 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAltogether: Image Captioning via Re-aligning Alt-text
Oct 22, 2024



This paper focuses on creating synthetic data to improve the quality of image captions. Existing works typically have two shortcomings. First, they caption images from scratch, ignoring existing alt-text metadata, and second, lack transparency if the captioners' training data (e.g. GPT) is unknown. In this paper, we study a principled approach Altogether based on the key idea to edit and re-align existing alt-texts associated with the images. To generate training data, we perform human annotation where annotators start with the existing alt-text and re-align it to the image content in multiple rounds, consequently constructing captions with rich visual concepts. This differs from prior work that carries out human annotation as a one-time description task solely based on images and annotator knowledge. We train a captioner on this data that generalizes the process of re-aligning alt-texts at scale. Our results show our Altogether approach leads to richer image captions that also improve text-to-image generation and zero-shot image classification tasks.
Keep Guessing? When Considering Inference Scaling, Mind the Baselines
Oct 20, 2024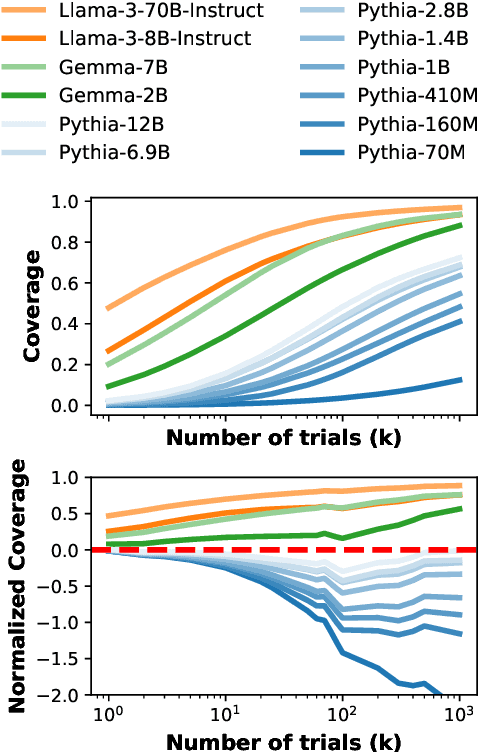
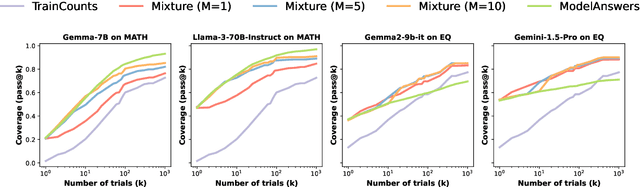

Scaling inference compute in large language models (LLMs) through repeated sampling consistently increases the coverage (fraction of problems solved) as the number of samples increases. We conjecture that this observed improvement is partially due to the answer distribution of standard evaluation benchmarks, which is skewed towards a relatively small set of common answers. To test this conjecture, we define a baseline that enumerates answers according to their prevalence in the training set. Experiments spanning two domains -- mathematical reasoning and factual knowledge -- reveal that this baseline outperforms repeated model sampling for some LLMs, while the coverage for others is on par with that of a mixture strategy that obtains $k$ answers by using only $10$ model samples and similarly guessing the remaining $k-10$ attempts via enumeration. Our baseline enables a more accurate measurement of how much repeated sampling improves coverage in such settings beyond prompt-agnostic guessing.
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Aug 20, 2024



We introduce Transfusion, a recipe for training a multi-modal model over discrete and continuous data. Transfusion combines the language modeling loss function (next token prediction) with diffusion to train a single transformer over mixed-modality sequences. We pretrain multiple Transfusion models up to 7B parameters from scratch on a mixture of text and image data, establishing scaling laws with respect to a variety of uni- and cross-modal benchmarks. Our experiments show that Transfusion scales significantly better than quantizing images and training a language model over discrete image tokens. By introducing modality-specific encoding and decoding layers, we can further improve the performance of Transfusion models, and even compress each image to just 16 patches. We further demonstrate that scaling our Transfusion recipe to 7B parameters and 2T multi-modal tokens produces a model that can generate images and text on a par with similar scale diffusion models and language models, reaping the benefits of both worlds.
Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length
Apr 12, 2024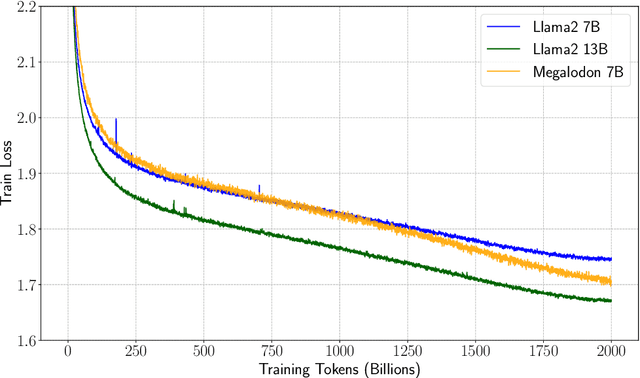
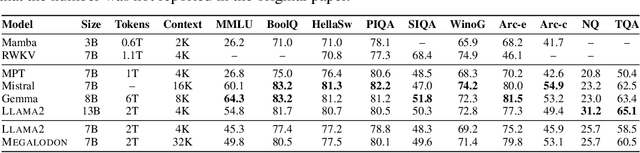
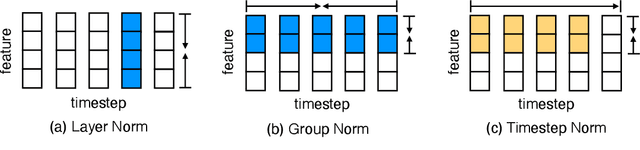
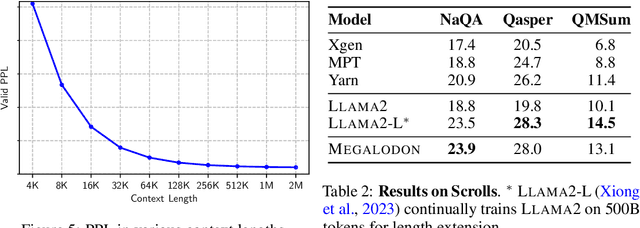
The quadratic complexity and weak length extrapolation of Transformers limits their ability to scale to long sequences, and while sub-quadratic solutions like linear attention and state space models exist, they empirically underperform Transformers in pretraining efficiency and downstream task accuracy. We introduce Megalodon, a neural architecture for efficient sequence modeling with unlimited context length. Megalodon inherits the architecture of Mega (exponential moving average with gated attention), and further introduces multiple technical components to improve its capability and stability, including complex exponential moving average (CEMA), timestep normalization layer, normalized attention mechanism and pre-norm with two-hop residual configuration. In a controlled head-to-head comparison with Llama2, Megalodon achieves better efficiency than Transformer in the scale of 7 billion parameters and 2 trillion training tokens. Megalodon reaches a training loss of 1.70, landing mid-way between Llama2-7B (1.75) and 13B (1.67). Code: https://github.com/XuezheMax/megalodon
Branch-Solve-Merge Improves Large Language Model Evaluation and Generation
Oct 23, 2023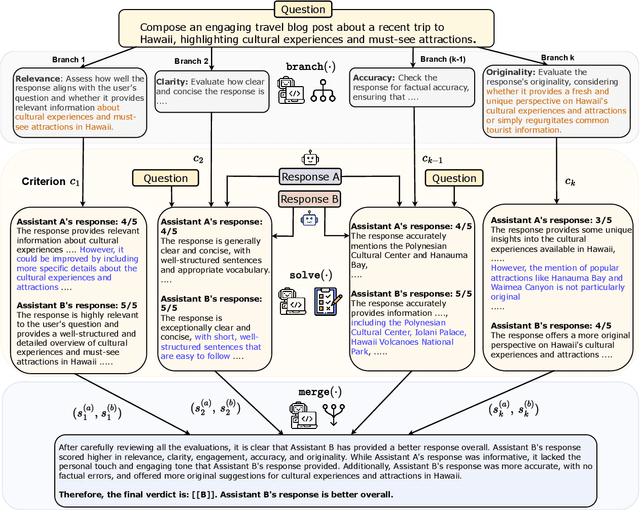
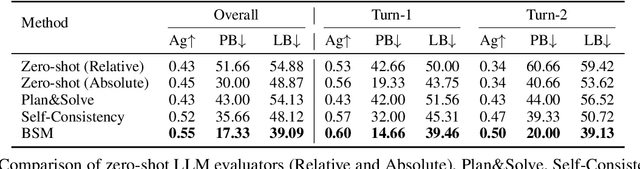

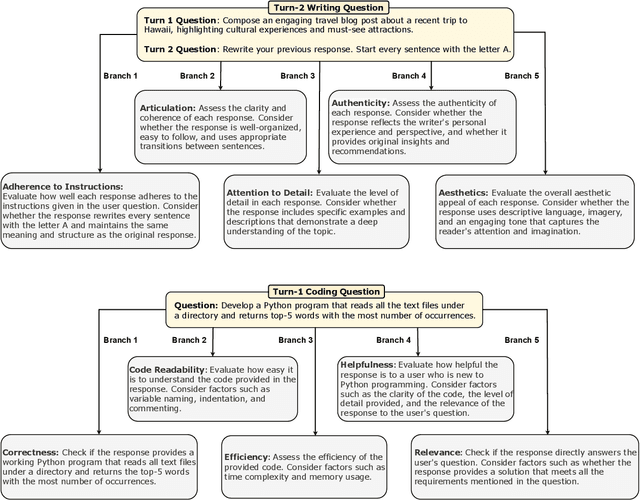
Large Language Models (LLMs) are frequently used for multi-faceted language generation and evaluation tasks that involve satisfying intricate user constraints or taking into account multiple aspects and criteria. However, their performance can fall short, due to the model's lack of coherence and inability to plan and decompose the problem. We propose Branch-Solve-Merge (BSM), a Large Language Model program (Schlag et al., 2023) for tackling such challenging natural language tasks. It consists of branch, solve, and merge modules that are parameterized with specific prompts to the base LLM. These three modules plan a decomposition of the task into multiple parallel sub-tasks, independently solve them, and fuse the solutions to the sub-tasks. We