 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQuARE: Sequential Question Answering Reasoning Engine for Enhanced Chain-of-Thought in Large Language Models
Feb 13, 2025



In the rapidly evolving field of Natural Language Processing, Large Language Models (LLMs) are tasked with increasingly complex reasoning challenges. Traditional methods like chain-of-thought prompting have shown promise but often fall short in fully leveraging a model's reasoning capabilities. This paper introduces SQuARE (Sequential Question Answering Reasoning Engine), a novel prompting technique designed to improve reasoning through a self-interrogation paradigm. Building upon CoT frameworks, SQuARE prompts models to generate and resolve multiple auxiliary questions before tackling the main query, promoting a more thorough exploration of various aspects of a topic. Our expansive evaluations, conducted with Llama 3 and GPT-4o models across multiple question-answering datasets, demonstrate that SQuARE significantly surpasses traditional CoT prompts and existing rephrase-and-respond methods. By systematically decomposing queries, SQuARE advances LLM capabilities in reasoning tasks. The code is publicly available at https://github.com/IntelLabs/RAG-FiT/tree/square.
HELMET: How to Evaluate Long-Context Language Models Effectively and Thoroughly
Oct 03, 2024


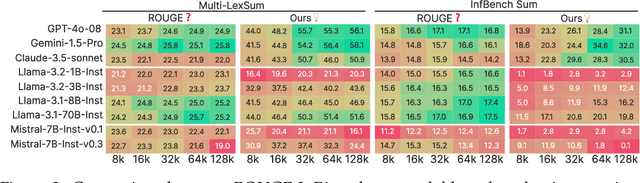
There have been many benchmarks for evaluating long-context language models (LCLMs), but developers often rely on synthetic tasks like needle-in-a-haystack (NIAH) or arbitrary subsets of tasks. It remains unclear whether they translate to the diverse downstream applications of LCLMs, and the inconsistency further complicates model comparison. We investigate the underlying reasons behind current practices and find that existing benchmarks often provide noisy signals due to low coverage of applications, insufficient lengths, unreliable metrics, and incompatibility with base models. In this work, we present HELMET (How to Evaluate Long-context Models Effectively and Thoroughly), a comprehensive benchmark encompassing seven diverse, application-centric categories. We also address many issues in previous benchmarks by adding controllable lengths up to 128k tokens, model-based evaluation for reliable metrics, and few-shot prompting for robustly evaluating base models. Consequently, we demonstrate that HELMET offers more reliable and consistent rankings of frontier LCLMs. Through a comprehensive study of 51 LCLMs, we find that (1) synthetic tasks like NIAH are not good predictors of downstream performance; (2) the diverse categories in HELMET exhibit distinct trends and low correlation with each other; and (3) while most LCLMs achieve perfect NIAH scores, open-source models significantly lag behind closed ones when the task requires full-context reasoning or following complex instructions -- the gap widens with increased lengths. Finally, we recommend using our RAG tasks for fast model development, as they are easy to run and more predictive of other downstream performance; ultimately, we advocate for a holistic evaluation across diverse tasks.
RAG Foundry: A Framework for Enhancing LLMs for Retrieval Augmented Generation
Aug 05, 2024

Implementing Retrieval-Augmented Generation (RAG) systems is inherently complex, requiring deep understanding of data, use cases, and intricate design decisions. Additionally, evaluating these systems presents significant challenges, necessitating assessment of both retrieval accuracy and generative quality through a multi-faceted approach. We introduce RAG Foundry, an open-source framework for augmenting large language models for RAG use cases. RAG Foundry integrates data creation, training, inference and evaluation into a single workflow, facilitating the creation of data-augmented datasets for training and evaluating large language models in RAG settings. This integration enables rapid prototyping and experimentation with various RAG techniques, allowing users to easily generate datasets and train RAG models using internal or specialized knowledge sources. We demonstrate the framework effectiveness by augmenting and fine-tuning Llama-3 and Phi-3 models with diverse RAG configurations, showcasing consistent improvements across three knowledge-intensive datasets. Code is released as open-source in https://github.com/IntelLabs/RAGFoundry.
