 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Design Space of Transition Matching
Dec 13, 2025


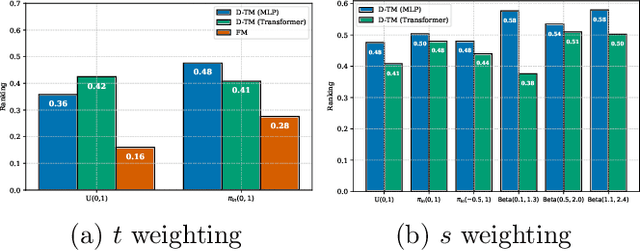
Transition Matching (TM) is an emerging paradigm for generative modeling that generalizes diffusion and flow-matching models as well as continuous-state autoregressive models. TM, similar to previous paradigms, gradually transforms noise samples to data samples, however it uses a second ``internal'' generative model to implement the transition steps, making the transitions more expressive compared to diffusion and flow models. To make this paradigm tractable, TM employs a large backbone network and a smaller "head" module to efficiently execute the generative transition step. In this work, we present a large-scale, systematic investigation into the design, training and sampling of the head in TM frameworks, focusing on its time-continuous bidirectional variant. Through comprehensive ablations and experimentation involving training 56 different 1.7B text-to-image models (resulting in 549 unique evaluations) we evaluate the affect of the head module architecture and modeling during training as-well as a useful family of stochastic TM samplers. We analyze the impact on generation quality, training, and inference efficiency. We find that TM with an MLP head, trained with a particular time weighting and sampled with high frequency sampler provides best ranking across all metrics reaching state-of-the-art among all tested baselines, while Transformer head with sequence scaling and low frequency sampling is a runner up excelling at image aesthetics. Lastly, we believe the experiments presented highlight the design aspects that are likely to provide most quality and efficiency gains, while at the same time indicate what design choices are not likely to provide further gains.
Corrector Sampling in Language Models
Jun 06, 2025



Autoregressive language models accumulate errors due to their fixed, irrevocable left-to-right token generation. To address this, we propose a new sampling method called Resample-Previous-Tokens (RPT). RPT mitigates error accumulation by iteratively revisiting and potentially replacing tokens in a window of previously generated text. This method can be integrated into existing autoregressive models, preserving their next-token-prediction quality and speed. Fine-tuning a pretrained 8B parameter model with RPT for only 100B resulted in ~10% relative improvements on reasoning and coding benchmarks compared to the standard sampling.
VideoJAM: Joint Appearance-Motion Representations for Enhanced Motion Generation in Video Models
Feb 04, 2025


