 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning over mathematical objects: on-policy reward modeling and test time aggregation
Mar 19, 2026The ability to precisely derive mathematical objects is a core requirement for downstream STEM applications, including mathematics, physics, and chemistry, where reasoning must culminate in formally structured expressions. Yet, current LM evaluations of mathematical and scientific reasoning rely heavily on simplified answer formats such as numerical values or multiple choice options due to the convenience of automated assessment. In this paper we provide three contributions for improving reasoning over mathematical objects: (i) we build and release training data and benchmarks for deriving mathematical objects, the Principia suite; (ii) we provide training recipes with strong LLM-judges and verifiers, where we show that on-policy judge training boosts performance; (iii) we show how on-policy training can also be used to scale test-time compute via aggregation. We find that strong LMs such as Qwen3-235B and o3 struggle on Principia, while our training recipes can bring significant improvements over different LLM backbones, while simultaneously improving results on existing numerical and MCQA tasks, demonstrating cross-format generalization of reasoning abilities.
CharacterFlywheel: Scaling Iterative Improvement of Engaging and Steerable LLMs in Production
Mar 02, 2026This report presents CharacterFlywheel, an iterative flywheel process for improving large language models (LLMs) in production social chat applications across Instagram, WhatsApp, and Messenger. Starting from LLaMA 3.1, we refined models across 15 generations using data from both internal and external real-user traffic. Through continuous deployments from July 2024 to April 2025, we conducted controlled 7-day A/B tests showing consistent engagement improvements: 7 of 8 newly deployed models demonstrated positive lift over the baseline, with the strongest performers achieving up to 8.8% improvement in engagement breadth and 19.4% in engagement depth. We also observed substantial gains in steerability, with instruction following increasing from 59.2% to 84.8% and instruction violations decreasing from 26.6% to 5.8%. We detail the CharacterFlywheel process which integrates data curation, reward modeling to estimate and interpolate the landscape of engagement metrics, supervised fine-tuning (SFT), reinforcement learning (RL), and both offline and online evaluation to ensure reliable progress at each optimization step. We also discuss our methods for overfitting prevention and navigating production dynamics at scale. These contributions advance the scientific rigor and understanding of LLMs in social applications serving millions of users.
Self-Improving Pretraining: using post-trained models to pretrain better models
Jan 29, 2026Ensuring safety, factuality and overall quality in the generations of large language models is a critical challenge, especially as these models are increasingly deployed in real-world applications. The prevailing approach to addressing these issues involves collecting expensive, carefully curated datasets and applying multiple stages of fine-tuning and alignment. However, even this complex pipeline cannot guarantee the correction of patterns learned during pretraining. Therefore, addressing these issues during pretraining is crucial, as it shapes a model's core behaviors and prevents unsafe or hallucinated outputs from becoming deeply embedded. To tackle this issue, we introduce a new pretraining method that streams documents and uses reinforcement learning (RL) to improve the next K generated tokens at each step. A strong, post-trained model judges candidate generations -- including model rollouts, the original suffix, and a rewritten suffix -- for quality, safety, and factuality. Early in training, the process relies on the original and rewritten suffixes; as the model improves, RL rewards high-quality rollouts. This approach builds higher quality, safer, and more factual models from the ground up. In experiments, our method gives 36.2% and 18.5% relative improvements over standard pretraining in terms of factuality and safety, and up to 86.3% win rate improvements in overall generation quality.
Scaling Agent Learning via Experience Synthesis
Nov 10, 2025



While reinforcement learning (RL) can empower autonomous agents by enabling self-improvement through interaction, its practical adoption remains challenging due to costly rollouts, limited task diversity, unreliable reward signals, and infrastructure complexity, all of which obstruct the collection of scalable experience data. To address these challenges, we introduce DreamGym, the first unified framework designed to synthesize diverse experiences with scalability in mind to enable effective online RL training for autonomous agents. Rather than relying on expensive real-environment rollouts, DreamGym distills environment dynamics into a reasoning-based experience model that derives consistent state transitions and feedback signals through step-by-step reasoning, enabling scalable agent rollout collection for RL. To improve the stability and quality of transitions, DreamGym leverages an experience replay buffer initialized with offline real-world data and continuously enriched with fresh interactions to actively support agent training. To improve knowledge acquisition, DreamGym adaptively generates new tasks that challenge the current agent policy, enabling more effective online curriculum learning. Experiments across diverse environments and agent backbones demonstrate that DreamGym substantially improves RL training, both in fully synthetic settings and in sim-to-real transfer scenarios. On non-RL-ready tasks like WebArena, DreamGym outperforms all baselines by over 30%. And in RL-ready but costly settings, it matches GRPO and PPO performance using only synthetic interactions. When transferring a policy trained purely on synthetic experiences to real-environment RL, DreamGym yields significant additional performance gains while requiring far fewer real-world interactions, providing a scalable warm-start strategy for general-purpose RL.
