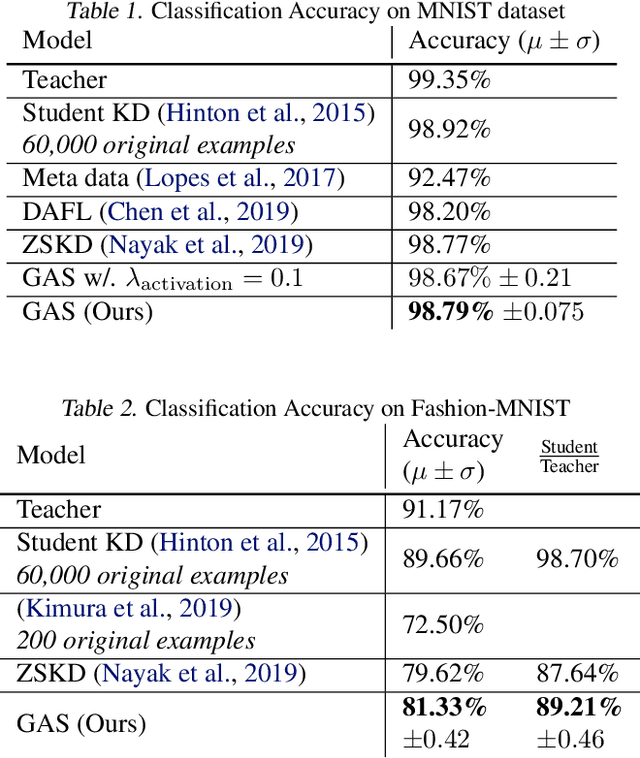

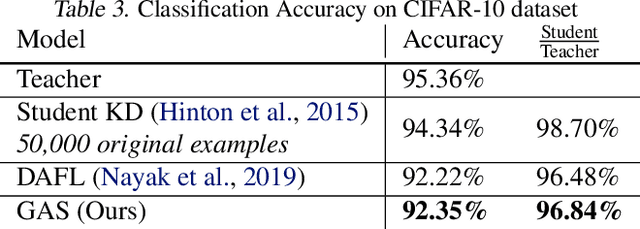
Knowledge distillation between machine learning models has opened many new avenues for parameter count reduction, performance improvements, or amortizing training time when changing architectures between the teacher and student network. In the case of reinforcement learning, this technique has also been applied to distill teacher policies to students. Until now, policy distillation required access to a simulator or real world trajectories. In this paper we introduce a simulator-free approach to knowledge distillation in the context of reinforcement learning. A key challenge is having the student learn the multiplicity of cases that correspond to a given action. While prior work has shown that data-free knowledge distillation is possible with supervised learning models by generating synthetic examples, these approaches to are vulnerable to only producing a single prototype example for each class. We propose an extension to explicitly handle multiple observations per output class that seeks to find as many exemplars as possible for a given output class by reinitializing our data generator and making use of an adversarial loss. To the best of our knowledge, this is the first demonstration of simulator-free knowledge distillation between a teacher and a student policy. This new approach improves over the state of the art on data-free learning of student networks on benchmark datasets (MNIST, Fashion-MNIST, CIFAR-10), and we also demonstrate that it specifically tackles issues with multiple input modes. We also identify open problems when distilling agents trained in high dimensional environments such as Pong, Breakout, or Seaquest.
