 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Weighted Hankel Approach and Cramér-Rao Bound Analysis for Quantitative Acoustic Microscopy Imaging
Dec 10, 2024Quantitative acoustic microscopy (QAM) is a cutting-edge imaging modality that leverages very high-frequency ultrasound to characterize the acoustic and mechanical properties of biological tissues at microscopic resolutions. Radio-frequency echo signals are digitized and processed to yield two-dimensional maps. This paper introduces a weighted Hankel-based spectral method with a reweighting strategy to enhance robustness with regard to noise and reduce unreliable acoustic parameter estimates. Additionally, we derive, for the first time in QAM, Cram\'er-Rao bounds to establish theoretical performance benchmarks for acoustic parameter estimation. Simulations and experimental results demonstrate that the proposed method consistently outperform standard autoregressive approach, particularly under challenging conditions. These advancements promise to improve the accuracy and reliability of tissue characterization, enhancing the potential of QAM for biomedical applications.
Distributed Speculative Inference of Large Language Models
May 23, 2024Accelerating the inference of large language models (LLMs) is an important challenge in artificial intelligence. This paper introduces distributed speculative inference (DSI), a novel distributed inference algorithm that is provably faster than speculative inference (SI) [leviathan2023fast, chen2023accelerating, miao2023specinfer] and traditional autoregressive inference (non-SI). Like other SI algorithms, DSI works on frozen LLMs, requiring no training or architectural modifications, and it preserves the target distribution. Prior studies on SI have demonstrated empirical speedups (compared to non-SI) but require a fast and accurate drafter LLM. In practice, off-the-shelf LLMs often do not have matching drafters that are sufficiently fast and accurate. We show a gap: SI gets slower than non-SI when using slower or less accurate drafters. We close this gap by proving that DSI is faster than both SI and non-SI given any drafters. By orchestrating multiple instances of the target and drafters, DSI is not only faster than SI but also supports LLMs that cannot be accelerated with SI. Our simulations show speedups of off-the-shelf LLMs in realistic settings: DSI is 1.29-1.92x faster than SI.
Accelerating Speculative Decoding using Dynamic Speculation Length
May 07, 2024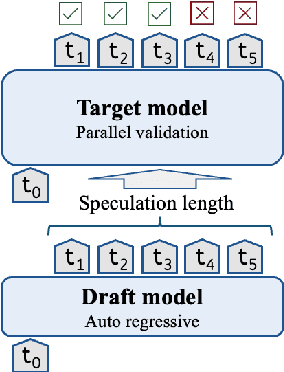


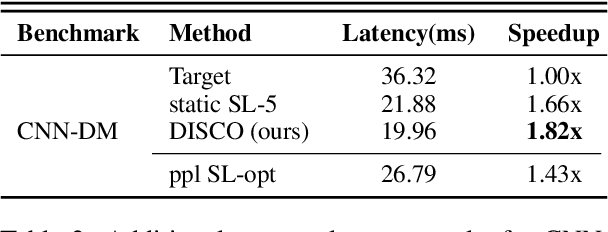
Speculative decoding is a promising method for reducing the inference latency of large language models. The effectiveness of the method depends on the speculation length (SL) - the number of tokens generated by the draft model at each iteration. The vast majority of speculative decoding approaches use the same SL for all iterations. In this work, we show that this practice is suboptimal. We introduce DISCO, a DynamIc SpeCulation length Optimization method that uses a classifier to dynamically adjust the SL at each iteration, while provably preserving the decoding quality. Experiments with four benchmarks demonstrate average speedup gains of 10.3% relative to our best baselines.
Finding the SWEET Spot: Analysis and Improvement of Adaptive Inference in Low Resource Settings
Jun 04, 2023Adaptive inference is a simple method for reducing inference costs. The method works by maintaining multiple classifiers of different capacities, and allocating resources to each test instance according to its difficulty. In this work, we compare the two main approaches for adaptive inference, Early-Exit and Multi-Model, when training data is limited. First, we observe that for models with the same architecture and size, individual Multi-Model classifiers outperform their Early-Exit counterparts by an average of 2.3%. We show that this gap is caused by Early-Exit classifiers sharing model parameters during training, resulting in conflicting gradient updates of model weights. We find that despite this gap, Early-Exit still provides a better speed-accuracy trade-off due to the overhead of the Multi-Model approach. To address these issues, we propose SWEET (Separating Weights in Early Exit Transformers), an Early-Exit fine-tuning method that assigns each classifier its own set of unique model weights, not updated by other classifiers. We compare SWEET's speed-accuracy curve to standard Early-Exit and Multi-Model baselines and find that it outperforms both methods at fast speeds while maintaining comparable scores to Early-Exit at slow speeds. Moreover, SWEET individual classifiers outperform Early-Exit ones by 1.1% on average. SWEET enjoys the benefits of both methods, paving the way for further reduction of inference costs in NLP.