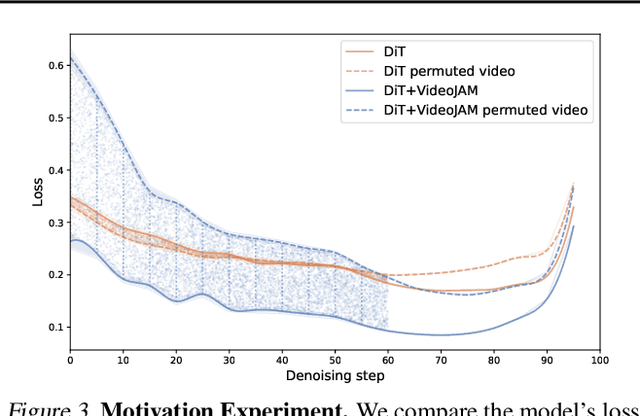
Despite tremendous recent progress, generative video models still struggle to capture real-world motion, dynamics, and physics. We show that this limitation arises from the conventional pixel reconstruction objective, which biases models toward appearance fidelity at the expense of motion coherence. To address this, we introduce VideoJAM, a novel framework that instills an effective motion prior to video generators, by encouraging the model to learn a joint appearance-motion representation. VideoJAM is composed of two complementary units. During training, we extend the objective to predict both the generated pixels and their corresponding motion from a single learned representation. During inference, we introduce Inner-Guidance, a mechanism that steers the generation toward coherent motion by leveraging the model's own evolving motion prediction as a dynamic guidance signal. Notably, our framework can be applied to any video model with minimal adaptations, requiring no modifications to the training data or scaling of the model. VideoJAM achieves state-of-the-art performance in motion coherence, surpassing highly competitive proprietary models while also enhancing the perceived visual quality of the generations. These findings emphasize that appearance and motion can be complementary and, when effectively integrated, enhance both the visual quality and the coherence of video generation. Project website: https://hila-chefer.github.io/videojam-paper.github.io/
GOProteinGNN: Leveraging Protein Knowledge Graphs for Protein Representation Learning
Jul 31, 2024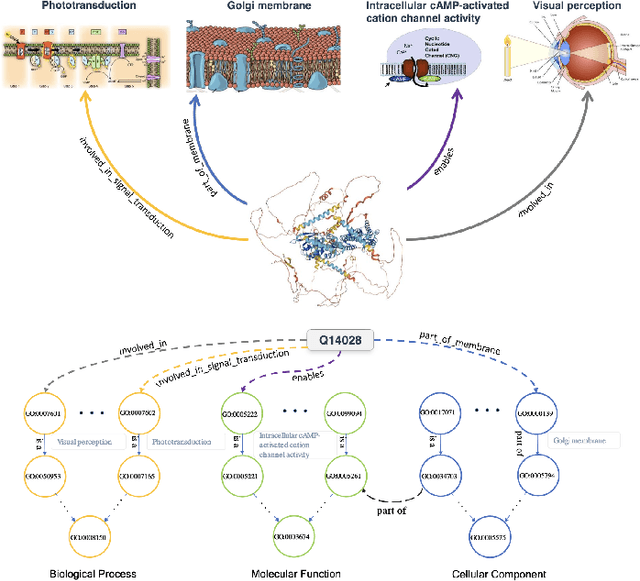
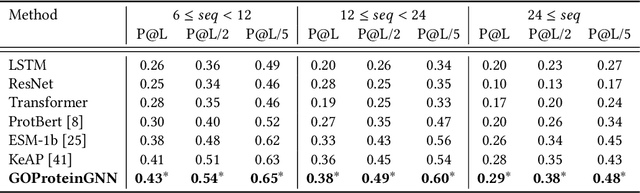
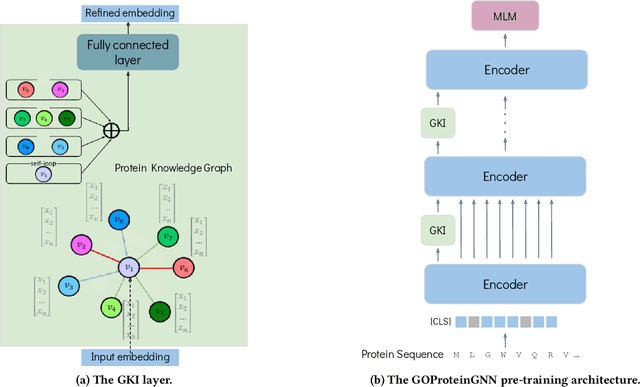
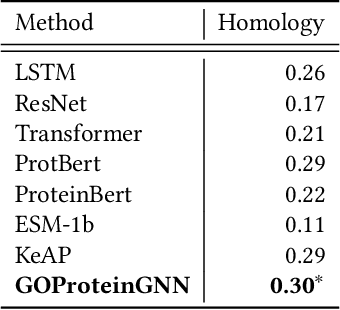
Proteins play a vital role in biological processes and are indispensable for living organisms. Accurate representation of proteins is crucial, especially in drug development. Recently, there has been a notable increase in interest in utilizing machine learning and deep learning techniques for unsupervised learning of protein representations. However, these approaches often focus solely on the amino acid sequence of proteins and lack factual knowledge about proteins and their interactions, thus limiting their performance. In this study, we present GOProteinGNN, a novel architecture that enhances protein language models by integrating protein knowledge graph information during the creation of amino acid level representations. Our approach allows for the integration of information at both the individual amino acid level and the entire protein level, enabling a comprehensive and effective learning process through graph-based learning. By doing so, we can capture complex relationships and dependencies between proteins and their functional annotations, resulting in more robust and contextually enriched protein representations. Unlike previous fusion methods, GOProteinGNN uniquely learns the entire protein knowledge graph during training, which allows it to capture broader relational nuances and dependencies beyond mere triplets as done in previous work. We perform a comprehensive evaluation on several downstream tasks demonstrating that GOProteinGNN consistently outperforms previous methods, showcasing its effectiveness and establishing it as a state-of-the-art solution for protein representation learning.
Leveraging World Events to Predict E-Commerce Consumer Demand under Anomaly
May 22, 2024Consumer demand forecasting is of high importance for many e-commerce applications, including supply chain optimization, advertisement placement, and delivery speed optimization. However, reliable time series sales forecasting for e-commerce is difficult, especially during periods with many anomalies, as can often happen during pandemics, abnormal weather, or sports events. Although many time series algorithms have been applied to the task, prediction during anomalies still remains a challenge. In this work, we hypothesize that leveraging external knowledge found in world events can help overcome the challenge of prediction under anomalies. We mine a large repository of 40 years of world events and their textual representations. Further, we present a novel methodology based on transformers to construct an embedding of a day based on the relations of the day's events. Those embeddings are then used to forecast future consumer behavior. We empirically evaluate the methods over a large e-commerce products sales dataset, extracted from eBay, one of the world's largest online marketplaces. We show over numerous categories that our method outperforms state-of-the-art baselines during anomalies.
Video Editing via Factorized Diffusion Distillation
Mar 24, 2024We introduce Emu Video Edit (EVE), a model that establishes a new state-of-the art in video editing without relying on any supervised video editing data. To develop EVE we separately train an image editing adapter and a video generation adapter, and attach both to the same text-to-image model. Then, to align the adapters towards video editing we introduce a new unsupervised distillation procedure, Factorized Diffusion Distillation. This procedure distills knowledge from one or more teachers simultaneously, without any supervised data. We utilize this procedure to teach EVE to edit videos by jointly distilling knowledge to (i) precisely edit each individual frame from the image editing adapter, and (ii) ensure temporal consistency among the edited frames using the video generation adapter. Finally, to demonstrate the potential of our approach in unlocking other capabilities, we align additional combinations of adapters
Bespoke Non-Stationary Solvers for Fast Sampling of Diffusion and Flow Models
Mar 02, 2024This paper introduces Bespoke Non-Stationary (BNS) Solvers, a solver distillation approach to improve sample efficiency of Diffusion and Flow models. BNS solvers are based on a family of non-stationary solvers that provably subsumes existing numerical ODE solvers and consequently demonstrate considerable improvement in sample approximation (PSNR) over these baselines. Compared to model distillation, BNS solvers benefit from a tiny parameter space ($<$200 parameters), fast optimization (two orders of magnitude faster), maintain diversity of samples, and in contrast to previous solver distillation approaches nearly close the gap from standard distillation methods such as Progressive Distillation in the low-medium NFE regime. For example, BNS solver achieves 45 PSNR / 1.76 FID using 16 NFE in class-conditional ImageNet-64. We experimented with BNS solvers for conditional image generation, text-to-image generation, and text-2-audio generation showing significant improvement in sample approximation (PSNR) in all.
D-Flow: Differentiating through Flows for Controlled Generation
Feb 21, 2024



