 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
The Belebele Benchmark: a Parallel Reading Comprehension Dataset in 122 Language Variants
Aug 31, 2023



We present Belebele, a multiple-choice machine reading comprehension (MRC) dataset spanning 122 language variants. Significantly expanding the language coverage of natural language understanding (NLU) benchmarks, this dataset enables the evaluation of text models in high-, medium-, and low-resource languages. Each question is based on a short passage from the Flores-200 dataset and has four multiple-choice answers. The questions were carefully curated to discriminate between models with different levels of general language comprehension. The English dataset on its own proves difficult enough to challenge state-of-the-art language models. Being fully parallel, this dataset enables direct comparison of model performance across all languages. We use this dataset to evaluate the capabilities of multilingual masked language models (MLMs) and large language models (LLMs). We present extensive results and find that despite significant cross-lingual transfer in English-centric LLMs, much smaller MLMs pretrained on balanced multilingual data still understand far more languages. We also observe that larger vocabulary size and conscious vocabulary construction correlate with better performance on low-resource languages. Overall, Belebele opens up new avenues for evaluating and analyzing the multilingual capabilities of NLP systems.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
A Theory on Adam Instability in Large-Scale Machine Learning
Apr 25, 2023



We present a theory for the previously unexplained divergent behavior noticed in the training of large language models. We argue that the phenomenon is an artifact of the dominant optimization algorithm used for training, called Adam. We observe that Adam can enter a state in which the parameter update vector has a relatively large norm and is essentially uncorrelated with the direction of descent on the training loss landscape, leading to divergence. This artifact is more likely to be observed in the training of a deep model with a large batch size, which is the typical setting of large-scale language model training. To argue the theory, we present observations from the training runs of the language models of different scales: 7 billion, 30 billion, 65 billion, and 546 billion parameters.
LLaMA: Open and Efficient Foundation Language Models
Feb 27, 2023



We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets. In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B. We release all our models to the research community.
Text-To-4D Dynamic Scene Generation
Jan 26, 2023



We present MAV3D (Make-A-Video3D), a method for generating three-dimensional dynamic scenes from text descriptions. Our approach uses a 4D dynamic Neural Radiance Field (NeRF), which is optimized for scene appearance, density, and motion consistency by querying a Text-to-Video (T2V) diffusion-based model. The dynamic video output generated from the provided text can be viewed from any camera location and angle, and can be composited into any 3D environment. MAV3D does not require any 3D or 4D data and the T2V model is trained only on Text-Image pairs and unlabeled videos. We demonstrate the effectiveness of our approach using comprehensive quantitative and qualitative experiments and show an improvement over previously established internal baselines. To the best of our knowledge, our method is the first to generate 3D dynamic scenes given a text description.
XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models
Jan 25, 2023



