 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Gemini in an arena for learning
May 30, 2025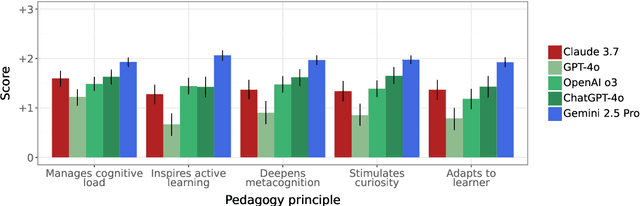

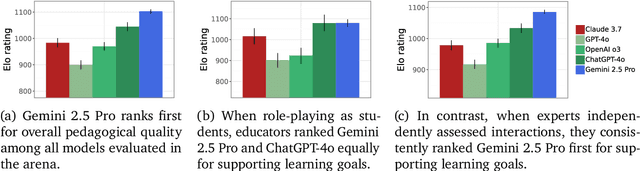
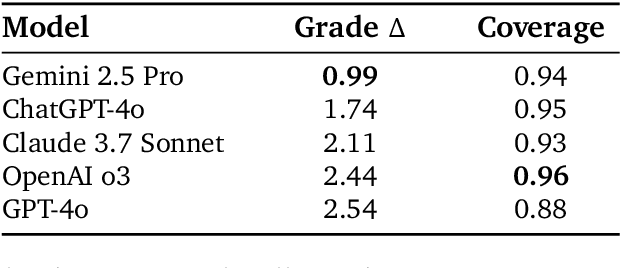
Artificial intelligence (AI) is poised to transform education, but the research community lacks a robust, general benchmark to evaluate AI models for learning. To assess state-of-the-art support for educational use cases, we ran an "arena for learning" where educators and pedagogy experts conduct blind, head-to-head, multi-turn comparisons of leading AI models. In particular, $N = 189$ educators drew from their experience to role-play realistic learning use cases, interacting with two models sequentially, after which $N = 206$ experts judged which model better supported the user's learning goals. The arena evaluated a slate of state-of-the-art models: Gemini 2.5 Pro, Claude 3.7 Sonnet, GPT-4o, and OpenAI o3. Excluding ties, experts preferred Gemini 2.5 Pro in 73.2% of these match-ups -- ranking it first overall in the arena. Gemini 2.5 Pro also demonstrated markedly higher performance across key principles of good pedagogy. Altogether, these results position Gemini 2.5 Pro as a leading model for learning.
Do LLMs have Consistent Values?
Jul 19, 2024Values are a basic driving force underlying human behavior. Large Language Models (LLM) technology is constantly improving towards human-like dialogue. However, little research has been done to study the values exhibited in text generated by LLMs. Here we study this question by turning to the rich literature on value structure in psychology. We ask whether LLMs exhibit the same value structure that has been demonstrated in humans, including the ranking of values, and correlation between values. We show that the results of this analysis strongly depend on how the LLM is prompted, and that under a particular prompting strategy (referred to as 'Value Anchoring') the agreement with human data is quite compelling. Our results serve both to improve our understanding of values in LLMs, as well as introduce novel methods for assessing consistency in LLM responses.
TACT: Advancing Complex Aggregative Reasoning with Information Extraction Tools
Jun 05, 2024



Large Language Models (LLMs) often do not perform well on queries that require the aggregation of information across texts. To better evaluate this setting and facilitate modeling efforts, we introduce TACT - Text And Calculations through Tables, a dataset crafted to evaluate LLMs' reasoning and computational abilities using complex instructions. TACT contains challenging instructions that demand stitching information scattered across one or more texts, and performing complex integration on this information to generate the answer. We construct this dataset by leveraging an existing dataset of texts and their associated tables. For each such tables, we formulate new queries, and gather their respective answers. We demonstrate that all contemporary LLMs perform poorly on this dataset, achieving an accuracy below 38\%. To pinpoint the difficulties and thoroughly dissect the problem, we analyze model performance across three components: table-generation, Pandas command-generation, and execution. Unexpectedly, we discover that each component presents substantial challenges for current LLMs. These insights lead us to propose a focused modeling framework, which we refer to as IE as a tool. Specifically, we propose to add "tools" for each of the above steps, and implement each such tool with few-shot prompting. This approach shows an improvement over existing prompting techniques, offering a promising direction for enhancing model capabilities in these tasks.