apply our method to the tasks of LLM response evaluation and constrained text generation and evaluate its effectiveness with multiple LLMs, including Vicuna, LLaMA-2-chat, and GPT-4. BSM improves the evaluation correctness and consistency for each LLM by enhancing human-LLM agreement by up to 26%, reducing length and pairwise position biases by up to 50%, and allowing LLaMA-2-chat to match or outperform GPT-4 on most domains. On the constraint story generation task, BSM improves the coherence of the stories while also improving constraint satisfaction by 12%.
The Temporal Structure of Language Processing in the Human Brain Corresponds to The Layered Hierarchy of Deep Language Models
Oct 11, 2023Deep Language Models (DLMs) provide a novel computational paradigm for understanding the mechanisms of natural language processing in the human brain. Unlike traditional psycholinguistic models, DLMs use layered sequences of continuous numerical vectors to represent words and context, allowing a plethora of emerging applications such as human-like text generation. In this paper we show evidence that the layered hierarchy of DLMs may be used to model the temporal dynamics of language comprehension in the brain by demonstrating a strong correlation between DLM layer depth and the time at which layers are most predictive of the human brain. Our ability to temporally resolve individual layers benefits from our use of electrocorticography (ECoG) data, which has a much higher temporal resolution than noninvasive methods like fMRI. Using ECoG, we record neural activity from participants listening to a 30-minute narrative while also feeding the same narrative to a high-performing DLM (GPT2-XL). We then extract contextual embeddings from the different layers of the DLM and use linear encoding models to predict neural activity. We first focus on the Inferior Frontal Gyrus (IFG, or Broca's area) and then extend our model to track the increasing temporal receptive window along the linguistic processing hierarchy from auditory to syntactic and semantic areas. Our results reveal a connection between human language processing and DLMs, with the DLM's layer-by-layer accumulation of contextual information mirroring the timing of neural activity in high-order language areas.
