 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAG Foundry: A Framework for Enhancing LLMs for Retrieval Augmented Generation
Aug 05, 2024

Implementing Retrieval-Augmented Generation (RAG) systems is inherently complex, requiring deep understanding of data, use cases, and intricate design decisions. Additionally, evaluating these systems presents significant challenges, necessitating assessment of both retrieval accuracy and generative quality through a multi-faceted approach. We introduce RAG Foundry, an open-source framework for augmenting large language models for RAG use cases. RAG Foundry integrates data creation, training, inference and evaluation into a single workflow, facilitating the creation of data-augmented datasets for training and evaluating large language models in RAG settings. This integration enables rapid prototyping and experimentation with various RAG techniques, allowing users to easily generate datasets and train RAG models using internal or specialized knowledge sources. We demonstrate the framework effectiveness by augmenting and fine-tuning Llama-3 and Phi-3 models with diverse RAG configurations, showcasing consistent improvements across three knowledge-intensive datasets. Code is released as open-source in https://github.com/IntelLabs/RAGFoundry.
CoTAR: Chain-of-Thought Attribution Reasoning with Multi-level Granularity
Apr 16, 2024
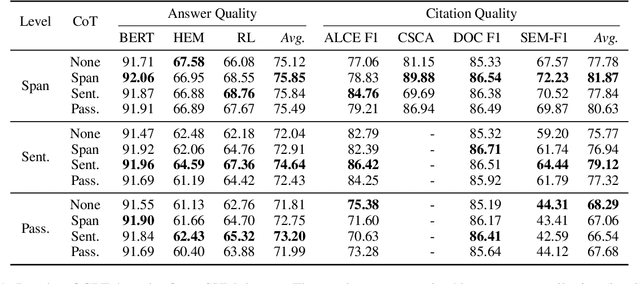
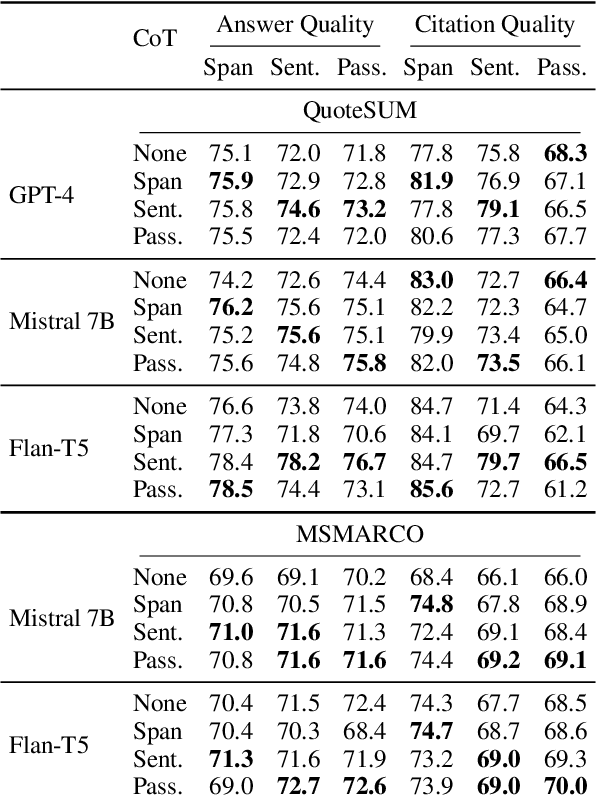
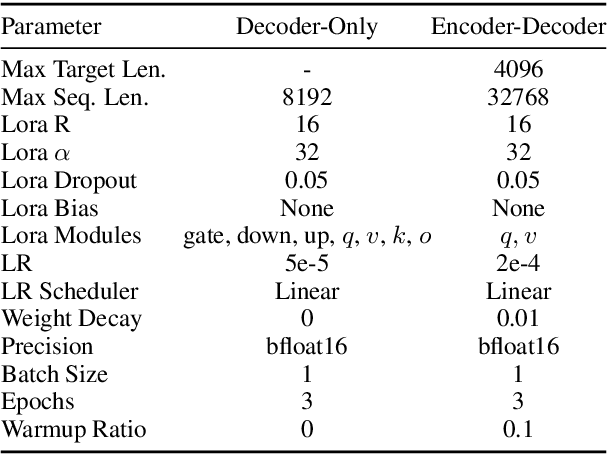
State-of-the-art performance in QA tasks is currently achieved by systems employing Large Language Models (LLMs), however these models tend to hallucinate information in their responses. One approach focuses on enhancing the generation process by incorporating attribution from the