Covering Uncommon Ground: Gap-Focused Question Generation for Answer Assessment
Jul 06, 2023Human communication often involves information gaps between the interlocutors. For example, in an educational dialogue, a student often provides an answer that is incomplete, and there is a gap between this answer and the perfect one expected by the teacher. Successful dialogue then hinges on the teacher asking about this gap in an effective manner, thus creating a rich and interactive educational experience. We focus on the problem of generating such gap-focused questions (GFQs) automatically. We define the task, highlight key desired aspects of a good GFQ, and propose a model that satisfies these. Finally, we provide an evaluation by human annotators of our generated questions compared against human generated ones, demonstrating competitive performance.
Factually Consistent Summarization via Reinforcement Learning with Textual Entailment Feedback
May 31, 2023



Despite the seeming success of contemporary grounded text generation systems, they often tend to generate factually inconsistent text with respect to their input. This phenomenon is emphasized in tasks like summarization, in which the generated summaries should be corroborated by their source article. In this work, we leverage recent progress on textual entailment models to directly address this problem for abstractive summarization systems. We use reinforcement learning with reference-free, textual entailment rewards to optimize for factual consistency and explore the ensuing trade-offs, as improved consistency may come at the cost of less informative or more extractive summaries. Our results, according to both automatic metrics and human evaluation, show that our method considerably improves the faithfulness, salience, and conciseness of the generated summaries.
Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning
Jul 25, 2022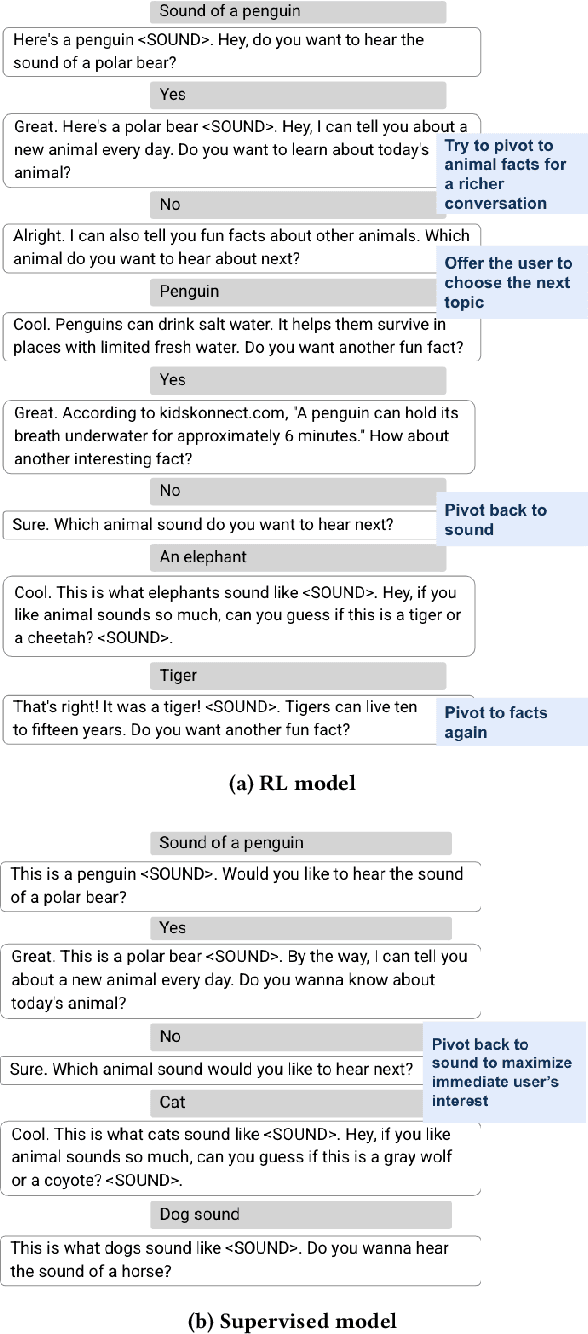
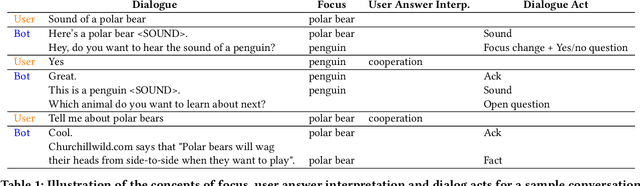

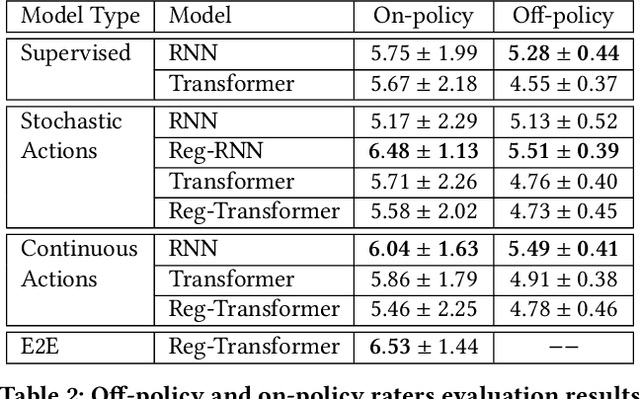
Despite recent advances in natural language understanding and generation, and decades of research on the development of conversational bots, building automated agents that can carry on rich open-ended conversations with humans "in the wild" remains a formidable challenge. In this work we develop a real-time, open-ended dialogue system that uses reinforcement learning (RL) to power a bot's conversational skill at scale. Our work pairs the succinct embedding of the conversation state generated using SOTA (supervised) language models with RL techniques that are particularly suited to a dynamic action space that changes as the conversation progresses. Trained using crowd-sourced data, our novel system is able to substantially exceeds the (strong) baseline supervised model with respect to several metrics of interest in a live experiment with real users of the Google Assistant.