RESTRAIN: From Spurious Votes to Signals -- Self-Driven RL with Self-Penalization
Oct 02, 2025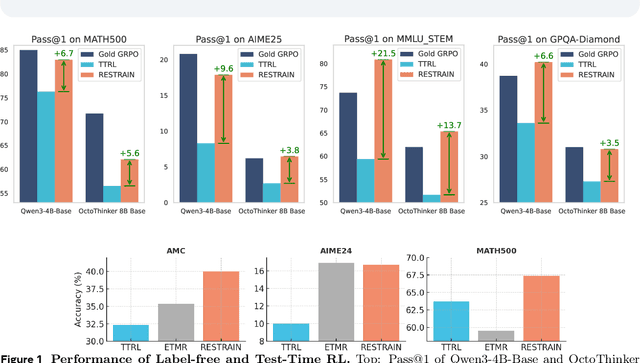
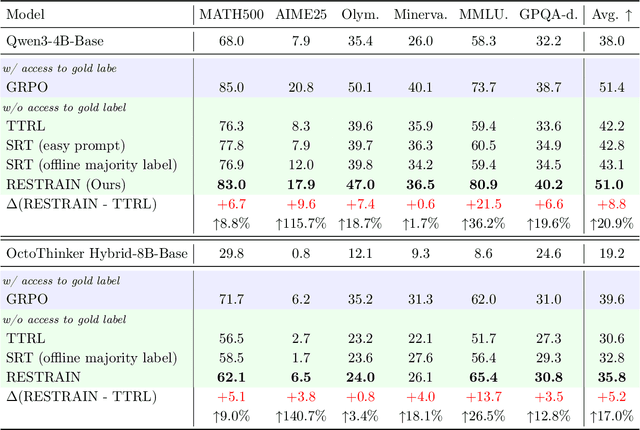
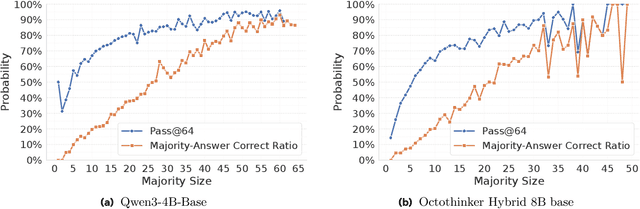
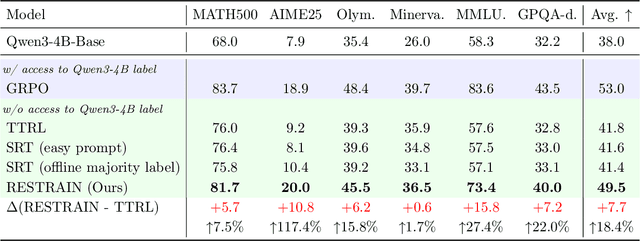
Reinforcement learning with human-annotated data has boosted chain-of-thought reasoning in large reasoning models, but these gains come at high costs in labeled data while faltering on harder tasks. A natural next step is experience-driven learning, where models improve without curated labels by adapting to unlabeled data. We introduce RESTRAIN (REinforcement learning with Self-restraint), a self-penalizing RL framework that converts the absence of gold labels into a useful learning signal. Instead of overcommitting to spurious majority votes, RESTRAIN exploits signals from the model's entire answer distribution: penalizing overconfident rollouts and low-consistency examples while preserving promising reasoning chains. The self-penalization mechanism integrates seamlessly into policy optimization methods such as GRPO, enabling continual self-improvement without supervision. On challenging reasoning benchmarks, RESTRAIN delivers large gains using only unlabeled data. With Qwen3-4B-Base and OctoThinker Hybrid-8B-Base, it improves Pass@1 by up to +140.7 percent on AIME25, +36.2 percent on MMLU_STEM, and +19.6 percent on GPQA-Diamond, nearly matching gold-label training while using no gold labels. These results demonstrate that RESTRAIN establishes a scalable path toward stronger reasoning without gold labels.