given input to the output. However, the challenge of identifying appropriate attributions and verifying their accuracy against a source is a complex task that requires significant improvements in assessing such systems. We introduce an attribution-oriented Chain-of-Thought reasoning method to enhance the accuracy of attributions. This approach focuses the reasoning process on generating an attribution-centric output. Evaluations on two context-enhanced question-answering datasets using GPT-4 demonstrate improved accuracy and correctness of attributions. In addition, the combination of our method with finetuning enhances the response and attribution accuracy of two smaller LLMs, showing their potential to outperform GPT-4 in some cases.
Optimizing Retrieval-augmented Reader Models via Token Elimination
Oct 20, 2023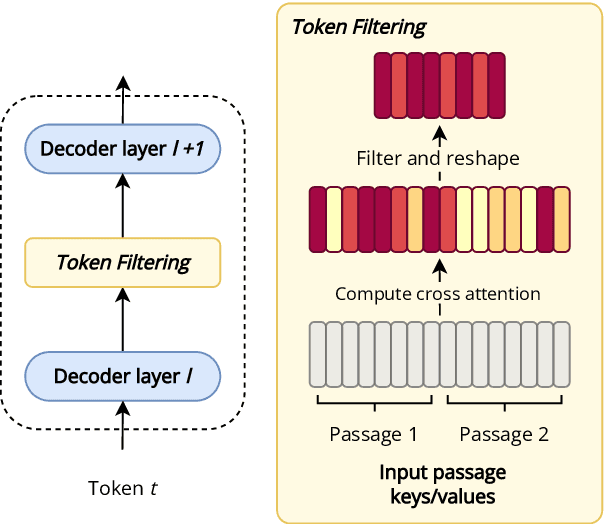
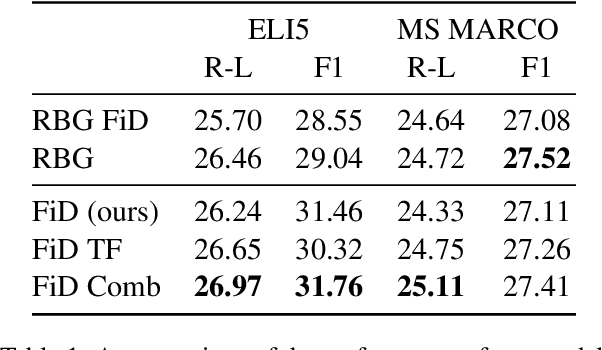
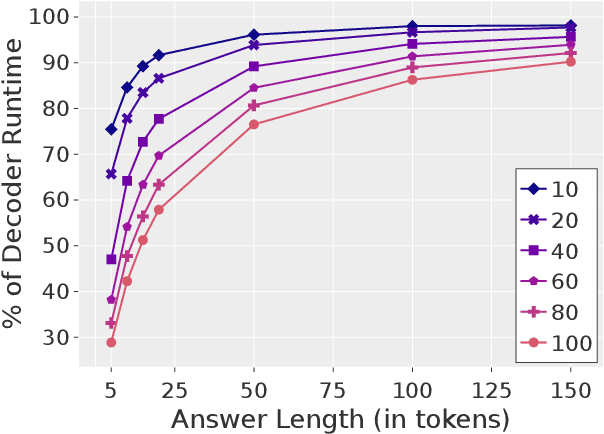
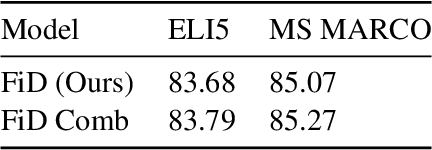
Fusion-in-Decoder (FiD) is an effective retrieval-augmented language model applied across a variety of open-domain tasks, such as question answering, fact checking, etc. In FiD, supporting passages are first retrieved and then processed using a generative model (Reader), which can cause a significant bottleneck in decoding time, particularly with long outputs. In this work, we analyze the contribution and necessity of all the retrieved passages to the performance of reader models, and propose eliminating some of the retrieved information, at the token level, that might not contribute essential information to the answer generation process. We demonstrate that our method can reduce run-time by up to 62.2%, with only a 2% reduction in performance, and in some cases, even improve the performance results.
