 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining LLMs with Fault Tolerant HSDP on 100,000 GPUs
Jan 30, 2026Large-scale training systems typically use synchronous training, requiring all GPUs to be healthy simultaneously. In our experience training on O(100K) GPUs, synchronous training results in a low efficiency due to frequent failures and long recovery time. To address this problem, we propose a novel training paradigm, Fault Tolerant Hybrid-Shared Data Parallelism (FT-HSDP). FT-HSDP uses data parallel replicas as units of fault tolerance. When failures occur, only a single data-parallel replica containing the failed GPU or server is taken offline and restarted, while the other replicas continue training. To realize this idea at scale, FT-HSDP incorporates several techniques: 1) We introduce a Fault Tolerant All Reduce (FTAR) protocol for gradient exchange across data parallel replicas. FTAR relies on the CPU to drive the complex control logic for tasks like adding or removing participants dynamically, and relies on GPU to perform data transfer for best performance. 2) We introduce a non-blocking catch-up protocol, allowing a recovering replica to join training with minimal stall. Compared with fully synchronous training at O(100K) GPUs, FT-HSDP can reduce the stall time due to failure recovery from 10 minutes to 3 minutes, increasing effective training time from 44\% to 80\%. We further demonstrate that FT-HSDP's asynchronous recovery does not bring any meaning degradation to the accuracy of the result model.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Compute Optimal Scaling of Skills: Knowledge vs Reasoning
Mar 13, 2025Scaling laws are a critical component of the LLM development pipeline, most famously as a way to forecast training decisions such as 'compute-optimally' trading-off parameter count and dataset size, alongside a more recent growing list of other crucial decisions. In this work, we ask whether compute-optimal scaling behaviour can be skill-dependent. In particular, we examine knowledge and reasoning-based skills such as knowledge-based QA and code generation, and we answer this question in the affirmative: $\textbf{scaling laws are skill-dependent}$. Next, to understand whether skill-dependent scaling is an artefact of the pretraining datamix, we conduct an extensive ablation of different datamixes and find that, also when correcting for datamix differences, $\textbf{knowledge and code exhibit fundamental differences in scaling behaviour}$. We conclude with an analysis of how our findings relate to standard compute-optimal scaling using a validation set, and find that $\textbf{a misspecified validation set can impact compute-optimal parameter count by nearly 50%,}$ depending on its skill composition.
Correlating and Predicting Human Evaluations of Language Models from Natural Language Processing Benchmarks
Feb 24, 2025The explosion of high-performing conversational language models (LMs) has spurred a shift from classic natural language processing (NLP) benchmarks to expensive, time-consuming and noisy human evaluations - yet the relationship between these two evaluation strategies remains hazy. In this paper, we conduct a large-scale study of four Chat Llama 2 models, comparing their performance on 160 standard NLP benchmarks (e.g., MMLU, ARC, BIG-Bench Hard) against extensive human preferences on more than 11k single-turn and 2k multi-turn dialogues from over 2k human annotators. Our findings are striking: most NLP benchmarks strongly correlate with human evaluations, suggesting that cheaper, automated metrics can serve as surprisingly reliable predictors of human preferences. Three human evaluations, such as adversarial dishonesty and safety, are anticorrelated with NLP benchmarks, while two are uncorrelated. Moreover, through overparameterized linear regressions, we show that NLP scores can accurately predict human evaluations across different model scales, offering a path to reduce costly human annotation without sacrificing rigor. Overall, our results affirm the continued value of classic benchmarks and illuminate how to harness them to anticipate real-world user satisfaction - pointing to how NLP benchmarks can be leveraged to meet evaluation needs of our new era of conversational AI.