CoTAR: Chain-of-Thought Attribution Reasoning with Multi-level Granularity
Apr 16, 2024
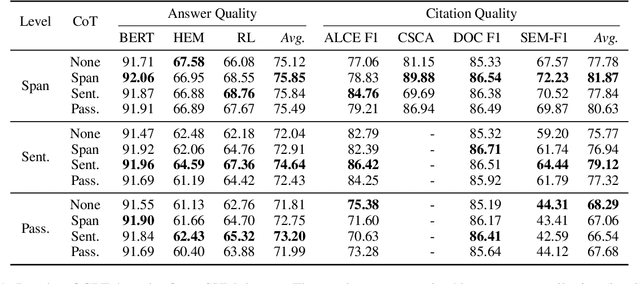
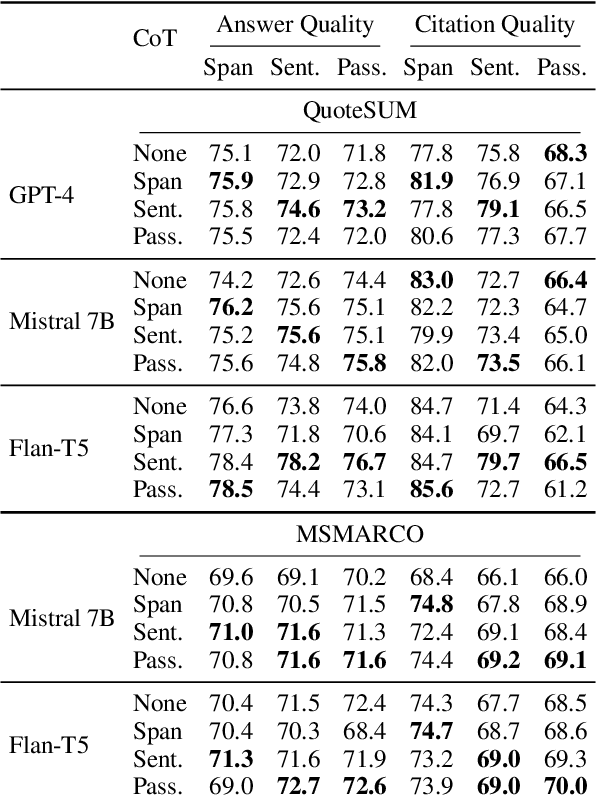
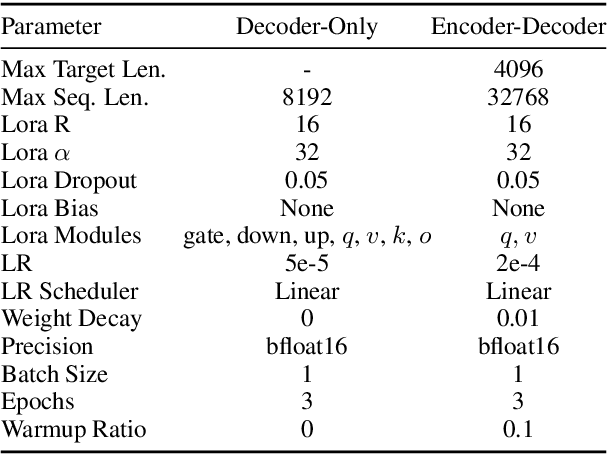
State-of-the-art performance in QA tasks is currently achieved by systems employing Large Language Models (LLMs), however these models tend to hallucinate information in their responses. One approach focuses on enhancing the generation process by incorporating attribution from the given input to the output. However, the challenge of identifying appropriate attributions and verifying their accuracy against a source is a complex task that requires significant improvements in assessing such systems. We introduce an attribution-oriented Chain-of-Thought reasoning method to enhance the accuracy of attributions. This approach focuses the reasoning process on generating an attribution-centric output. Evaluations on two context-enhanced question-answering datasets using GPT-4 demonstrate improved accuracy and correctness of attributions. In addition, the combination of our method with finetuning enhances the response and attribution accuracy of two smaller LLMs, showing their potential to outperform GPT-4 in some cases.
