 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtrapolative Weight Averaging Reveals Correctness-Efficiency Frontiers in Code RL
May 27, 2026Linear interpolation between fine-tuned checkpoints has been shown to trace the Pareto front between competing objectives, but whether extrapolative weight averaging can extend such frontiers to new checkpoints useful at inference time, without additional RL training, remains unclear. We study this question in RL for competitive programming, where hidden unit tests under time and memory limits enforce both functional correctness and computational efficiency. Starting from a shared initialization, we train checkpoints under nested unit-test coverage: low-coverage rewards require passing smaller-input tests, while high-coverage rewards require passing progressively larger tests up to the full suite. This sweep reveals the emergence of a correctness-efficiency frontier: on hard problems, higher-coverage reward reduces optimization failures but increases correctness failures, leaving solve rate nearly unchanged. Interpolation between low- and high-coverage checkpoints recovers this frontier, while extrapolation extends it beyond the trained endpoints. Both the frontier and its extrapolative continuation appear across three inference settings, pure reasoning, tool use, and agentic coding, and across two model scales, 32B and 7B. At the problem level, moving along the frontier changes which problems are solved, making extrapolated checkpoints complementary policies in inference-time scaling. Ensembles with extrapolative weight averaging broaden coverage and improve pass@250 on LCB/hard by 3.3% over the best single checkpoint at matched sample budget. These results show that nested unit-test coverage in code RL induces a frontier that extrapolative weight averaging can navigate, extend, and exploit.
ProgramBench: Can Language Models Rebuild Programs From Scratch?
May 05, 2026Turning ideas into full software projects from scratch has become a popular use case for language models. Agents are being deployed to seed, maintain, and grow codebases over extended periods with minimal human oversight. Such settings require models to make high-level software architecture decisions. However, existing benchmarks measure focused, limited tasks such as fixing a single bug or developing a single, specified feature. We therefore introduce ProgramBench to measure the ability of software engineering agents to develop software holisitically. In ProgramBench, given only a program and its documentation, agents must architect and implement a codebase that matches the reference executable's behavior. End-to-end behavioral tests are generated via agent-driven fuzzing, enabling evaluation without prescribing implementation structure. Our 200 tasks range from compact CLI tools to widely used software such as FFmpeg, SQLite, and the PHP interpreter. We evaluate 9 LMs and find that none fully resolve any task, with the best model passing 95\% of tests on only 3\% of tasks. Models favor monolithic, single-file implementations that diverge sharply from human-written code.
Automatic Textbook Formalization
Apr 03, 2026We present a case study where an automatic AI system formalizes a textbook with more than 500 pages of graduate-level algebraic combinatorics to Lean. The resulting formalization represents a new milestone in textbook formalization scale and proficiency, moving from early results in undergraduate topology and restructuring of existing library content to a full standalone formalization of a graduate textbook. The formalization comprises 130K lines of code and 5900 Lean declarations and was conducted within one week by a total of 30K Claude 4.5 Opus agents collaborating in parallel on a shared code base via version control, simultaneously setting a record in multi-agent software engineering with usable results. The inference cost matches or undercuts what we estimate as the salaries required for a team of human experts, and we expect there is still the potential for large efficiencies to be made without the need for better models. We make our code, the resulting Lean code base and a side-by-side blueprint website available open-source.
WybeCoder: Verified Imperative Code Generation
Mar 31, 2026Recent progress in large language models (LLMs) has advanced automatic code generation and formal theorem proving, yet software verification has not seen the same improvement. To address this gap, we propose WybeCoder, an agentic code verification framework that enables prove-as-you-generate development where code, invariants, and proofs co-evolve. It builds on a recent framework that combines automatic verification condition generation and SMT solvers with interactive proofs in Lean. To enable systematic evaluation, we translate two benchmarks for functional verification in Lean, Verina and Clever, to equivalent imperative code specifications. On complex algorithms such as Heapsort, we observe consistent performance improvements by scaling our approach, synthesizing dozens of valid invariants and dispatching of dozens of subgoals, resulting in hundreds of lines of verified code, overcoming plateaus reported in previous works. Our best system solves 74% of Verina tasks and 62% of Clever tasks at moderate compute budgets, significantly surpassing previous evaluations and paving a path to automated construction of large-scale datasets of verified imperative code.
A Deep Dive into Scaling RL for Code Generation with Synthetic Data and Curricula
Mar 25, 2026Reinforcement learning (RL) has emerged as a powerful paradigm for improving large language models beyond supervised fine-tuning, yet sustaining performance gains at scale remains an open challenge, as data diversity and structure, rather than volume alone, become the limiting factor. We address this by introducing a scalable multi-turn synthetic data generation pipeline in which a teacher model iteratively refines problems based on in-context student performance summaries, producing structured difficulty progressions without any teacher fine-tuning. Compared to single-turn generation, this multi-turn approach substantially improves the yield of valid synthetic problems and naturally produces stepping stones, i.e. easier and harder variants of the same core task, that support curriculum-based training. We systematically study how task difficulty, curriculum scheduling, and environment diversity interact during RL training across the Llama3.1-8B Instruct and Qwen3-8B Base model families, with additional scaling experiments on Qwen2.5-32B. Our results show that synthetic augmentation consistently improves in-domain code and in most cases out-of-domain math performance, and we provide empirical insights into how curriculum design and data diversity jointly shape RL training dynamics.
