 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRAGged into Conflicts: Detecting and Addressing Conflicting Sources in Search-Augmented LLMs
Jun 10, 2025Retrieval Augmented Generation (RAG) is a commonly used approach for enhancing large language models (LLMs) with relevant and up-to-date information. However, the retrieved sources can often contain conflicting information and it remains unclear how models should address such discrepancies. In this work, we first propose a novel taxonomy of knowledge conflict types in RAG, along with the desired model behavior for each type. We then introduce CONFLICTS, a high-quality benchmark with expert annotations of conflict types in a realistic RAG setting. CONFLICTS is the first benchmark that enables tracking progress on how models address a wide range of knowledge conflicts. We conduct extensive experiments on this benchmark, showing that LLMs often struggle to appropriately resolve conflicts between sources. While prompting LLMs to explicitly reason about the potential conflict in the retrieved documents significantly improves the quality and appropriateness of their responses, substantial room for improvement in future research remains.
MetaFaith: Faithful Natural Language Uncertainty Expression in LLMs
May 30, 2025A critical component in the trustworthiness of LLMs is reliable uncertainty communication, yet LLMs often use assertive language when conveying false claims, leading to over-reliance and eroded trust. We present the first systematic study of $\textit{faithful confidence calibration}$ of LLMs, benchmarking models' ability to use linguistic expressions of uncertainty that $\textit{faithfully reflect}$ their intrinsic uncertainty, across a comprehensive array of models, datasets, and prompting strategies. Our results demonstrate that LLMs largely fail at this task, and that existing interventions are insufficient: standard prompt approaches provide only marginal gains, and existing, factuality-based calibration techniques can even harm faithful calibration. To address this critical gap, we introduce MetaFaith, a novel prompt-based calibration approach inspired by human metacognition. We show that MetaFaith robustly improves faithful calibration across diverse models and task domains, enabling up to 61% improvement in faithfulness and achieving an 83% win rate over original generations as judged by humans.
ReliableEval: A Recipe for Stochastic LLM Evaluation via Method of Moments
May 28, 2025LLMs are highly sensitive to prompt phrasing, yet standard benchmarks typically report performance using a single prompt, raising concerns about the reliability of such evaluations. In this work, we argue for a stochastic method of moments evaluation over the space of meaning-preserving prompt perturbations. We introduce a formal definition of reliable evaluation that accounts for prompt sensitivity, and suggest ReliableEval - a method for estimating the number of prompt resamplings needed to obtain meaningful results. Using our framework, we stochastically evaluate five frontier LLMs and find that even top-performing models like GPT-4o and Claude-3.7-Sonnet exhibit substantial prompt sensitivity. Our approach is model-, task-, and metric-agnostic, offering a recipe for meaningful and robust LLM evaluation.
MDCure: A Scalable Pipeline for Multi-Document Instruction-Following
Oct 30, 2024


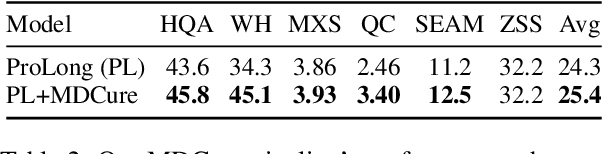
Multi-document (MD) processing is crucial for LLMs to handle real-world tasks such as summarization and question-answering across large sets of documents. While LLMs have improved at processing long inputs, MD contexts still present challenges, such as managing inter-document dependencies, redundancy, and incoherent structures. We introduce MDCure, a scalable and effective fine-tuning pipeline to enhance the MD capabilities of LLMs without the computational cost of pre-training or reliance on human annotated data. MDCure is based on generation of high-quality synthetic MD instruction data from sets of related articles via targeted prompts. We further introduce MDCureRM, a multi-objective reward model which filters generated data based on their training utility for MD settings. With MDCure, we fine-tune a variety of LLMs, from the FlanT5, Qwen2, and LLAMA3.1 model families, up to 70B parameters in size. Extensive evaluations on a wide range of MD and long-context benchmarks spanning various tasks show MDCure consistently improves performance over pre-trained baselines and over corresponding base models by up to 75.5%. Our code, datasets, and models are available at https://github.com/yale-nlp/MDCure.
