 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQuARE: Sequential Question Answering Reasoning Engine for Enhanced Chain-of-Thought in Large Language Models
Feb 13, 2025



In the rapidly evolving field of Natural Language Processing, Large Language Models (LLMs) are tasked with increasingly complex reasoning challenges. Traditional methods like chain-of-thought prompting have shown promise but often fall short in fully leveraging a model's reasoning capabilities. This paper introduces SQuARE (Sequential Question Answering Reasoning Engine), a novel prompting technique designed to improve reasoning through a self-interrogation paradigm. Building upon CoT frameworks, SQuARE prompts models to generate and resolve multiple auxiliary questions before tackling the main query, promoting a more thorough exploration of various aspects of a topic. Our expansive evaluations, conducted with Llama 3 and GPT-4o models across multiple question-answering datasets, demonstrate that SQuARE significantly surpasses traditional CoT prompts and existing rephrase-and-respond methods. By systematically decomposing queries, SQuARE advances LLM capabilities in reasoning tasks. The code is publicly available at https://github.com/IntelLabs/RAG-FiT/tree/square.
RAG Foundry: A Framework for Enhancing LLMs for Retrieval Augmented Generation
Aug 05, 2024

Implementing Retrieval-Augmented Generation (RAG) systems is inherently complex, requiring deep understanding of data, use cases, and intricate design decisions. Additionally, evaluating these systems presents significant challenges, necessitating assessment of both retrieval accuracy and generative quality through a multi-faceted approach. We introduce RAG Foundry, an open-source framework for augmenting large language models for RAG use cases. RAG Foundry integrates data creation, training, inference and evaluation into a single workflow, facilitating the creation of data-augmented datasets for training and evaluating large language models in RAG settings. This integration enables rapid prototyping and experimentation with various RAG techniques, allowing users to easily generate datasets and train RAG models using internal or specialized knowledge sources. We demonstrate the framework effectiveness by augmenting and fine-tuning Llama-3 and Phi-3 models with diverse RAG configurations, showcasing consistent improvements across three knowledge-intensive datasets. Code is released as open-source in https://github.com/IntelLabs/RAGFoundry.
Distributed Speculative Inference of Large Language Models
May 23, 2024Accelerating the inference of large language models (LLMs) is an important challenge in artificial intelligence. This paper introduces distributed speculative inference (DSI), a novel distributed inference algorithm that is provably faster than speculative inference (SI) [leviathan2023fast, chen2023accelerating, miao2023specinfer] and traditional autoregressive inference (non-SI). Like other SI algorithms, DSI works on frozen LLMs, requiring no training or architectural modifications, and it preserves the target distribution. Prior studies on SI have demonstrated empirical speedups (compared to non-SI) but require a fast and accurate drafter LLM. In practice, off-the-shelf LLMs often do not have matching drafters that are sufficiently fast and accurate. We show a gap: SI gets slower than non-SI when using slower or less accurate drafters. We close this gap by proving that DSI is faster than both SI and non-SI given any drafters. By orchestrating multiple instances of the target and drafters, DSI is not only faster than SI but also supports LLMs that cannot be accelerated with SI. Our simulations show speedups of off-the-shelf LLMs in realistic settings: DSI is 1.29-1.92x faster than SI.