Towards a Neural Debugger for Python
Mar 10, 2026Training large language models (LLMs) on Python execution traces grounds them in code execution and enables the line-by-line execution prediction of whole Python programs, effectively turning them into neural interpreters (FAIR CodeGen Team et al., 2025). However, developers rarely execute programs step by step; instead, they use debuggers to stop execution at certain breakpoints and step through relevant portions only while inspecting or modifying program variables. Existing neural interpreter approaches lack such interactive control. To address this limitation, we introduce neural debuggers: language models that emulate traditional debuggers, supporting operations such as stepping into, over, or out of functions, as well as setting breakpoints at specific source lines. We show that neural debuggers -- obtained via fine-tuning large LLMs or pre-training smaller models from scratch -- can reliably model both forward execution (predicting future states and outputs) and inverse execution (inferring prior states or inputs) conditioned on debugger actions. Evaluated on CruxEval, our models achieve strong performance on both output and input prediction tasks, demonstrating robust conditional execution modeling. Our work takes first steps towards future agentic coding systems in which neural debuggers serve as a world model for simulated debugging environments, providing execution feedback or enabling agents to interact with real debugging tools. This capability lays the foundation for more powerful code generation, program understanding, and automated debugging.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Toward Training Superintelligent Software Agents through Self-Play SWE-RL
Dec 21, 2025While current software agents powered by large language models (LLMs) and agentic reinforcement learning (RL) can boost programmer productivity, their training data (e.g., GitHub issues and pull requests) and environments (e.g., pass-to-pass and fail-to-pass tests) heavily depend on human knowledge or curation, posing a fundamental barrier to superintelligence. In this paper, we present Self-play SWE-RL (SSR), a first step toward training paradigms for superintelligent software agents. Our approach takes minimal data assumptions, only requiring access to sandboxed repositories with source code and installed dependencies, with no need for human-labeled issues or tests. Grounded in these real-world codebases, a single LLM agent is trained via reinforcement learning in a self-play setting to iteratively inject and repair software bugs of increasing complexity, with each bug formally specified by a test patch rather than a natural language issue description. On the SWE-bench Verified and SWE-Bench Pro benchmarks, SSR achieves notable self-improvement (+10.4 and +7.8 points, respectively) and consistently outperforms the human-data baseline over the entire training trajectory, despite being evaluated on natural language issues absent from self-play. Our results, albeit early, suggest a path where agents autonomously gather extensive learning experiences from real-world software repositories, ultimately enabling superintelligent systems that exceed human capabilities in understanding how systems are constructed, solving novel challenges, and autonomously creating new software from scratch.
Stochastic activations
Sep 26, 2025We introduce stochastic activations. This novel strategy randomly selects between several non-linear functions in the feed-forward layer of a large language model. In particular, we choose between SILU or RELU depending on a Bernoulli draw. This strategy circumvents the optimization problem associated with RELU, namely, the constant shape for negative inputs that prevents the gradient flow. We leverage this strategy in two ways: (1) We use stochastic activations during pre-training and fine-tune the model with RELU, which is used at inference time to provide sparse latent vectors. This reduces the inference FLOPs and translates into a significant speedup in the CPU. Interestingly, this leads to much better results than training from scratch with the RELU activation function. (2) We evaluate stochastic activations for generation. This strategy performs reasonably well: it is only slightly inferior to the best deterministic non-linearity, namely SILU combined with temperature scaling. This offers an alternative to existing strategies by providing a controlled way to increase the diversity of the generated text.
Set Block Decoding is a Language Model Inference Accelerator
Sep 04, 2025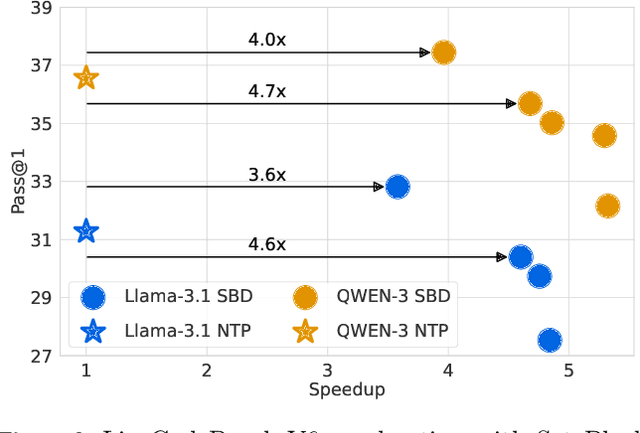
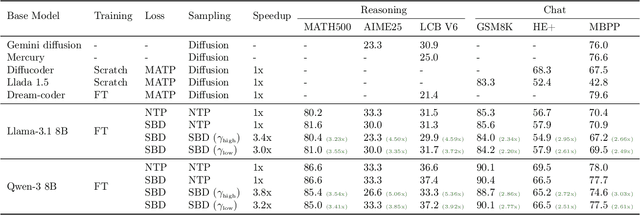
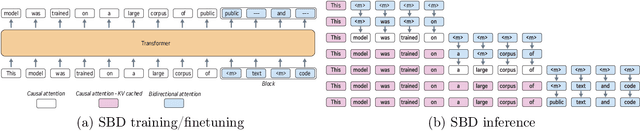

Autoregressive next token prediction language models offer powerful capabilities but face significant challenges in practical deployment due to the high computational and memory costs of inference, particularly during the decoding stage. We introduce Set Block Decoding (SBD), a simple and flexible paradigm that accelerates generation by integrating standard next token prediction (NTP) and masked token prediction (MATP) within a single architecture. SBD allows the model to sample multiple, not necessarily consecutive, future tokens in parallel, a key distinction from previous acceleration methods. This flexibility allows the use of advanced solvers from the discrete diffusion literature, offering significant speedups without sacrificing accuracy. SBD requires no architectural changes or extra training hyperparameters, maintains compatibility with exact KV-caching, and can be implemented by fine-tuning existing next token prediction models. By fine-tuning Llama-3.1 8B and Qwen-3 8B, we demonstrate that SBD enables a 3-5x reduction in the number of forward passes required for generation while achieving same performance as equivalent NTP training.