TangoBERT: Reducing Inference Cost by using Cascaded Architecture
Apr 13, 2022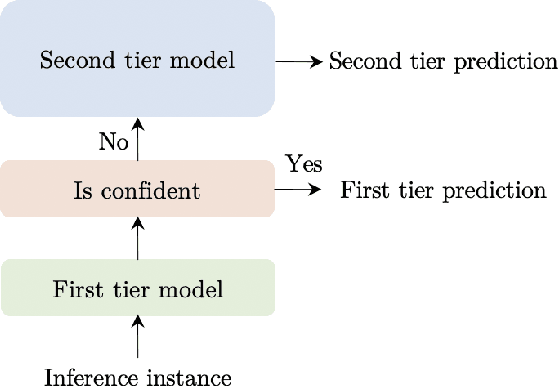

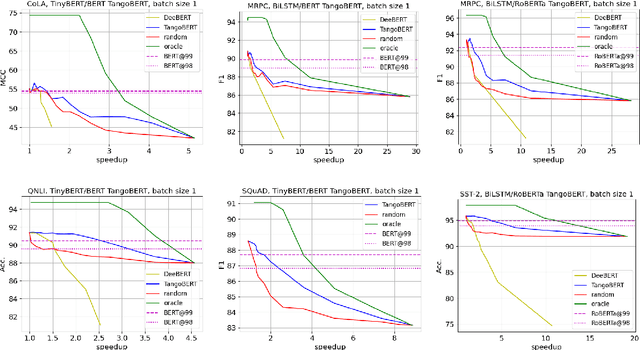
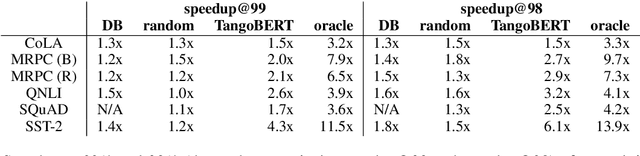
The remarkable success of large transformer-based models such as BERT, RoBERTa and XLNet in many NLP tasks comes with a large increase in monetary and environmental cost due to their high computational load and energy consumption. In order to reduce this computational load in inference time, we present TangoBERT, a cascaded model architecture in which instances are first processed by an efficient but less accurate first tier model, and only part of those instances are additionally processed by a less efficient but more accurate second tier model. The decision of whether to apply the second tier model is based on a confidence score produced by the first tier model. Our simple method has several appealing practical advantages compared to standard cascading approaches based on multi-layered transformer models. First, it enables higher speedup gains (average lower latency). Second, it takes advantage of batch size optimization for cascading, which increases the relative inference cost reductions. We report TangoBERT inference CPU speedup on four text classification GLUE tasks and on one reading comprehension task. Experimental results show that TangoBERT outperforms efficient early exit baseline models; on the the SST-2 task, it achieves an accuracy of 93.9% with a CPU speedup of 8.2x.