Large multilingual language models typically rely on a single vocabulary shared across 100+ languages. As these models have increased in parameter count and depth, vocabulary size has remained largely unchanged. This vocabulary bottleneck limits the representational capabilities of multilingual models like XLM-R. In this paper, we introduce a new approach for scaling to very large multilingual vocabularies by de-emphasizing token sharing between languages with little lexical overlap and assigning vocabulary capacity to achieve sufficient coverage for each individual language. Tokenizations using our vocabulary are typically more semantically meaningful and shorter compared to XLM-R. Leveraging this improved vocabulary, we train XLM-V, a multilingual language model with a one million token vocabulary. XLM-V outperforms XLM-R on every task we tested on ranging from natural language inference (XNLI), question answering (MLQA, XQuAD, TyDiQA), and named entity recognition (WikiAnn) to low-resource tasks (Americas NLI, MasakhaNER).
Scaling Laws for Generative Mixed-Modal Language Models
Jan 10, 2023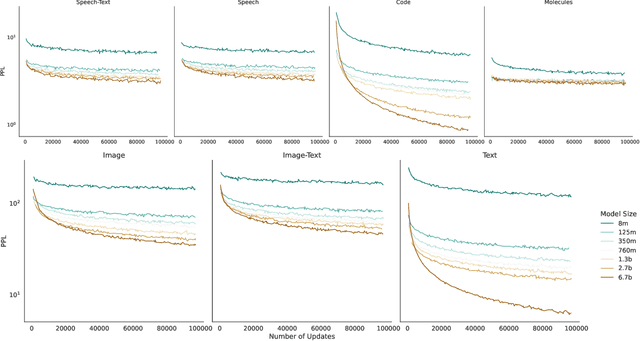
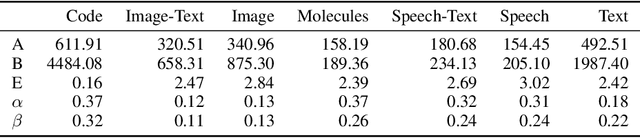
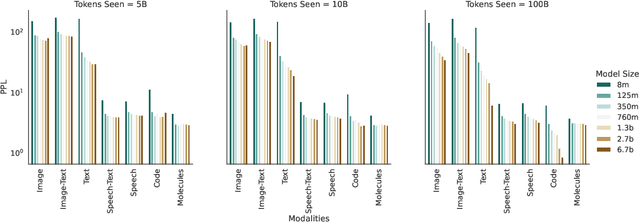
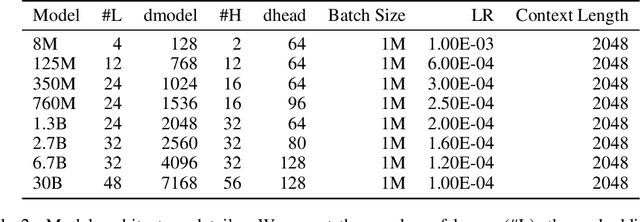
Generative language models define distributions over sequences of tokens that can represent essentially any combination of data modalities (e.g., any permutation of image tokens from VQ-VAEs, speech tokens from HuBERT, BPE tokens for language or code, and so on). To better understand the scaling properties of such mixed-modal models, we conducted over 250 experiments using seven different modalities and model sizes ranging from 8 million to 30 billion, trained on 5-100 billion tokens. We report new mixed-modal scaling laws that unify the contributions of individual modalities and the interactions between them. Specifically, we explicitly model the optimal synergy and competition due to data and model size as an additive term to previous uni-modal scaling laws. We also find four empirical phenomena observed during the training, such as emergent coordinate-ascent style training that naturally alternates between modalities, guidelines for selecting critical hyper-parameters, and connections between mixed-modal competition and training stability. Finally, we test our scaling law by training a 30B speech-text model, which significantly outperforms the corresponding unimodal models. Overall, our research provides valuable insights into the design and training of mixed-modal generative models, an important new class of unified models that have unique distributional properties.
BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage
Aug 10, 2022
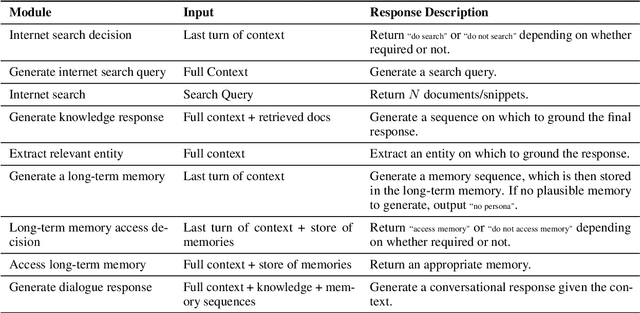
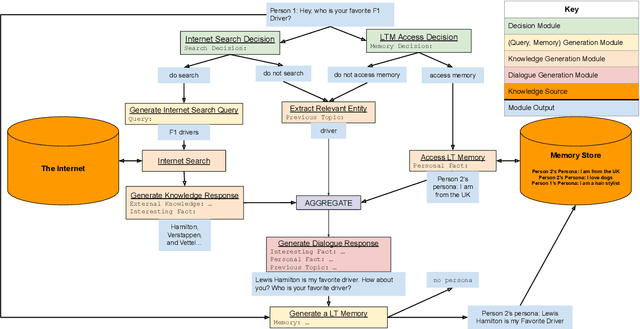
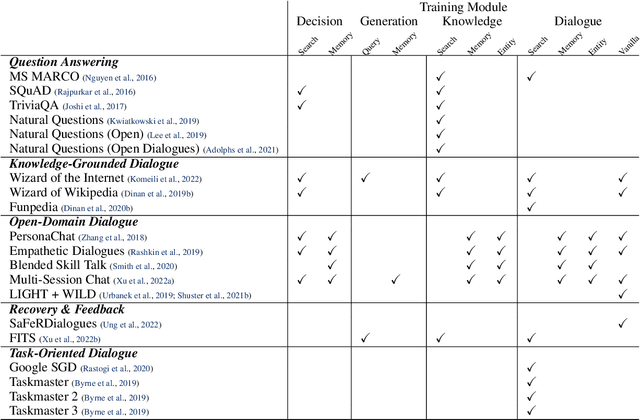
We present BlenderBot 3, a 175B parameter dialogue model capable of open-domain conversation with access to the internet and a long-term memory, and having been trained on a large number of user defined tasks. We release both the model weights and code, and have also deployed the model on a public web page to interact with organic users. This technical report describes how the model was built (architecture, model and training scheme), and details of its deployment, including safety mechanisms. Human evaluations show its superiority to existing open-domain dialogue agents, including its predecessors (Roller et al., 2021; Komeili et al., 2022). Finally, we detail our plan for continual learning using the data collected from deployment, which will also be publicly released. The goal of this research program is thus to enable the community to study ever-improving responsible agents that learn through interaction.