Transformer Language Models without Positional Encodings Still Learn Positional Information
Mar 30, 2022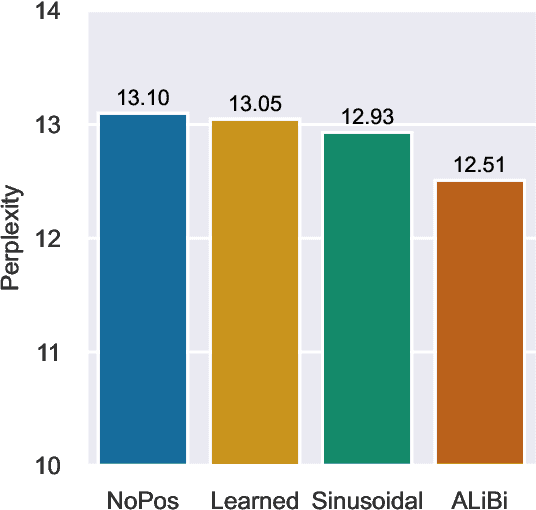
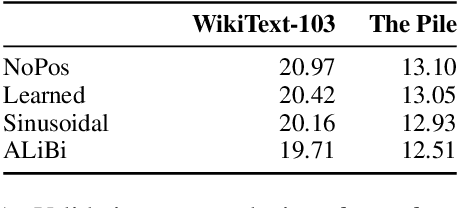
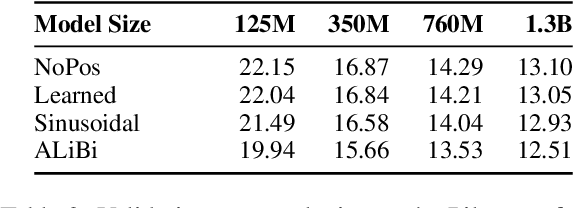
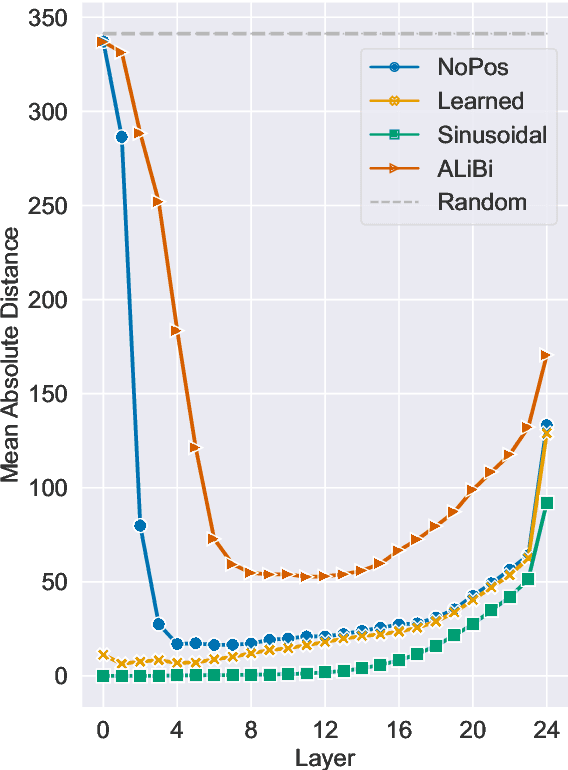
Transformers typically require some form of positional encoding, such as positional embeddings, to process natural language sequences. Surprisingly, we find that transformer language models without any explicit positional encoding are still competitive with standard models, and that this phenomenon is robust across different datasets, model sizes, and sequence lengths. Probing experiments reveal that such models acquire an implicit notion of absolute positions throughout the network, effectively compensating for the missing information. We conjecture that causal attention enables the model to infer the number of predecessors that each token can attend to, thereby approximating its absolute position.