Syntactic Perturbations Reveal Representational Correlates of Hierarchical Phrase Structure in Pretrained Language Models
Apr 15, 2021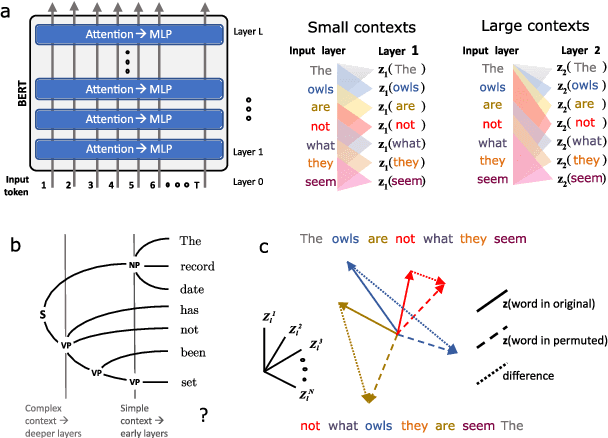
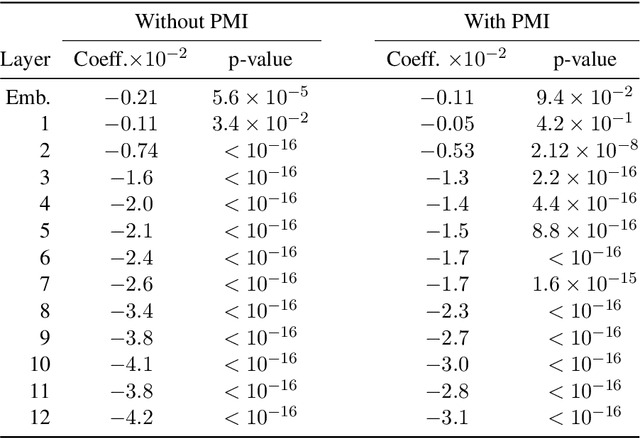

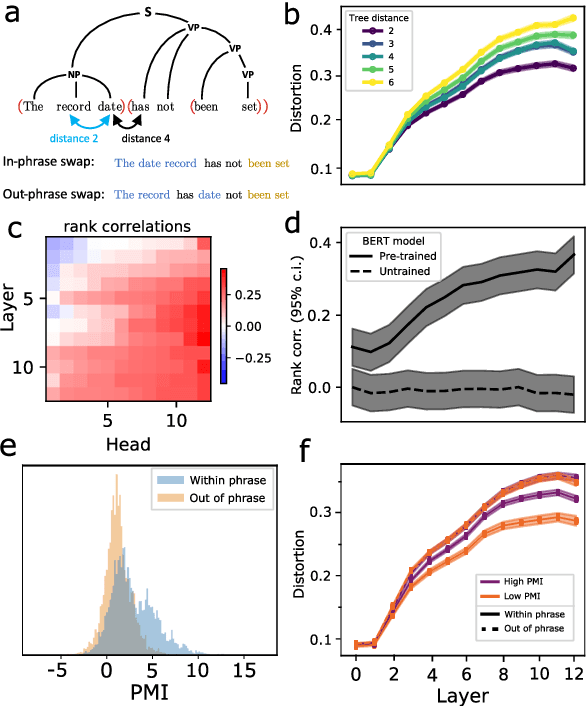
While vector-based language representations from pretrained language models have set a new standard for many NLP tasks, there is not yet a complete accounting of their inner workings. In particular, it is not entirely clear what aspects of sentence-level syntax are captured by these representations, nor how (if at all) they are built along the stacked layers of the network. In this paper, we aim to address such questions with a general class of interventional, input perturbation-based analyses of representations from pretrained language models. Importing from computational and cognitive neuroscience the notion of representational invariance, we perform a series of probes designed to test the sensitivity of these representations to several kinds of structure in sentences. Each probe involves swapping words in a sentence and comparing the representations from perturbed sentences against the original. We experiment with three different perturbations: (1) random permutations of n-grams of varying width, to test the scale at which a representation is sensitive to word position; (2) swapping of two spans which do or do not form a syntactic phrase, to test sensitivity to global phrase structure; and (3) swapping of two adjacent words which do or do not break apart a syntactic phrase, to test sensitivity to local phrase structure. Results from these probes collectively suggest that Transformers build sensitivity to larger parts of the sentence along their layers, and that hierarchical phrase structure plays a role in this process. More broadly, our results also indicate that structured input perturbations widens the scope of analyses that can be performed on often-opaque deep learning systems, and can serve as a complement to existing tools (such as supervised linear probes) for interpreting complex black-box models.