Accelerating Speculative Decoding using Dynamic Speculation Length
May 07, 2024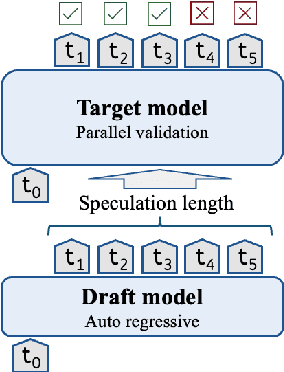


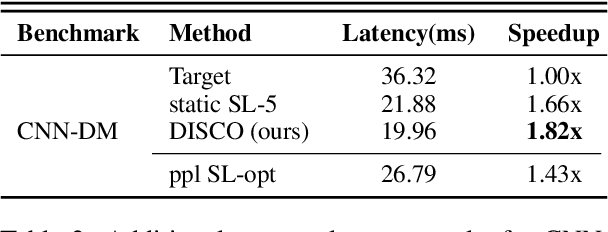
Speculative decoding is a promising method for reducing the inference latency of large language models. The effectiveness of the method depends on the speculation length (SL) - the number of tokens generated by the draft model at each iteration. The vast majority of speculative decoding approaches use the same SL for all iterations. In this work, we show that this practice is suboptimal. We introduce DISCO, a DynamIc SpeCulation length Optimization method that uses a classifier to dynamically adjust the SL at each iteration, while provably preserving the decoding quality. Experiments with four benchmarks demonstrate average speedup gains of 10.3% relative to our best baselines.
CoTAR: Chain-of-Thought Attribution Reasoning with Multi-level Granularity
Apr 16, 2024
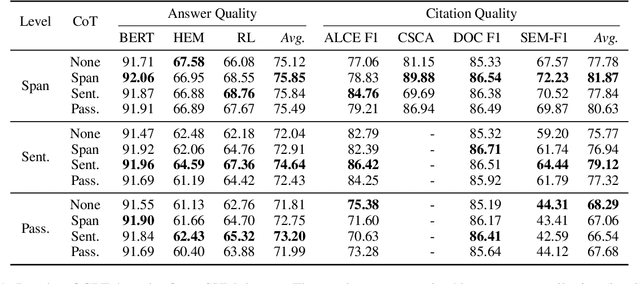
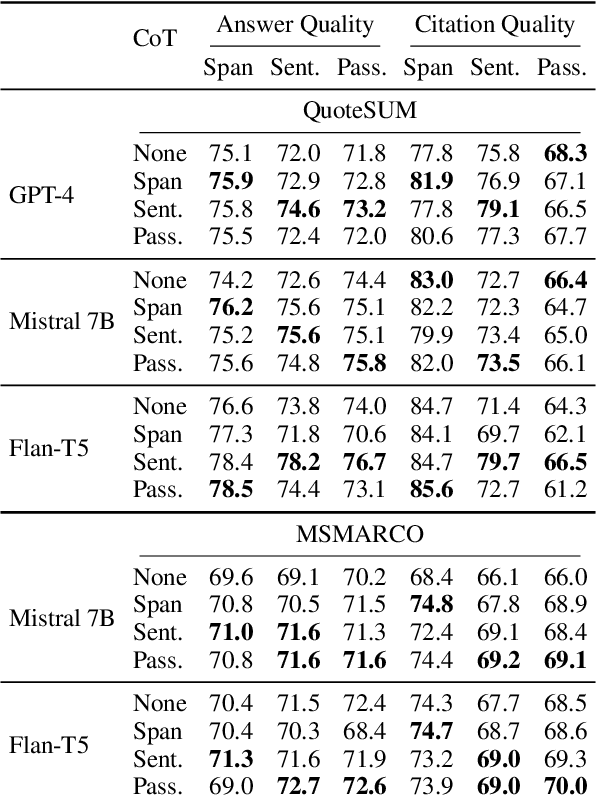
State-of-the-art performance in QA tasks is currently achieved by systems employing Large Language Models (LLMs), however these models tend to hallucinate information in their responses. One approach focuses on enhancing the generation process by incorporating attribution from the given input to the output. However, the challenge of identifying appropriate attributions and verifying their accuracy against a source is a complex task that requires significant improvements in assessing such systems. We introduce an attribution-oriented Chain-of-Thought reasoning method to enhance the accuracy of attributions. This approach focuses the reasoning process on generating an attribution-centric output. Evaluations on two context-enhanced question-answering datasets using GPT-4 demonstrate improved accuracy and correctness of attributions. In addition, the combination of our method with finetuning enhances the response and attribution accuracy of two smaller LLMs, showing their potential to outperform GPT-4 in some cases.