Stochastic activations
Sep 26, 2025We introduce stochastic activations. This novel strategy randomly selects between several non-linear functions in the feed-forward layer of a large language model. In particular, we choose between SILU or RELU depending on a Bernoulli draw. This strategy circumvents the optimization problem associated with RELU, namely, the constant shape for negative inputs that prevents the gradient flow. We leverage this strategy in two ways: (1) We use stochastic activations during pre-training and fine-tune the model with RELU, which is used at inference time to provide sparse latent vectors. This reduces the inference FLOPs and translates into a significant speedup in the CPU. Interestingly, this leads to much better results than training from scratch with the RELU activation function. (2) We evaluate stochastic activations for generation. This strategy performs reasonably well: it is only slightly inferior to the best deterministic non-linearity, namely SILU combined with temperature scaling. This offers an alternative to existing strategies by providing a controlled way to increase the diversity of the generated text.
StepWiser: Stepwise Generative Judges for Wiser Reasoning
Aug 27, 2025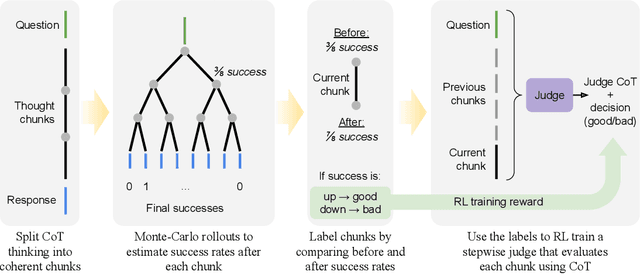


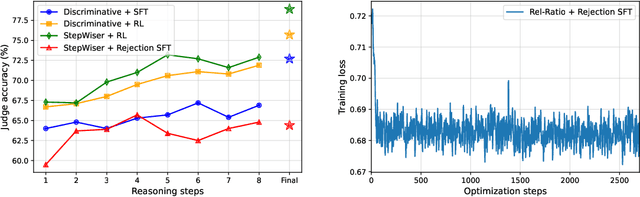
As models increasingly leverage multi-step reasoning strategies to solve complex problems, supervising the logical validity of these intermediate steps has become a critical research challenge. Process reward models address this by providing step-by-step feedback, but current approaches have two major drawbacks: they typically function as classifiers without providing explanations, and their reliance on supervised fine-tuning with static datasets limits generalization. Inspired by recent advances, we reframe stepwise reward modeling from a classification task to a reasoning task itself. We thus propose a generative judge that reasons about the policy model's reasoning steps (i.e., meta-reasons), outputting thinking tokens before delivering a final verdict. Our model, StepWiser, is trained by reinforcement learning using relative outcomes of rollouts. We show it provides (i) better judgment accuracy on intermediate steps than existing methods; (ii) can be used to improve the policy model at training time; and (iii) improves inference-time search.
OptimalThinkingBench: Evaluating Over and Underthinking in LLMs
Aug 18, 2025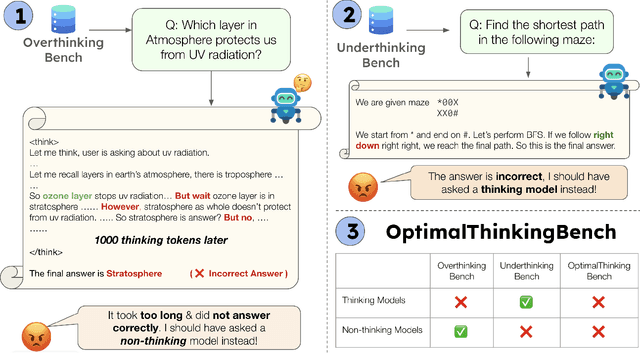
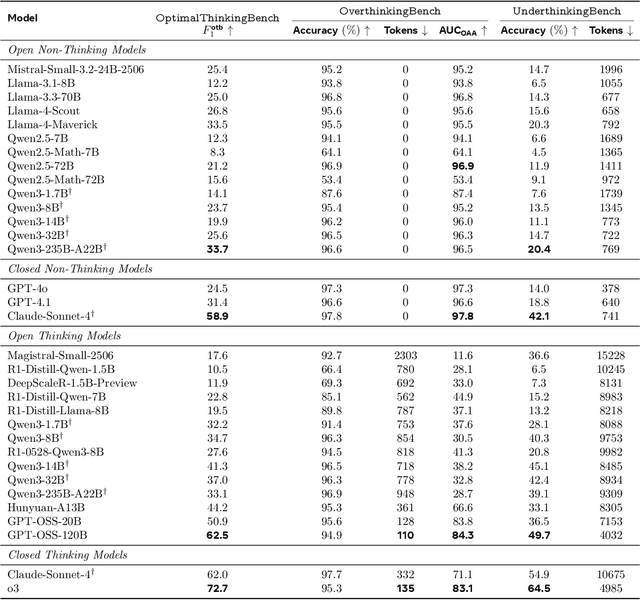

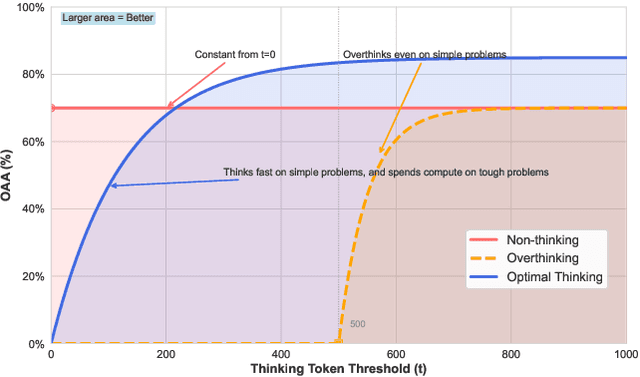
Thinking LLMs solve complex tasks at the expense of increased compute and overthinking on simpler problems, while non-thinking LLMs are faster and cheaper but underthink on harder reasoning problems. This has led to the development of separate thinking and non-thinking LLM variants, leaving the onus of selecting the optimal model for each query on the end user. In this work, we introduce OptimalThinkingBench, a unified benchmark that jointly evaluates