CoverBench: A Challenging Benchmark for Complex Claim Verification
Aug 06, 2024
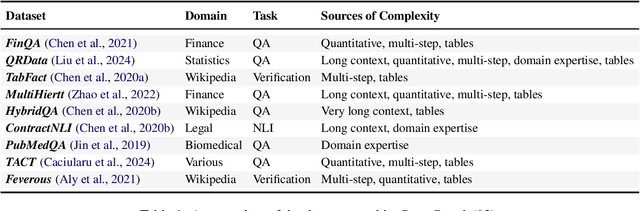
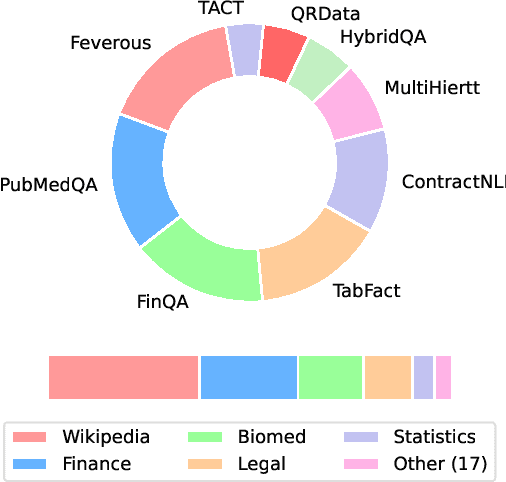
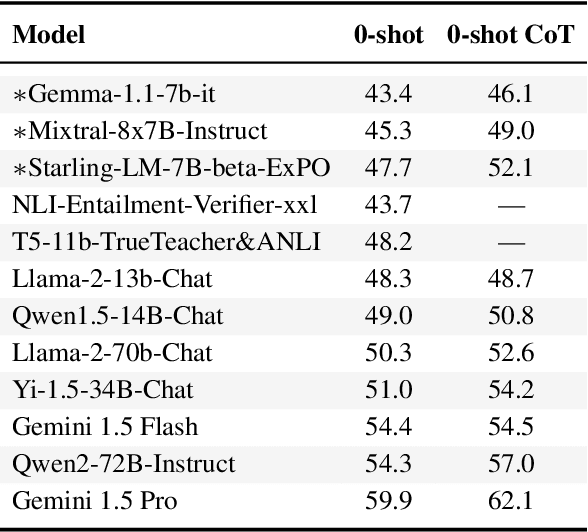
There is a growing line of research on verifying the correctness of language models' outputs. At the same time, LMs are being used to tackle complex queries that require reasoning. We introduce CoverBench, a challenging benchmark focused on verifying LM outputs in complex reasoning settings. Datasets that can be used for this purpose are often designed for other complex reasoning tasks (e.g., QA) targeting specific use-cases (e.g., financial tables), requiring transformations, negative sampling and selection of hard examples to collect such a benchmark. CoverBench provides a diversified evaluation for complex claim verification in a variety of domains, types of reasoning, relatively long inputs, and a variety of standardizations, such as multiple representations for tables where available, and a consistent schema. We manually vet the data for quality to ensure low levels of label noise. Finally, we report a variety of competitive baseline results to show CoverBench is challenging and has very significant headroom. The data is available at https://huggingface.co/datasets/google/coverbench .
SEAM: A Stochastic Benchmark for Multi-Document Tasks
Jun 23, 2024



Various tasks, such as summarization, multi-hop question answering, or coreference resolution, are naturally phrased over collections of real-world documents. Such tasks present a unique set of challenges, revolving around the lack of coherent narrative structure across documents, which often leads to contradiction, omission, or repetition of information. Despite their real-world application and challenging properties, there is currently no benchmark which specifically measures the abilities of large language models (LLMs) on multi-document tasks. To bridge this gap, we present SEAM (a Stochastic Evaluation Approach for Multi-document tasks), a conglomerate benchmark over a diverse set of multi-document datasets, setting conventional evaluation criteria, input-output formats, and evaluation protocols. In particular, SEAM addresses the sensitivity of LLMs to minor prompt variations through repeated evaluations, where in each evaluation we sample uniformly at random the values of arbitrary factors (e.g., the order of documents). We evaluate different LLMs on SEAM finding that multi-document tasks pose a significant challenge for LLMs, even for state-of-the-art models with 70B parameters. In addition, we show that the stochastic approach uncovers underlying statistical trends which cannot be observed in a static benchmark. We hope that SEAM will spur progress via consistent and meaningful evaluation of multi-document tasks.