Optimizing Retrieval-augmented Reader Models via Token Elimination
Oct 20, 2023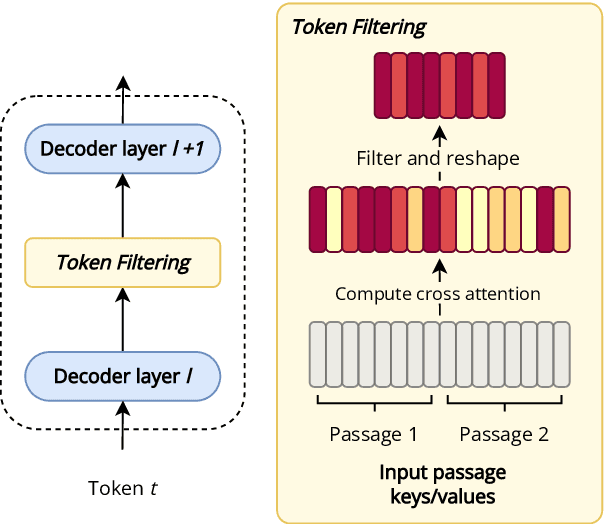
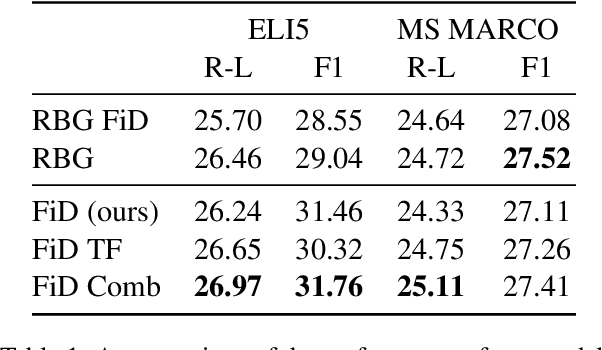
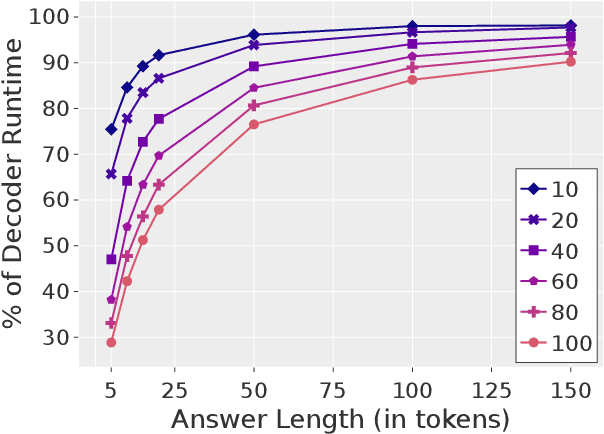
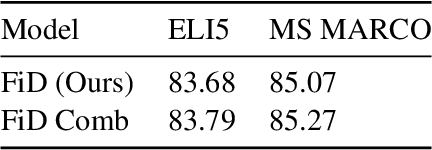
Fusion-in-Decoder (FiD) is an effective retrieval-augmented language model applied across a variety of open-domain tasks, such as question answering, fact checking, etc. In FiD, supporting passages are first retrieved and then processed using a generative model (Reader), which can cause a significant bottleneck in decoding time, particularly with long outputs. In this work, we analyze the contribution and necessity of all the retrieved passages to the performance of reader models, and propose eliminating some of the retrieved information, at the token level, that might not contribute essential information to the answer generation process. We demonstrate that our method can reduce run-time by up to 62.2%, with only a 2% reduction in performance, and in some cases, even improve the performance results.