Law of the Weakest Link: Cross Capabilities of Large Language Models
Sep 30, 2024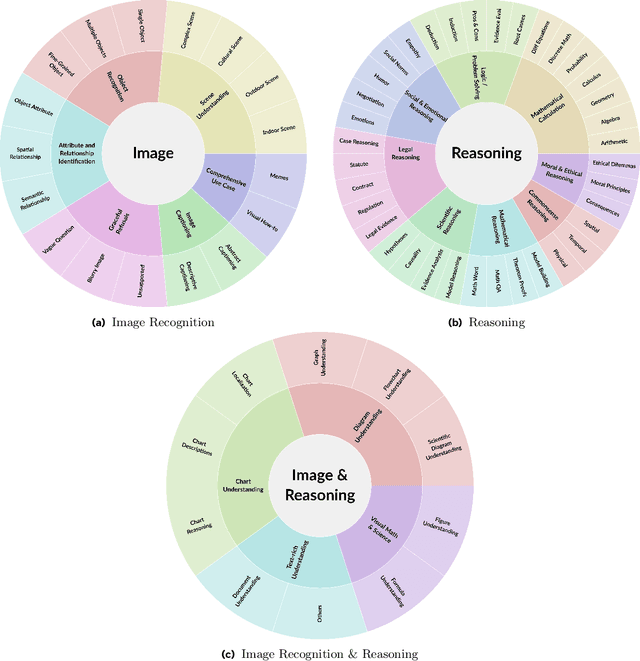
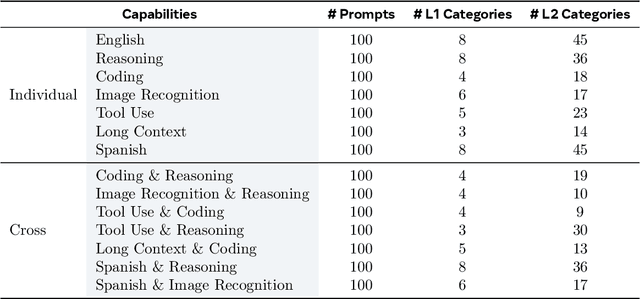
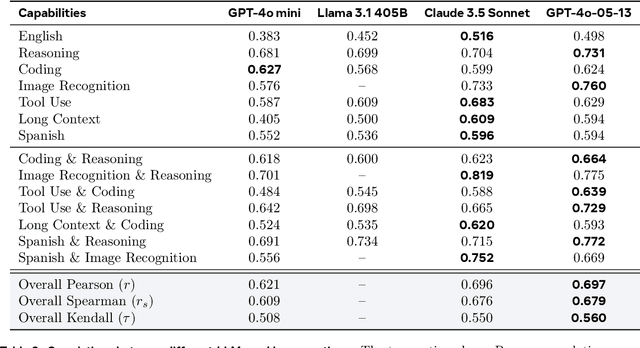
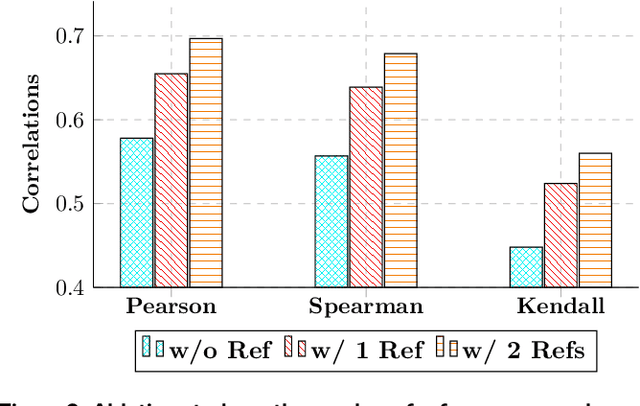
The development and evaluation of Large Language Models (LLMs) have largely focused on individual capabilities. However, this overlooks the intersection of multiple abilities across different types of expertise that are often required for real-world tasks, which we term cross capabilities. To systematically explore this concept, we first define seven core individual capabilities and then pair them to form seven common cross capabilities, each supported by a manually constructed taxonomy. Building on these definitions, we introduce CrossEval, a benchmark comprising 1,400 human-annotated prompts, with 100 prompts for each individual and cross capability. To ensure reliable evaluation, we involve expert annotators to assess 4,200 model responses, gathering 8,400 human ratings with detailed explanations to serve as reference examples. Our findings reveal that, in both static evaluations and attempts to enhance specific abilities, current LLMs consistently exhibit the "Law of the Weakest Link," where cross-capability performance is significantly constrained by the weakest component. Specifically, across 58 cross-capability scores from 17 models, 38 scores are lower than all individual capabilities, while 20 fall between strong and weak, but closer to the weaker ability. These results highlight the under-performance of LLMs in cross-capability tasks, making the identification and improvement of the weakest capabilities a critical priority for future research to optimize performance in complex, multi-dimensional scenarios.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Quantifying Variance in Evaluation Benchmarks
Jun 14, 2024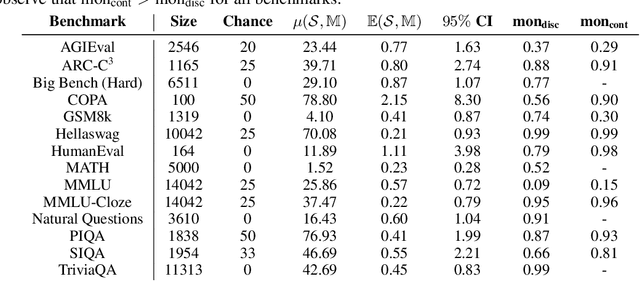
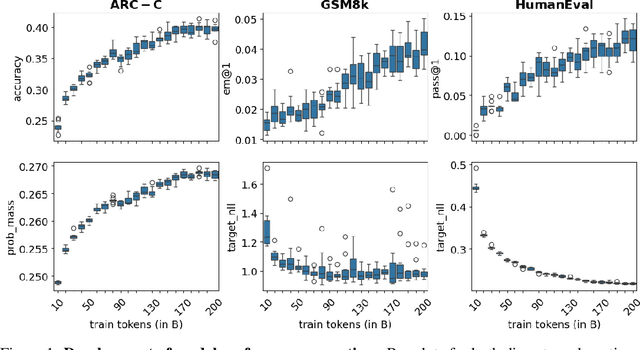
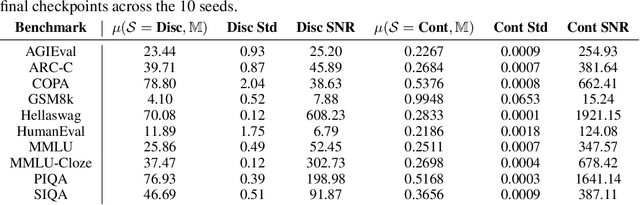
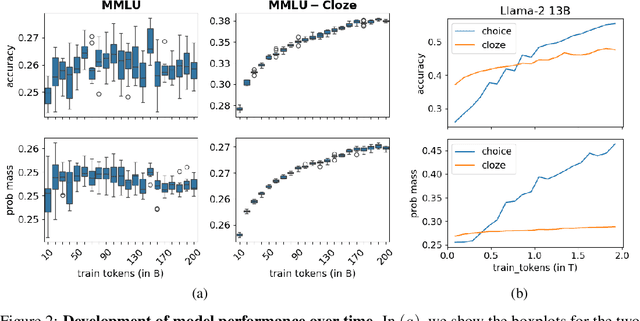
Evaluation benchmarks are the cornerstone of measuring capabilities of large language models (LLMs), as well as driving progress in said capabilities. Originally designed to make claims about capabilities (or lack thereof) in fully pretrained models, evaluation benchmarks are now also extensively used to decide between various training choices. Despite this widespread usage, we rarely quantify the variance in our evaluation benchmarks, which dictates whether differences in performance are meaningful. Here, we define and measure a range of metrics geared towards measuring variance in evaluation benchmarks, including seed variance across initialisations, and monotonicity during training. By studying a large number of models -- both openly available and pretrained from scratch -- we provide empirical estimates for a variety of variance metrics, with considerations and recommendations for practitioners. We also evaluate the utility and tradeoffs of continuous versus discrete