Emergence of Separable Manifolds in Deep Language Representations
Jun 06, 2020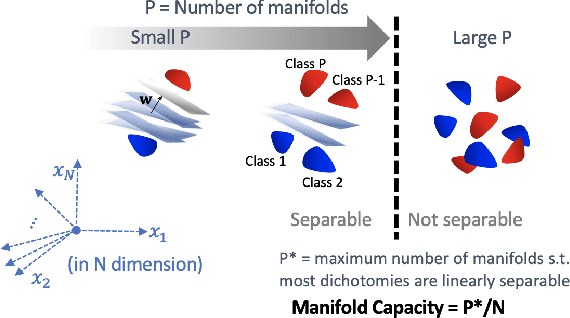
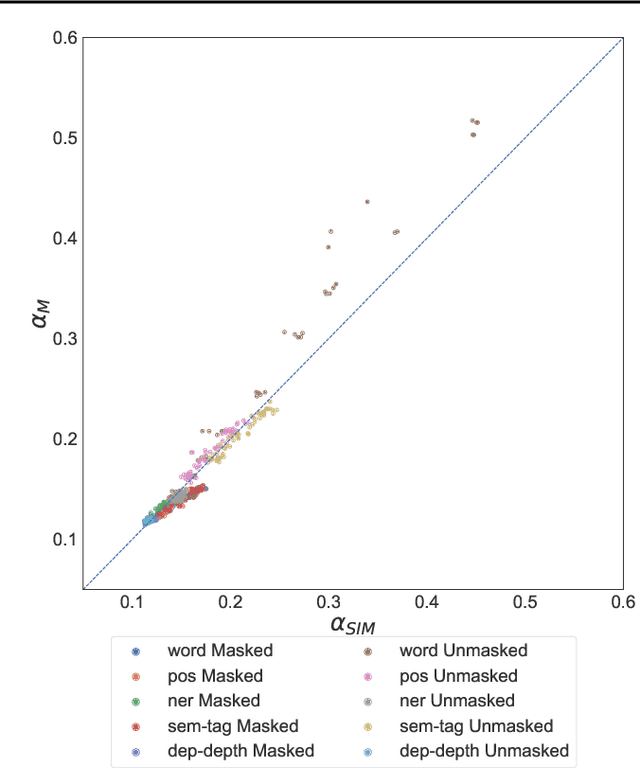
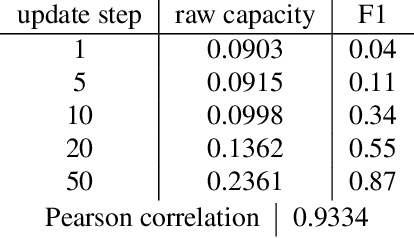
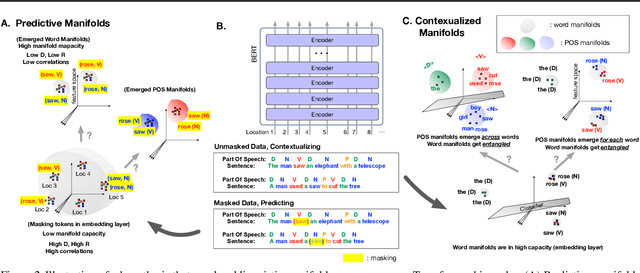
Artificial neural networks (ANNs) have shown much empirical success in solving perceptual tasks across various cognitive modalities. While they are only loosely inspired by the biological brain, recent studies report considerable similarities between representation extracted from task-optimized ANNs and neural populations in the brain. ANNs have subsequently become a popular model class to infer computational principles underlying complex cognitive functions, and in turn they have also emerged as a natural testbed for applying methods originally developed to probe information in neural populations. In this work, we utilize mean-field theoretic manifold analysis, a recent technique from computational neuroscience, to analyze the high dimensional geometry of language representations from large-scale contextual embedding models. We explore representations from different model families (BERT, RoBERTa, GPT-2, etc. ) and find evidence for emergence of linguistic manifold across layer depth (e.g., manifolds for part-of-speech and combinatory categorical grammar tags). We further observe that different encoding schemes used to obtain the representations lead to differences in whether these linguistic manifolds emerge in earlier or later layers of the network. In addition, we find that the emergence of linear separability in these manifolds is driven by a combined reduction of manifolds radius, dimensionality and inter-manifold correlations.