Long-Term Planning and Situational Awareness in OpenAI Five
Dec 13, 2019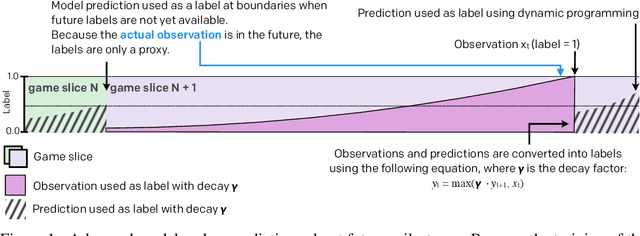
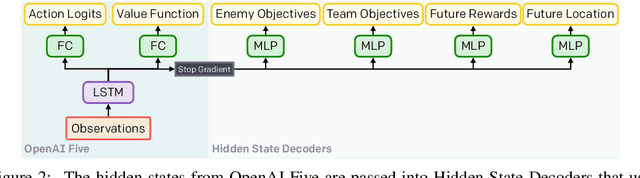
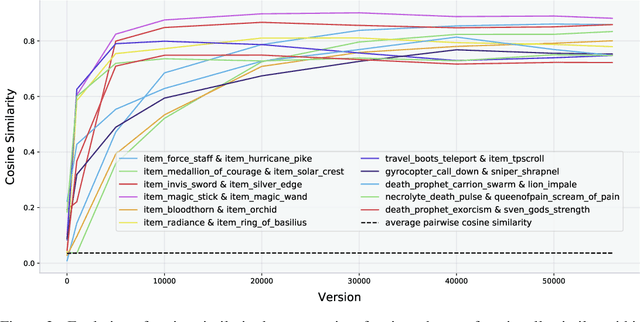
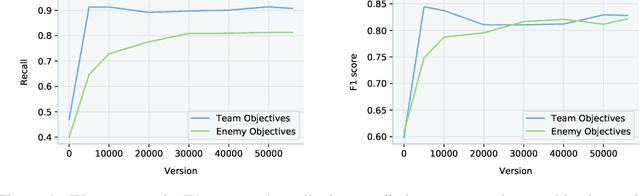
Understanding how knowledge about the world is represented within model-free deep reinforcement learning methods is a major challenge given the black box nature of its learning process within high-dimensional observation and action spaces. AlphaStar and OpenAI Five have shown that agents can be trained without any explicit hierarchical macro-actions to reach superhuman skill in games that require taking thousands of actions before reaching the final goal. Assessing the agent's plans and game understanding becomes challenging given the lack of hierarchy or explicit representations of macro-actions in these models, coupled with the incomprehensible nature of the internal representations. In this paper, we study the distributed representations learned by OpenAI Five to investigate how game knowledge is gradually obtained over the course of training. We also introduce a general technique for learning a model from the agent's hidden states to identify the formation of plans and subgoals. We show that the agent can learn situational similarity across actions, and find evidence of planning towards accomplishing subgoals minutes before they are executed. We perform a qualitative analysis of these predictions during the games against the DotA 2 world champions OG in April 2019.
Neural Network Surgery with Sets
Dec 13, 2019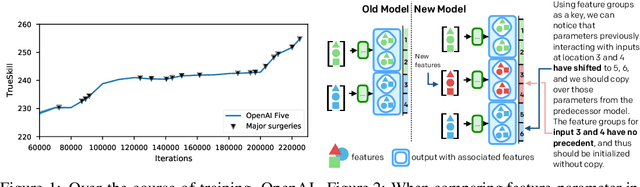
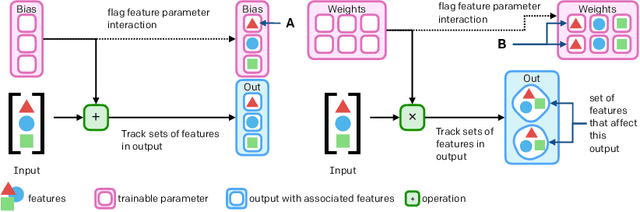

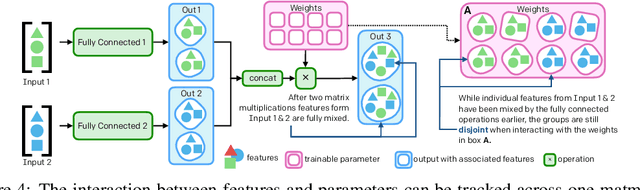
The cost to train machine learning models has been increasing exponentially, making exploration and research into the correct features and architecture a costly or intractable endeavor at scale. However, using a technique named "surgery" OpenAI Five was continuously trained to play the game DotA 2 over the course of 10 months through 20 major changes in features and architecture. Surgery transfers trained weights from one network to another after a selection process to determine which sections of the model are unchanged and which must be re-initialized. In the past, the selection process relied on heuristics, manual labor, or pre-existing boundaries in the structure of the model, limiting the ability to salvage experiments after modifications of the feature set or input reorderings. We propose a solution to automatically determine which components of a neural network model should be salvaged and which require retraining. We achieve this by allowing the model to operate over discrete sets of features and use set-based operations to determine the exact relationship between inputs and outputs, and how they change across tweaks in model architecture. In this paper, we introduce the methodology for enabling neural networks to operate on sets, derive two methods for detecting feature-parameter interaction maps, and show their equivalence. We empirically validate that we can surgery weights across feature and architecture changes to the OpenAI Five model.