Latent Universal Task-Specific BERT
May 16, 2019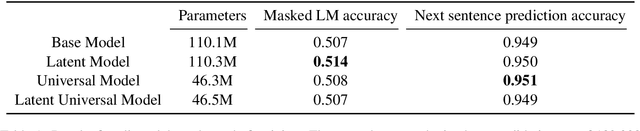
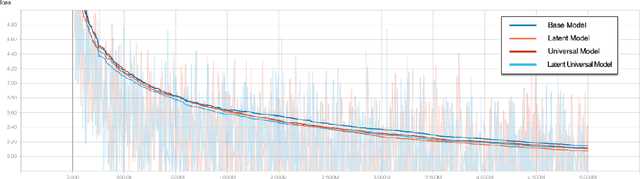
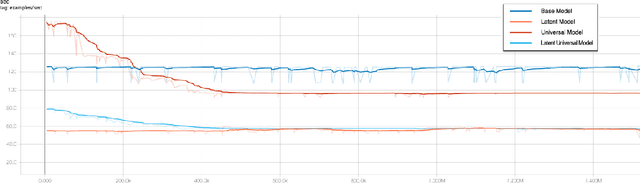
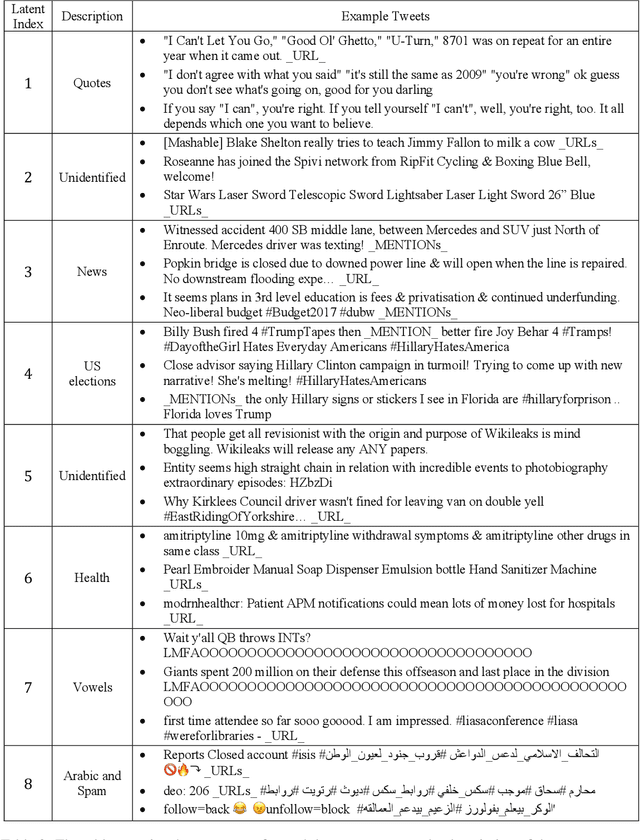
This paper describes a language representation model which combines the Bidirectional Encoder Representations from Transformers (BERT) learning mechanism described in Devlin et al. (2018) with a generalization of the Universal Transformer model described in Dehghani et al. (2018). We further improve this model by adding a latent variable that represents the persona and topics of interests of the writer for each training example. We also describe a simple method to improve the usefulness of our language representation for solving problems in a specific domain at the expense of its ability to generalize to other fields. Finally, we release a pre-trained language representation model for social texts that was trained on 100 million tweets.
Amobee at IEST 2018: Transfer Learning from Language Models
Oct 23, 2018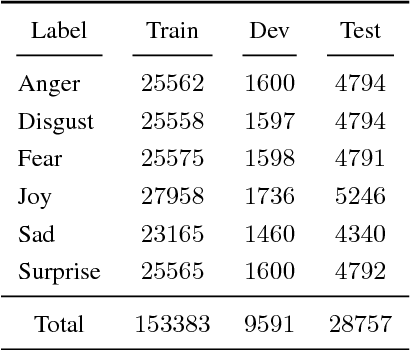
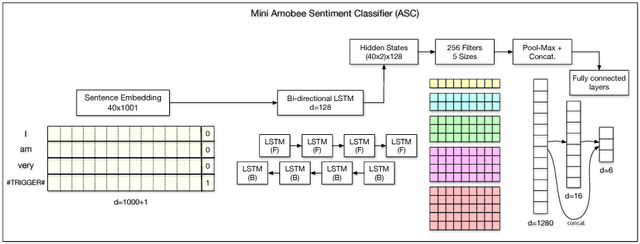
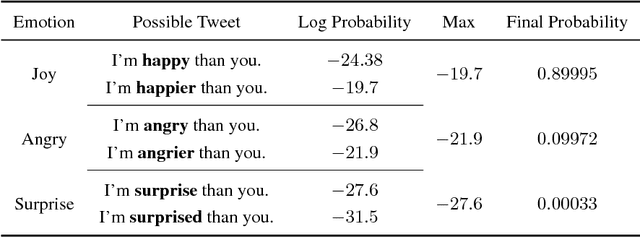
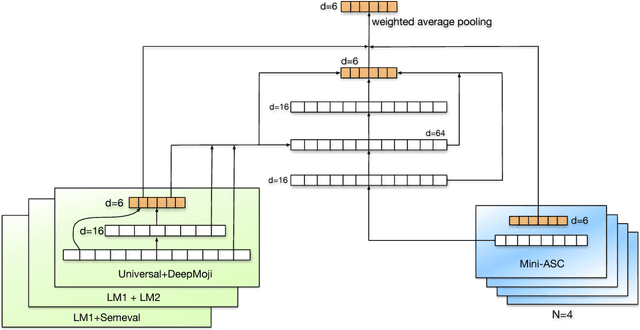
This paper describes the system developed at Amobee for the WASSA 2018 implicit emotions shared task (IEST). The goal of this task was to predict the emotion expressed by missing words in tweets without an explicit mention of those words. We developed an ensemble system consisting of language models together with LSTM-based networks containing a CNN attention mechanism. Our approach represents a novel use of language models (specifically trained on a large Twitter dataset) to predict and classify emotions. Our system reached 1st place with a macro $\text{F}_1$ score of 0.7145.
