 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Overthink it. Preferring Shorter Thinking Chains for Improved LLM Reasoning
May 23, 2025Reasoning large language models (LLMs) heavily rely on scaling test-time compute to perform complex reasoning tasks by generating extensive "thinking" chains. While demonstrating impressive results, this approach incurs significant computational costs and inference time. In this work, we challenge the assumption that long thinking chains results in better reasoning capabilities. We first demonstrate that shorter reasoning chains within individual questions are significantly more likely to yield correct answers - up to 34.5% more accurate than the longest chain sampled for the same question. Based on these results, we suggest short-m@k, a novel reasoning LLM inference method. Our method executes k independent generations in parallel and halts computation once the first m thinking processes are done. The final answer is chosen using majority voting among these m chains. Basic short-1@k demonstrates similar or even superior performance over standard majority voting in low-compute settings - using up to 40% fewer thinking tokens. short-3@k, while slightly less efficient than short-1@k, consistently surpasses majority voting across all compute budgets, while still being substantially faster (up to 33% wall time reduction). Inspired by our results, we finetune an LLM using short, long, and randomly selected reasoning chains. We then observe that training on the shorter ones leads to better performance. Our findings suggest rethinking current methods of test-time compute in reasoning LLMs, emphasizing that longer "thinking" does not necessarily translate to improved performance and can, counter-intuitively, lead to degraded results.
Scaling Analysis of Interleaved Speech-Text Language Models
Apr 03, 2025



Existing Speech Language Model (SLM) scaling analysis paints a bleak picture. They predict that SLMs require much more compute and data compared to text, leading some to question the feasibility of training high-quality SLMs. However, modern SLMs are often initialised from pre-trained TextLMs using speech-text interleaving to allow knowledge transfer. This raises the question - Do interleaved SLMs scale more efficiently than textless-SLMs? In this paper we answer a resounding, yes! We conduct scaling analysis of interleaved SLMs by training several dozen and analysing the scaling trends. We see that under this setup SLMs scale more efficiently with compute. Additionally, our results indicate that the scaling-dynamics are significantly different than textless-SLMs, suggesting one should allocate notably more of the compute budget for increasing model size over training tokens. We also study the role of synthetic data and TextLM model families in unlocking this potential. Results suggest, that our scaled up model achieves comparable performance with leading models on speech semantic metrics while using less compute and data than other approaches. We open source models, samples, and data - https://pages.cs.huji.ac.il/adiyoss-lab/sims.
More Documents, Same Length: Isolating the Challenge of Multiple Documents in RAG
Mar 06, 2025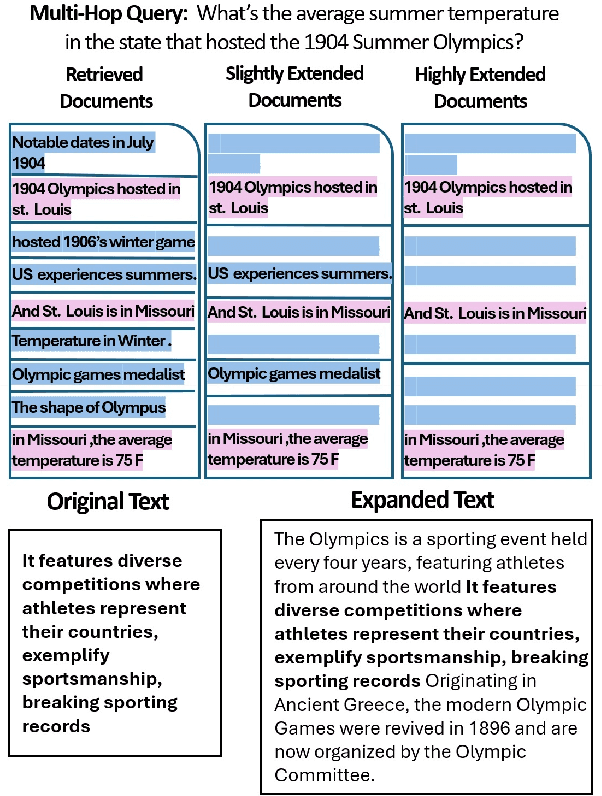