overthinking and underthinking in LLMs and also encourages the development of optimally-thinking models that balance performance and efficiency. Our benchmark comprises two sub-benchmarks: OverthinkingBench, featuring simple queries in 72 domains, and UnderthinkingBench, containing 11 challenging reasoning tasks. Using novel thinking-adjusted accuracy metrics, we perform extensive evaluation of 33 different thinking and non-thinking models and show that no model is able to optimally think on our benchmark. Thinking models often overthink for hundreds of tokens on the simplest user queries without improving performance. In contrast, large non-thinking models underthink, often falling short of much smaller thinking models. We further explore several methods to encourage optimal thinking, but find that these approaches often improve on one sub-benchmark at the expense of the other, highlighting the need for better unified and optimal models in the future.
Learning to Reason for Factuality
Aug 07, 2025Reasoning Large Language Models (R-LLMs) have significantly advanced complex reasoning tasks but often struggle with factuality, generating substantially more hallucinations than their non-reasoning counterparts on long-form factuality benchmarks. However, extending online Reinforcement Learning (RL), a key component in recent R-LLM advancements, to the long-form factuality setting poses several unique challenges due to the lack of reliable verification methods. Previous work has utilized automatic factuality evaluation frameworks such as FActScore to curate preference data in the offline RL setting, yet we find that directly leveraging such methods as the reward in online RL leads to reward hacking in multiple ways, such as producing less detailed or relevant responses. We propose a novel reward function that simultaneously considers the factual precision, response detail level, and answer relevance, and applies online RL to learn high quality factual reasoning. Evaluated on six long-form factuality benchmarks, our factual reasoning model achieves an average reduction of 23.1 percentage points in hallucination rate, a 23% increase in answer detail level, and no degradation in the overall response helpfulness.
CoT-Self-Instruct: Building high-quality synthetic prompts for reasoning and non-reasoning tasks
Jul 31, 2025We propose CoT-Self-Instruct, a synthetic data generation method that instructs LLMs to first reason and plan via Chain-of-Thought (CoT) based on the given seed tasks, and then to generate a new synthetic prompt of similar quality and complexity for use in LLM training, followed by filtering for high-quality data with automatic metrics. In verifiable reasoning, our synthetic data significantly outperforms existing training datasets, such as s1k and OpenMathReasoning, across MATH500, AMC23, AIME24 and GPQA-Diamond. For non-verifiable instruction-following tasks, our method surpasses the performance of human or standard self-instruct prompts on both AlpacaEval 2.0 and Arena-Hard.