How to Train BERT with an Academic Budget
Apr 15, 2021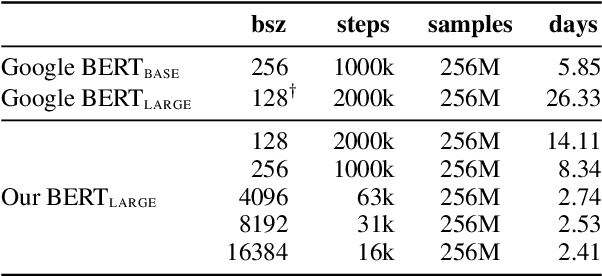
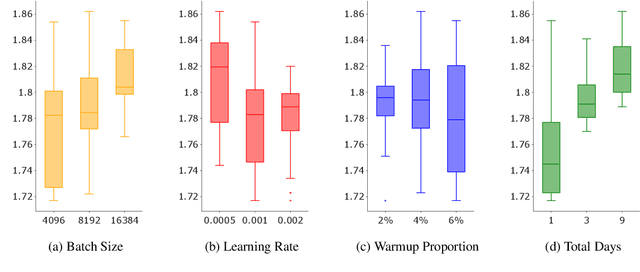
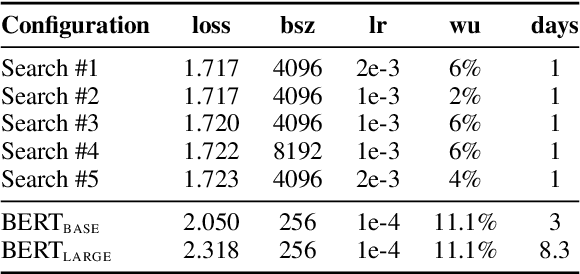
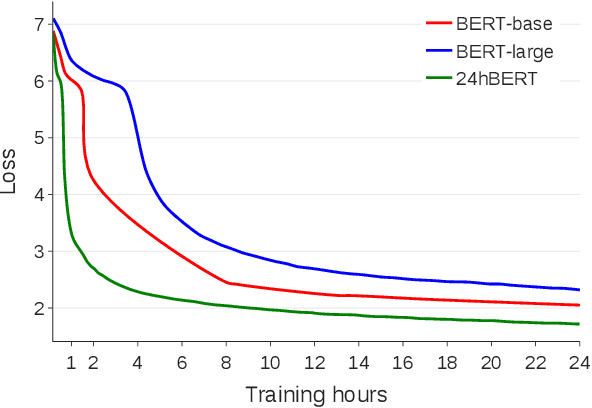
While large language models \`a la BERT are used ubiquitously in NLP, pretraining them is considered a luxury that only a few well-funded industry labs can afford. How can one train such models with a more modest budget? We present a recipe for pretraining a masked language model in 24 hours, using only 8 low-range 12GB GPUs. We demonstrate that through a combination of software optimizations, design choices, and hyperparameter tuning, it is possible to produce models that are competitive with BERT-base on GLUE tasks at a fraction of the original pretraining cost.