performance measures and explore options for better understanding and reducing this variance. We find that simple changes, such as framing choice tasks (like MMLU) as completion tasks, can often reduce variance for smaller scale ($\sim$7B) models, while more involved methods inspired from human testing literature (such as item analysis and item response theory) struggle to meaningfully reduce variance. Overall, our work provides insights into variance in evaluation benchmarks, suggests LM-specific techniques to reduce variance, and more generally encourages practitioners to carefully factor in variance when comparing models.
Effective Long-Context Scaling of Foundation Models
Sep 27, 2023



We present a series of long-context LLMs that support effective context windows of up to 32,768 tokens. Our model series are built through continual pretraining from Llama 2 with longer training sequences and on a dataset where long texts are upsampled. We perform extensive evaluation on language modeling, synthetic context probing tasks, and a wide range of research benchmarks. On research benchmarks, our models achieve consistent improvements on most regular tasks and significant improvements on long-context tasks over Llama 2. Notably, with a cost-effective instruction tuning procedure that does not require human-annotated long instruction data, the 70B variant can already surpass gpt-3.5-turbo-16k's overall performance on a suite of long-context tasks. Alongside these results, we provide an in-depth analysis on the individual components of our method. We delve into Llama's position encodings and discuss its limitation in modeling long dependencies. We also examine the impact of various design choices in the pretraining process, including the data mix and the training curriculum of sequence lengths -- our ablation experiments suggest that having abundant long texts in the pretrain dataset is not the key to achieving strong performance, and we empirically verify that long context continual pretraining is more efficient and similarly effective compared to pretraining from scratch with long sequences.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
A Theory on Adam Instability in Large-Scale Machine Learning
Apr 25, 2023



We present a theory for the previously unexplained divergent behavior noticed in the training of large language models. We argue that the phenomenon is an artifact of the dominant optimization algorithm used for training, called Adam. We observe that Adam can enter a state in which the parameter update vector has a relatively large norm and is essentially uncorrelated with the direction of descent on the training loss landscape, leading to divergence. This artifact is more likely to be observed in the training of a deep model with a large batch size, which is the typical setting of large-scale language model training. To argue the theory, we present observations from the training runs of the language models of different scales: 7 billion, 30 billion, 65 billion, and 546 billion parameters.