Taming the generation outcome of state of the art Diffusion and Flow-Matching (FM) models without having to re-train a task-specific model unlocks a powerful tool for solving inverse problems, conditional generation, and controlled generation in general. In this work we introduce D-Flow, a simple framework for controlling the generation process by differentiating through the flow, optimizing for the source (noise) point. We motivate this framework by our key observation stating that for Diffusion/FM models trained with Gaussian probability paths, differentiating through the generation process projects gradient on the data manifold, implicitly injecting the prior into the optimization process. We validate our framework on linear and non-linear controlled generation problems including: image and audio inverse problems and conditional molecule generation reaching state of the art performance across all.
Emu Edit: Precise Image Editing via Recognition and Generation Tasks
Nov 16, 2023



Instruction-based image editing holds immense potential for a variety of applications, as it enables users to perform any editing operation using a natural language instruction. However, current models in this domain often struggle with accurately executing user instructions. We present Emu Edit, a multi-task image editing model which sets state-of-the-art results in instruction-based image editing. To develop Emu Edit we train it to multi-task across an unprecedented range of tasks, such as region-based editing, free-form editing, and Computer Vision tasks, all of which are formulated as generative tasks. Additionally, to enhance Emu Edit's multi-task learning abilities, we provide it with learned task embeddings which guide the generation process towards the correct edit type. Both these elements are essential for Emu Edit's outstanding performance. Furthermore, we show that Emu Edit can generalize to new tasks, such as image inpainting, super-resolution, and compositions of editing tasks, with just a few labeled examples. This capability offers a significant advantage in scenarios where high-quality samples are scarce. Lastly, to facilitate a more rigorous and informed assessment of instructable image editing models, we release a new challenging and versatile benchmark that includes seven different image editing tasks.
Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning
Sep 05, 2023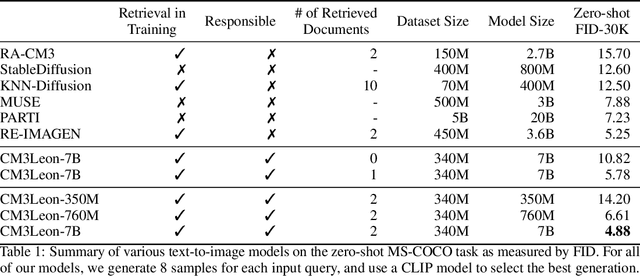

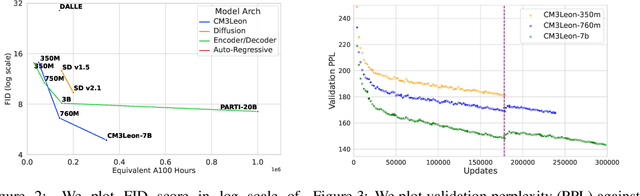

We present CM3Leon (pronounced "Chameleon"), a retrieval-augmented, token-based, decoder-only multi-modal language model capable of generating and infilling both text and images. CM3Leon uses the CM3 multi-modal architecture but additionally shows the extreme benefits of scaling up and tuning on more diverse instruction-style data. It is the first multi-modal model trained with a recipe adapted from text-only language models, including a large-scale retrieval-augmented pre-training stage and a second multi-task supervised fine-tuning (SFT) stage. It is also a general-purpose model that can do both text-to-image and image-to-text generation, allowing us to introduce self-contained contrastive decoding methods that produce high-quality outputs. Extensive experiments demonstrate that this recipe is highly effective for multi-modal models. CM3Leon achieves state-of-the-art performance in text-to-image generation with 5x less training compute than comparable methods (zero-shot MS-COCO FID of 4.88). After SFT, CM3Leon can also demonstrate unprecedented levels of controllability in tasks ranging from language-guided image editing to image-controlled generation and segmentation.