Q8BERT: Quantized 8Bit BERT
Oct 17, 2019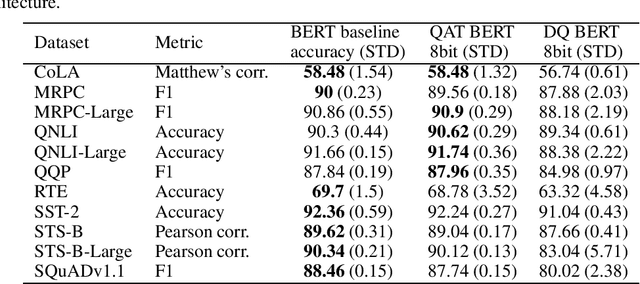

Recently, pre-trained Transformer based language models such as BERT and GPT, have shown great improvement in many Natural Language Processing (NLP) tasks. However, these models contain a large amount of parameters. The emergence of even larger and more accurate models such as GPT2 and Megatron, suggest a trend of large pre-trained Transformer models. However, using these large models in production environments is a complex task requiring a large amount of compute, memory and power resources. In this work we show how to perform quantization-aware training during the fine-tuning phase of BERT in order to compress BERT by $4\times$ with minimal accuracy loss. Furthermore, the produced quantized model can accelerate inference speed if it is optimized for 8bit Integer supporting hardware.
Training Compact Models for Low Resource Entity Tagging using Pre-trained Language Models
Oct 17, 2019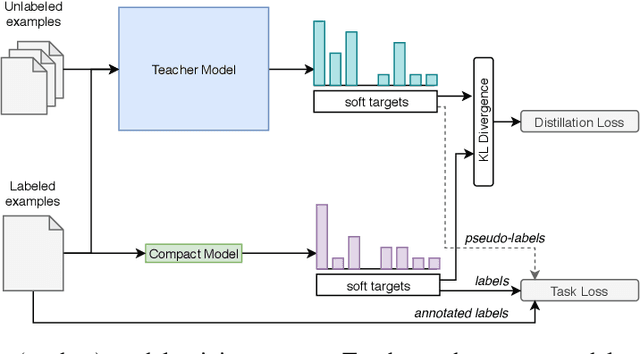
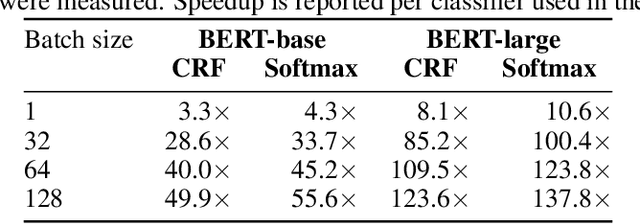
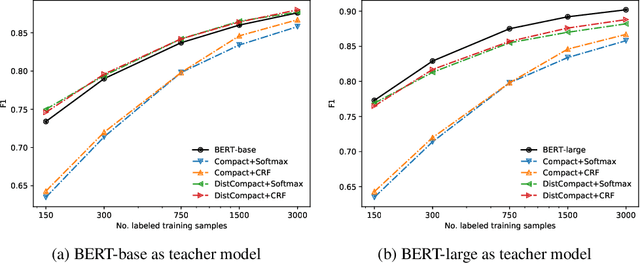
Training models on low-resource named entity recognition tasks has been shown to be a challenge, especially in industrial applications where deploying updated models is a continuous effort and crucial for business operations. In such cases there is often an abundance of unlabeled data, while labeled data is scarce or unavailable. Pre-trained language models trained to extract contextual features from text were shown to improve many natural language processing (NLP) tasks, including scarcely labeled tasks, by leveraging transfer learning. However, such models impose a heavy memory and computational burden, making it a challenge to train and deploy such models for inference use. In this work-in-progress we combined the effectiveness of transfer learning provided by pre-trained masked language models with a semi-supervised approach to train a fast and compact model using labeled and unlabeled examples. Preliminary evaluations show that the compact models can achieve competitive accuracy with 36x compression rate when compared with a state-of-the-art pre-trained language model, and run significantly faster in inference, allowing deployment of such models in production environments or on edge devices.