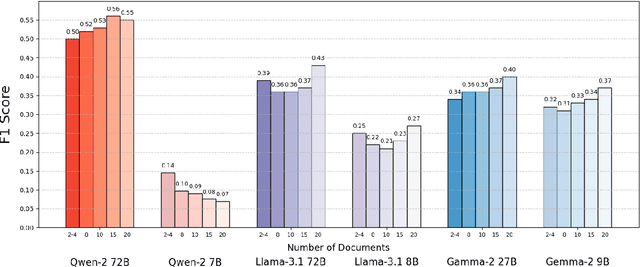
Retrieval-augmented generation (RAG) provides LLMs with relevant documents. Although previous studies noted that retrieving many documents can degrade performance, they did not isolate how the quantity of documents affects performance while controlling for context length. We evaluate various language models on custom datasets derived from a multi-hop QA task. We keep the context length and position of relevant information constant while varying the number of documents, and find that increasing the document count in RAG settings poses significant challenges for LLMs. Additionally, our results indicate that processing multiple documents is a separate challenge from handling long contexts. We also make the datasets and code available: https://github.com/shaharl6000/MoreDocsSameLen .
On Pruning State-Space LLMs
Feb 26, 2025



Recent work proposed state-space models (SSMs) as an efficient alternative to transformer-based LLMs. Can these models be pruned to further reduce their computation costs? We adapt several pruning methods to the SSM structure, and apply them to four SSM-based LLMs across multiple tasks. We find that such models are quite robust to some pruning methods (e.g. WANDA), while using other methods lead to fast performance degradation.
The Larger the Better? Improved LLM Code-Generation via Budget Reallocation
Mar 31, 2024



It is a common belief that large language models (LLMs) are better than smaller-sized ones. However, larger models also require significantly more time and compute during inference. This begs the question: what happens when both models operate under the same budget? (e.g., compute, run-time). To address this question, we analyze code generation LLMs of various sizes and make comparisons such as running a 70B model once vs. generating five outputs from a 13B model and selecting one. Our findings reveal that, in a standard unit-test setup, the repeated use of smaller models can yield consistent improvements, with gains of up to 15% across five tasks. On the other hand, in scenarios where unit-tests are unavailable, a ranking-based selection of candidates from the smaller model falls short of the performance of a single output from larger ones. Our results highlight the potential of using smaller models instead of larger ones, and the importance of studying approaches for ranking LLM outputs.
Transformers are Multi-State RNNs
Jan 11, 2024



Transformers are considered conceptually different compared to the previous generation of state-of-the-art NLP models - recurrent neural networks (RNNs). In this work, we demonstrate that decoder-only transformers can in fact be conceptualized as infinite multi-state RNNs - an RNN variant with unlimited hidden state size. We further show that pretrained transformers can be converted into $\textit{finite}$ multi-state RNNs by fixing the size of their hidden state. We observe that several existing transformers cache compression techniques can be framed as such conversion policies, and introduce a novel policy, TOVA, which is simpler compared to these policies. Our experiments with several long range tasks indicate that TOVA outperforms all other baseline policies, while being nearly on par with the full (infinite) model, and using in some cases only $\frac{1}{8}$ of the original cache size. Our results indicate that transformer decoder LLMs often behave in practice as RNNs. They also lay out the option of mitigating one of their most painful computational bottlenecks - the size of their cache memory. We publicly release our code at https://github.com/schwartz-lab-NLP/TOVA.
EXPRESSO: A Benchmark and Analysis of Discrete Expressive Speech Resynthesis
Aug 10, 2023