Self-Alignment with Instruction Backtranslation
Aug 14, 2023

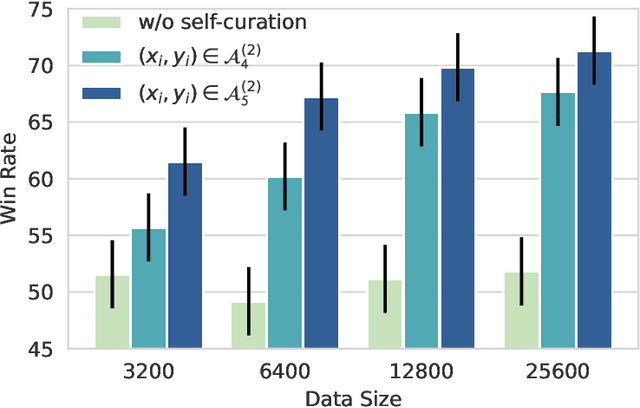
We present a scalable method to build a high quality instruction following language model by automatically labelling human-written text with corresponding instructions. Our approach, named instruction backtranslation, starts with a language model finetuned on a small amount of seed data, and a given web corpus. The seed model is used to construct training examples by generating instruction prompts for web documents (self-augmentation), and then selecting high quality examples from among these candidates (self-curation). This data is then used to finetune a stronger model. Finetuning LLaMa on two iterations of our approach yields a model that outperforms all other LLaMa-based models on the Alpaca leaderboard not relying on distillation data, demonstrating highly effective self-alignment.
ZeroSCROLLS: A Zero-Shot Benchmark for Long Text Understanding
May 23, 2023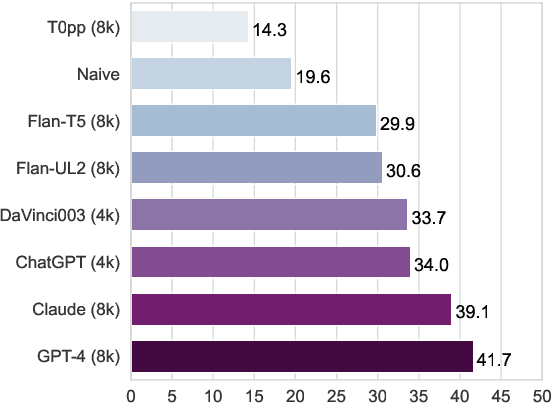
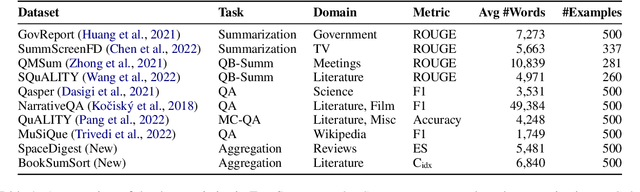
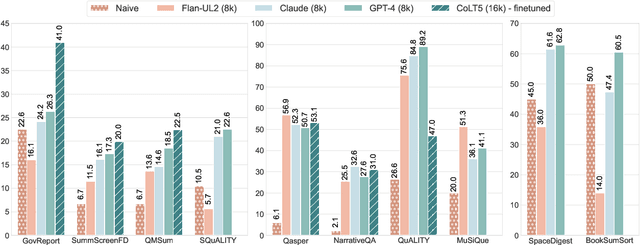
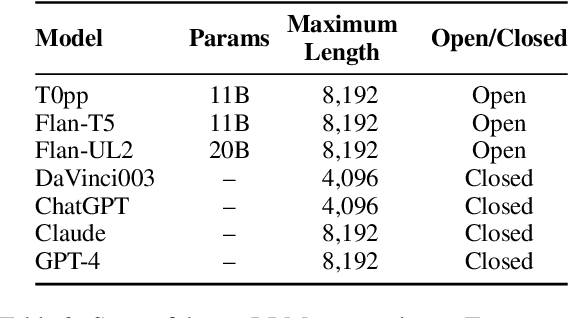
We introduce ZeroSCROLLS, a zero-shot benchmark for natural language understanding over long texts, which contains only test sets, without training or development data. We adapt six tasks from the SCROLLS benchmark, and add four new datasets, including two novel information fusing tasks, such as aggregating the percentage of positive reviews. Using ZeroSCROLLS, we conduct a comprehensive evaluation of both open-source and closed large language models, finding that Claude outperforms ChatGPT, and that GPT-4 achieves the highest average score. However, there is still room for improvement on multiple open challenges in ZeroSCROLLS, such as aggregation tasks, where models struggle to pass the naive baseline. As the state of the art is a moving target, we invite researchers to evaluate their ideas on the live ZeroSCROLLS leaderboard
LIMA: Less Is More for Alignment
May 18, 2023