Amobee at SemEval-2018 Task 1: GRU Neural Network with a CNN Attention Mechanism for Sentiment Classification
Apr 12, 2018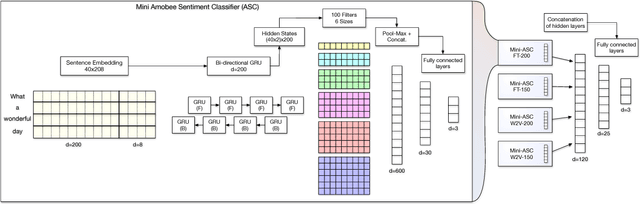

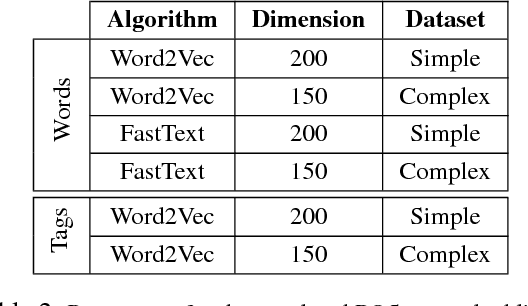
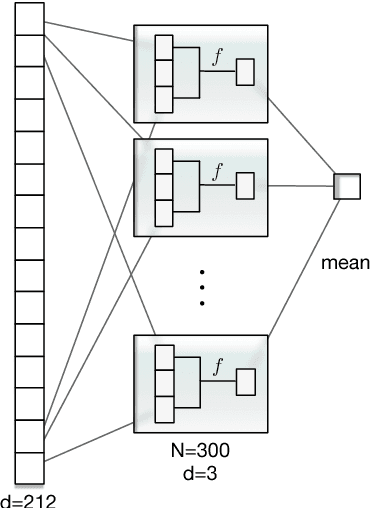
This paper describes the participation of Amobee in the shared sentiment analysis task at SemEval 2018. We participated in all the English sub-tasks and the Spanish valence tasks. Our system consists of three parts: training task-specific word embeddings, training a model consisting of gated-recurrent-units (GRU) with a convolution neural network (CNN) attention mechanism and training stacking-based ensembles for each of the sub-tasks. Our algorithm reached 3rd and 1st places in the valence ordinal classification sub-tasks in English and Spanish, respectively.
Amobee at SemEval-2017 Task 4: Deep Learning System for Sentiment Detection on Twitter
May 03, 2017

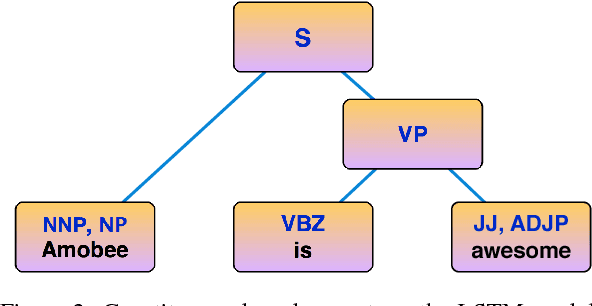
This paper describes the Amobee sentiment analysis system, adapted to compete in SemEval 2017 task 4. The system consists of two parts: a supervised training of RNN models based on a Twitter sentiment treebank, and the use of feedforward NN, Naive Bayes and logistic regression classifiers to produce predictions for the different sub-tasks. The algorithm reached the 3rd place on the 5-label classification task (sub-task C).