Recent work has shown that it is possible to resynthesize high-quality speech based, not on text, but on low bitrate discrete units that have been learned in a self-supervised fashion and can therefore capture expressive aspects of speech that are hard to transcribe (prosody, voice styles, non-verbal vocalization). The adoption of these methods is still limited by the fact that most speech synthesis datasets are read, severely limiting spontaneity and expressivity. Here, we introduce Expresso, a high-quality expressive speech dataset for textless speech synthesis that includes both read speech and improvised dialogues rendered in 26 spontaneous expressive styles. We illustrate the challenges and potentials of this dataset with an expressive resynthesis benchmark where the task is to encode the input in low-bitrate units and resynthesize it in a target voice while preserving content and style. We evaluate resynthesis quality with automatic metrics for different self-supervised discrete encoders, and explore tradeoffs between quality, bitrate and invariance to speaker and style. All the dataset, evaluation metrics and baseline models are open source
Finding the SWEET Spot: Analysis and Improvement of Adaptive Inference in Low Resource Settings
Jun 04, 2023Adaptive inference is a simple method for reducing inference costs. The method works by maintaining multiple classifiers of different capacities, and allocating resources to each test instance according to its difficulty. In this work, we compare the two main approaches for adaptive inference, Early-Exit and Multi-Model, when training data is limited. First, we observe that for models with the same architecture and size, individual Multi-Model classifiers outperform their Early-Exit counterparts by an average of 2.3%. We show that this gap is caused by Early-Exit classifiers sharing model parameters during training, resulting in conflicting gradient updates of model weights. We find that despite this gap, Early-Exit still provides a better speed-accuracy trade-off due to the overhead of the Multi-Model approach. To address these issues, we propose SWEET (Separating Weights in Early Exit Transformers), an Early-Exit fine-tuning method that assigns each classifier its own set of unique model weights, not updated by other classifiers. We compare SWEET's speed-accuracy curve to standard Early-Exit and Multi-Model baselines and find that it outperforms both methods at fast speeds while maintaining comparable scores to Early-Exit at slow speeds. Moreover, SWEET individual classifiers outperform Early-Exit ones by 1.1% on average. SWEET enjoys the benefits of both methods, paving the way for further reduction of inference costs in NLP.
Textually Pretrained Speech Language Models
May 22, 2023



Speech language models (SpeechLMs) process and generate acoustic data only, without textual supervision. In this work, we propose TWIST, a method for training SpeechLMs using a warm-start from a pretrained textual language models. We show using both automatic and human evaluations that TWIST outperforms a cold-start SpeechLM across the board. We empirically analyze the effect of different model design choices such as the speech tokenizer, the pretrained textual model, and the dataset size. We find that model and dataset scale both play an important role in constructing better-performing SpeechLMs. Based on our observations, we present the largest (to the best of our knowledge) SpeechLM both in terms of number of parameters and training data. We additionally introduce two spoken versions of the StoryCloze textual benchmark to further improve model evaluation and advance future research in the field. Speech samples can be found on our website: https://pages.cs.huji.ac.il/adiyoss-lab/twist/ .
How Much Does Attention Actually Attend? Questioning the Importance of Attention in Pretrained Transformers
Nov 07, 2022



The attention mechanism is considered the backbone of the widely-used Transformer architecture. It contextualizes the input by computing input-specific attention matrices. We find that this mechanism, while powerful and elegant, is not as important as typically thought for pretrained language models. We introduce PAPA, a new probing method that replaces the input-dependent attention matrices with constant ones -- the average attention weights over multiple inputs. We use PAPA to analyze several established pretrained Transformers on six downstream tasks. We find that without any input-dependent attention, all models achieve competitive performance -- an average relative drop of only 8% from the probing baseline. Further, little or no performance drop is observed when replacing half of the input-dependent attention matrices with constant (input-independent) ones. Interestingly, we show that better-performing models lose more from applying our method than weaker models, suggesting that the utilization of the input-dependent attention mechanism might be a factor in their success. Our results motivate research on simpler alternatives to input-dependent attention, as well as on methods for better utilization of this mechanism in the Transformer architecture.