Term Set Expansion based NLP Architect by Intel AI Lab
Oct 15, 2018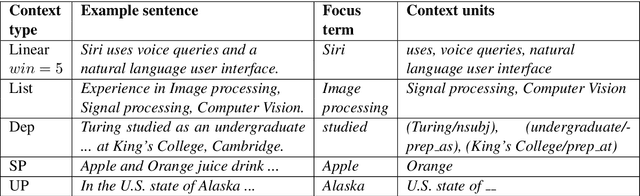

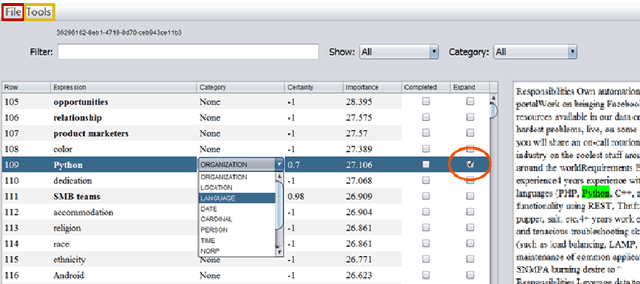
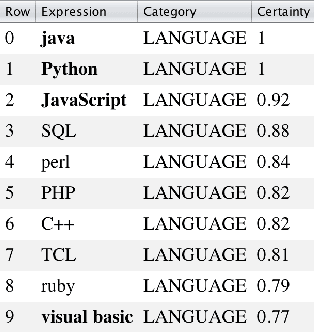
We present SetExpander, a corpus-based system for expanding a seed set of terms into amore complete set of terms that belong to the same semantic class. SetExpander implements an iterative end-to-end workflow. It enables users to easily select a seed set of terms, expand it, view the expanded set, validate it, re-expand the validated set and store it, thus simplifying the extraction of domain-specific fine-grained semantic classes.SetExpander has been used successfully in real-life use cases including integration into an automated recruitment system and an issues and defects resolution system. A video demo of SetExpander is available at https://drive.google.com/open?id=1e545bB87Autsch36DjnJHmq3HWfSd1Rv (some images were blurred for privacy reasons)
Term Set Expansion based on Multi-Context Term Embeddings: an End-to-end Workflow
Jul 26, 2018

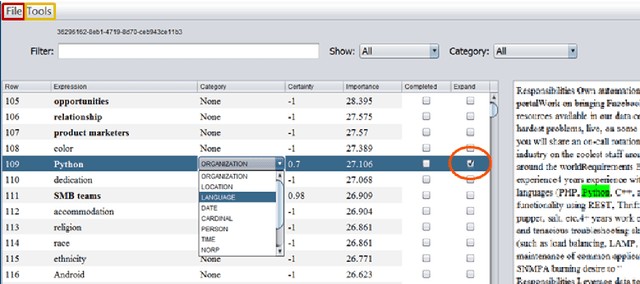
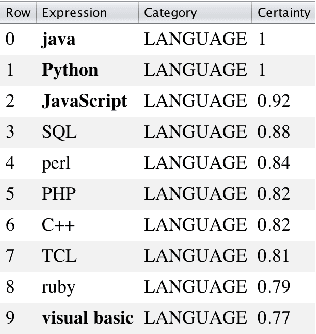
We present SetExpander, a corpus-based system for expanding a seed set of terms into a more complete set of terms that belong to the same semantic class. SetExpander implements an iterative end-to end workflow for term set expansion. It enables users to easily select a seed set of terms, expand it, view the expanded set, validate it, re-expand the validated set and store it, thus simplifying the extraction of domain-specific fine-grained semantic classes. SetExpander has been used for solving real-life use cases including integration in an automated recruitment system and an issues and defects resolution system. A video demo of SetExpander is available at https://drive.google.com/open?id=1e545bB87Autsch36DjnJHmq3HWfSd1Rv (some images were blurred for privacy reasons).