Identifying User Goals from UI Trajectories
Jun 20, 2024
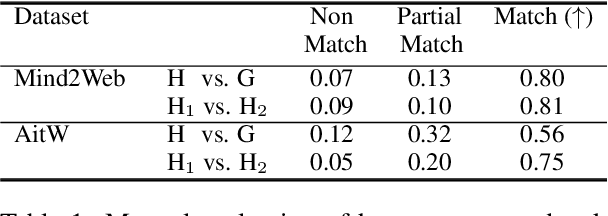
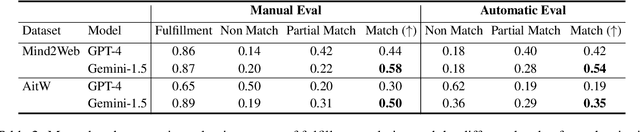
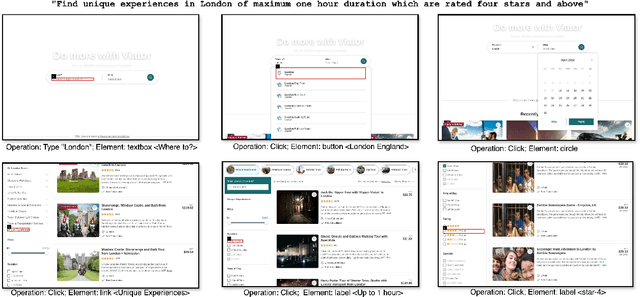
Autonomous agents that interact with graphical user interfaces (GUIs) hold significant potential for enhancing user experiences. To further improve these experiences, agents need to be personalized and proactive. By effectively comprehending user intentions through their actions and interactions with GUIs, agents will be better positioned to achieve these goals. This paper introduces the task of goal identification from observed UI trajectories, aiming to infer the user's intended task based on their GUI interactions. We propose a novel evaluation metric to assess whether two task descriptions are paraphrases within a specific UI environment. By Leveraging the inverse relation with the UI automation task, we utilized the Android-In-The-Wild and Mind2Web datasets for our experiments. Using our metric and these datasets, we conducted several experiments comparing the performance of humans and state-of-the-art models, specifically GPT-4 and Gemini-1.5 Pro. Our results show that Gemini performs better than GPT but still underperforms compared to humans, indicating significant room for improvement.
Can Few-shot Work in Long-Context? Recycling the Context to Generate Demonstrations
Jun 19, 2024Despite recent advancements in Large Language Models (LLMs), their performance on tasks involving long contexts remains sub-optimal. In-Context Learning (ICL) with few-shot examples may be an appealing solution to enhance LLM performance in this scenario; However, naively adding ICL examples with long context introduces challenges, including substantial token overhead added for each few-shot example and context mismatch between the demonstrations and the target query. In this work, we propose to automatically generate few-shot examples for long context QA tasks by recycling contexts. Specifically, given a long input context (1-3k tokens) and a query, we generate additional query-output pairs from the given context as few-shot examples, while introducing the context only once. This ensures that the demonstrations are leveraging the same context as the target query while only adding a small number of tokens to the prompt. We further enhance each demonstration by instructing the model to explicitly identify the relevant paragraphs before the answer, which improves performance while providing fine-grained attribution to the answer source. We apply our method on multiple LLMs and obtain substantial improvements on various QA datasets with long context, especially when the answer lies within the middle of the context. Surprisingly, despite introducing only single-hop ICL examples, LLMs also successfully generalize to multi-hop long-context QA using our approach.
TACT: Advancing Complex Aggregative Reasoning with Information Extraction Tools
Jun 05, 2024



Large Language Models (LLMs) often do not perform well on queries that require the aggregation of information across texts. To better evaluate this setting and facilitate modeling efforts, we introduce TACT - Text And Calculations through Tables, a dataset crafted to evaluate LLMs' reasoning and computational abilities using complex instructions. TACT contains challenging instructions that demand stitching information scattered across one or more texts, and performing complex integration on this information to generate the answer. We construct this dataset by leveraging an existing dataset of texts and their associated tables. For each such tables, we formulate new queries, and gather their respective answers. We demonstrate that all contemporary LLMs perform poorly on this dataset, achieving an accuracy below 38\%. To pinpoint the difficulties and thoroughly dissect the problem, we analyze model performance across three components: table-generation, Pandas command-generation, and execution. Unexpectedly, we discover that each component presents substantial challenges for current LLMs. These insights lead us to propose a focused modeling framework, which we refer to as IE as a tool. Specifically, we propose to add "tools" for each of the above steps, and implement each such tool with few-shot prompting. This approach shows an improvement over existing prompting techniques, offering a promising direction for enhancing model capabilities in these tasks.
Unpacking Tokenization: Evaluating Text Compression and its Correlation with Model Performance
Mar 10, 2024Despite it being the cornerstone of BPE, the most common tokenization algorithm, the importance of compression in the tokenization process is still unclear. In this paper, we argue for the theoretical importance of compression, that can be viewed as 0-gram language modeling where equal probability is assigned to all tokens. We also demonstrate the empirical importance of compression for downstream success of pre-trained language models. We control the compression ability of several BPE tokenizers by varying the amount of documents available during their training: from 1 million documents to a character-based tokenizer equivalent to no training data at all. We then pre-train English language models based on those tokenizers and fine-tune them over several tasks. We show that there is a correlation between tokenizers' compression and models' downstream performance, suggesting that compression is a reliable intrinsic indicator of tokenization quality. These correlations are more pronounced for generation tasks (over classification) or for smaller models (over large ones). We replicated a representative part of our experiments on Turkish and found similar results, confirming that our results hold for languages with typological characteristics dissimilar to English. We conclude that building better compressing tokenizers is a fruitful avenue for further research and for improving overall model performance.