Crowdsourcing a High-Quality Gold Standard for QA-SRL
Nov 08, 2019
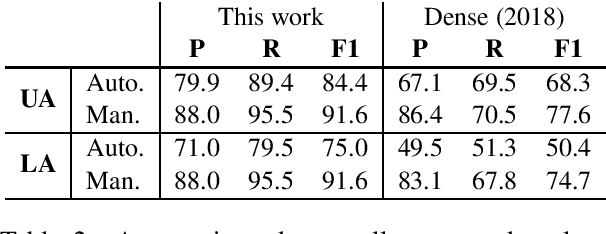
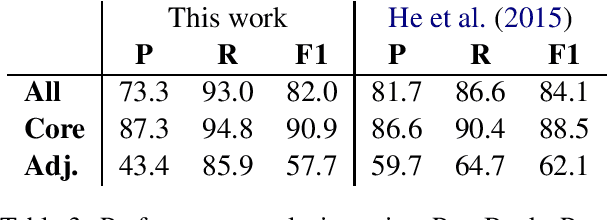
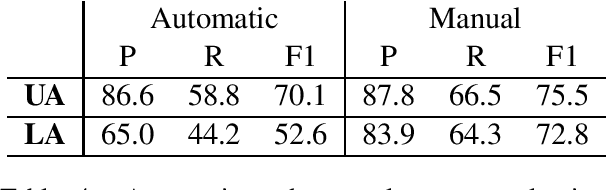
Question-answer driven Semantic Role Labeling (QA-SRL) has been proposed as an attractive open and natural form of SRL, easily crowdsourceable for new corpora. Recently, a large-scale QA-SRL corpus and a trained parser were released, accompanied by a densely annotated dataset for evaluation. Trying to replicate the QA-SRL annotation and evaluation scheme for new texts, we observed that the resulting annotations were lacking in quality and coverage, particularly insufficient for creating gold standards for evaluation. In this paper, we present an improved QA-SRL annotation protocol, involving crowd-worker selection and training, followed by data consolidation. Applying this process, we release a new gold evaluation dataset for QA-SRL, yielding more consistent annotations and greater coverage. We believe that our new annotation protocol and gold standard will facilitate future replicable research of natural semantic annotations.
Deep Mouse: An End-to-end Auto-context Refinement Framework for Brain Ventricle and Body Segmentation in Embryonic Mice Ultrasound Volumes
Oct 30, 2019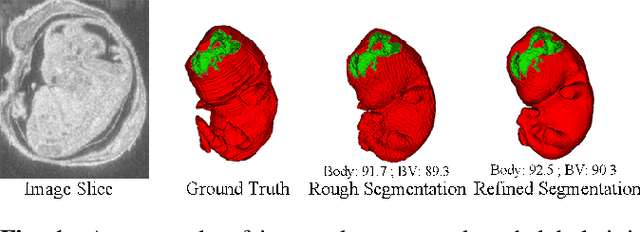
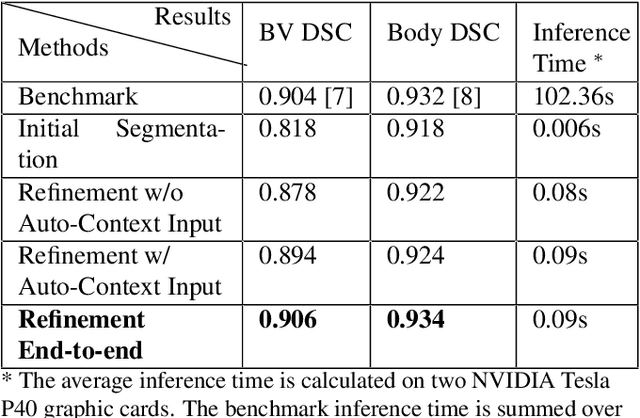
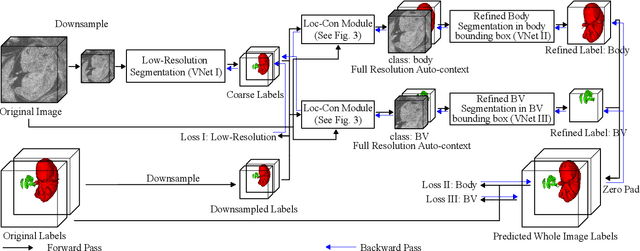
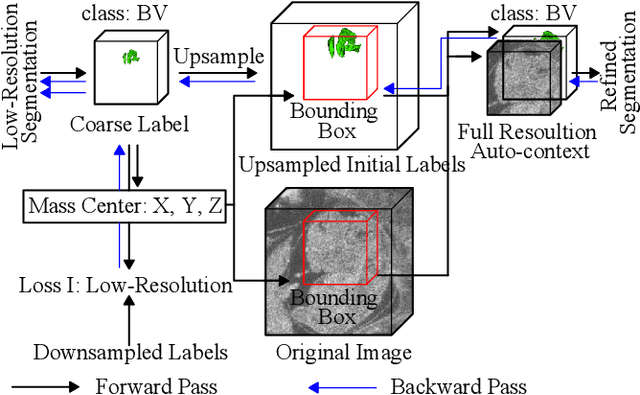
High-frequency ultrasound (HFU) is well suited for imaging embryonic mice due to its noninvasive and real-time characteristics. However, manual segmentation of the brain ventricles (BVs) and body requires substantial time and expertise. This work proposes a novel deep learning based end-to-end auto-context refinement framework, consisting of two stages. The first stage produces a low resolution segmentation of the BV and body simultaneously. The resulting probability map for each object (BV or body) is then used to crop a region of interest (ROI) around the target object in both the original image and the probability map to provide context to the refinement segmentation network. Joint training of the two stages provides significant improvement in Dice Similarity Coefficient (DSC) over using only the first stage (0.818 to 0.906 for the BV, and 0.919 to 0.934 for the body). The proposed method significantly reduces the inference time (102.36 to 0.09 s/volume around 1000x faster) while slightly improves the segmentation accuracy over the previous methods using slide-window approaches.