Large language models are trained in two stages: (1) unsupervised pretraining from raw text, to learn general-purpose representations, and (2) large scale instruction tuning and reinforcement learning, to better align to end tasks and user preferences. We measure the relative importance of these two stages by training LIMA, a 65B parameter LLaMa language model fine-tuned with the standard supervised loss on only 1,000 carefully curated prompts and responses, without any reinforcement learning or human preference modeling. LIMA demonstrates remarkably strong performance, learning to follow specific response formats from only a handful of examples in the training data, including complex queries that range from planning trip itineraries to speculating about alternate history. Moreover, the model tends to generalize well to unseen tasks that did not appear in the training data. In a controlled human study, responses from LIMA are either equivalent or strictly preferred to GPT-4 in 43% of cases; this statistic is as high as 58% when compared to Bard and 65% versus DaVinci003, which was trained with human feedback. Taken together, these results strongly suggest that almost all knowledge in large language models is learned during pretraining, and only limited instruction tuning data is necessary to teach models to produce high quality output.
Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation
May 02, 2023
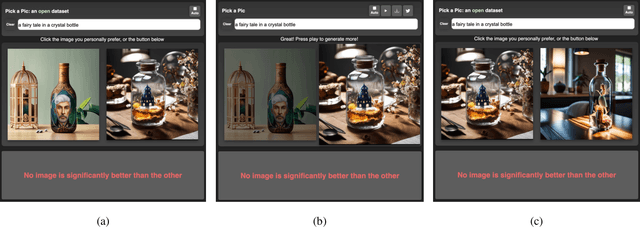


The ability to collect a large dataset of human preferences from text-to-image users is usually limited to companies, making such datasets inaccessible to the public. To address this issue, we create a web app that enables text-to-image users to generate images and specify their preferences. Using this web app we build Pick-a-Pic, a large, open dataset of text-to-image prompts and real users' preferences over generated images. We leverage this dataset to train a CLIP-based scoring function, PickScore, which exhibits superhuman performance on the task of predicting human preferences. Then, we test PickScore's ability to perform model evaluation and observe that it correlates better with human rankings than other automatic evaluation metrics. Therefore, we recommend using PickScore for evaluating future text-to-image generation models, and using Pick-a-Pic prompts as a more relevant dataset than MS-COCO. Finally, we demonstrate how PickScore can enhance existing text-to-image models via ranking.