How to Train BERT with an Academic Budget
Apr 15, 2021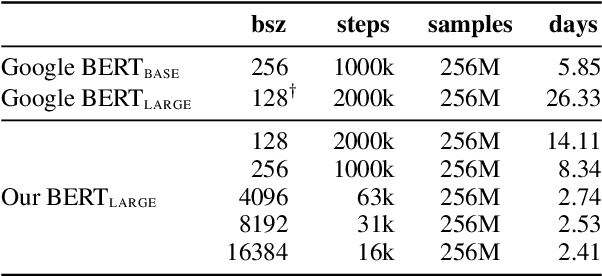
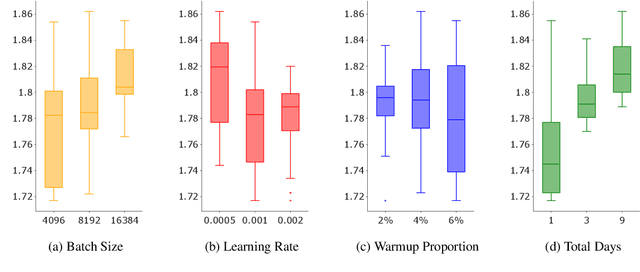
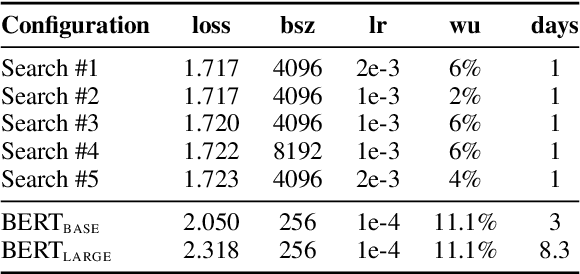
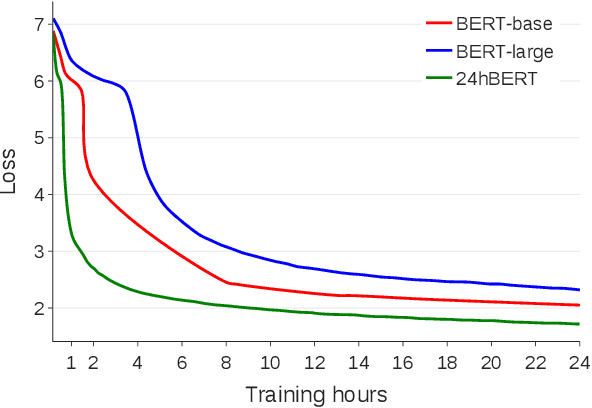
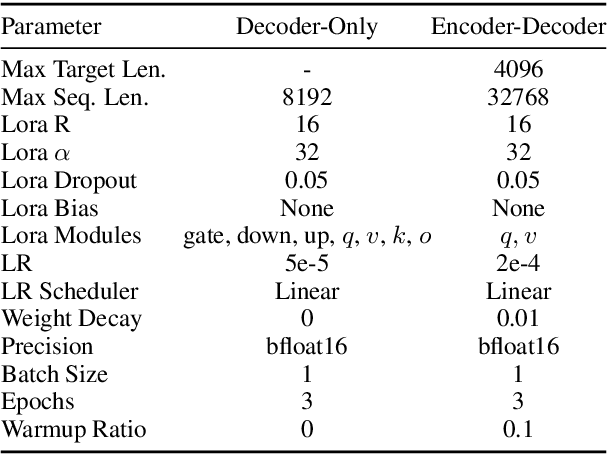
While large language models \`a la BERT are used ubiquitously in NLP, pretraining them is considered a luxury that only a few well-funded industry labs can afford. How can one train such models with a more modest budget? We present a recipe for pretraining a masked language model in 24 hours, using only 8 low-range 12GB GPUs. We demonstrate that through a combination of software optimizations, design choices, and hyperparameter tuning, it is possible to produce models that are competitive with BERT-base on GLUE tasks at a fraction of the original pretraining cost.