Automatic Mouse Embryo Brain Ventricle & Body Segmentation and Mutant Classification From Ultrasound Data Using Deep Learning
Sep 23, 2019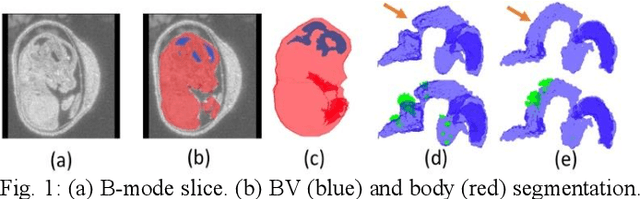
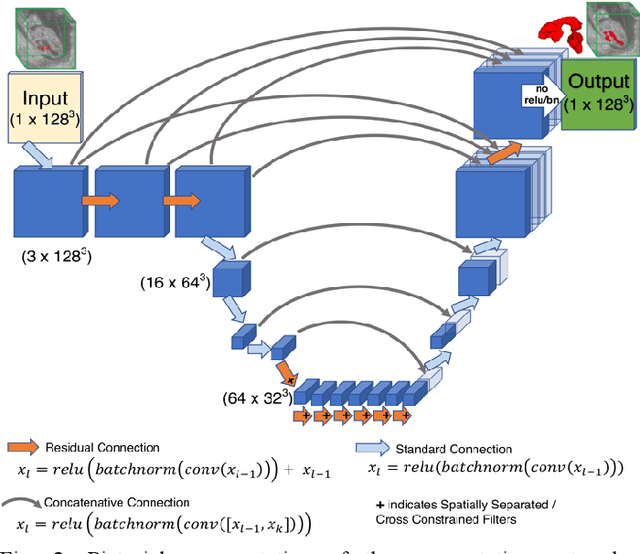
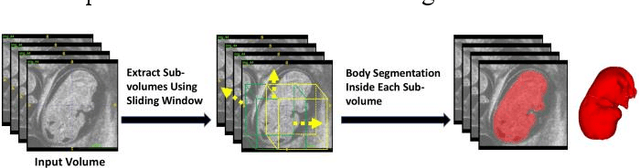

High-frequency ultrasound (HFU) is well suited for imaging embryonic mice in vivo because it is non-invasive and real-time. Manual segmentation of the brain ventricles (BVs) and whole body from 3D HFU images is time-consuming and requires specialized training. This paper presents a deep-learning-based segmentation pipeline which automates several time-consuming, repetitive tasks currently performed to study genetic mutations in developing mouse embryos. Namely, the pipeline accurately segments the BV and body regions in 3D HFU images of mouse embryos, despite significant challenges due to position and shape variation of the embryos, as well as imaging artifacts. Based on the BV segmentation, a 3D convolutional neural network (CNN) is further trained to detect embryos with the Engrailed-1 (En1) mutation. The algorithms achieve 0.896 and 0.925 Dice Similarity Coefficient (DSC) for BV and body segmentation, respectively, and 95.8% accuracy on mutant classification. Through gradient based interrogation and visualization of the trained classifier, it is demonstrated that the model focuses on the morphological structures known to be affected by the En1 mutation.