Active Learning with Label Comparisons
Apr 10, 2022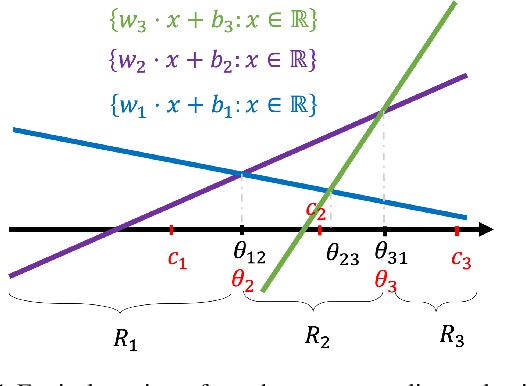
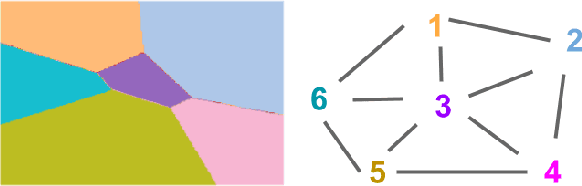
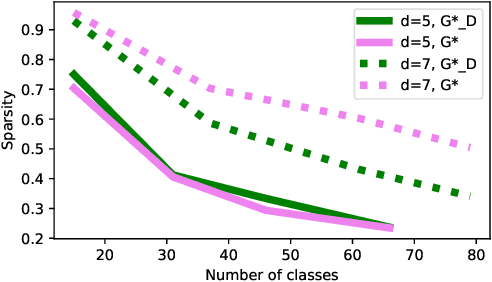
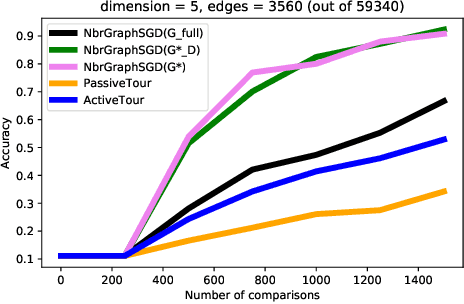
Supervised learning typically relies on manual annotation of the true labels. When there are many potential classes, searching for the best one can be prohibitive for a human annotator. On the other hand, comparing two candidate labels is often much easier. We focus on this type of pairwise supervision and ask how it can be used effectively in learning, and in particular in active learning. We obtain several insightful results in this context. In principle, finding the best of $k$ labels can be done with $k-1$ active queries. We show that there is a natural class where this approach is sub-optimal, and that there is a more comparison-efficient active learning scheme. A key element in our analysis is the "label neighborhood graph" of the true distribution, which has an edge between two classes if they share a decision boundary. We also show that in the PAC setting, pairwise comparisons cannot provide improved sample complexity in the worst case. We complement our theoretical results with experiments, clearly demonstrating the effect of the neighborhood graph on sample complexity.
Flood forecasting with machine learning models in an operational framework
Nov 04, 2021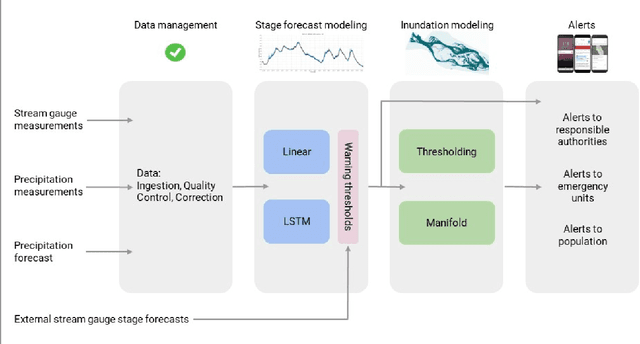
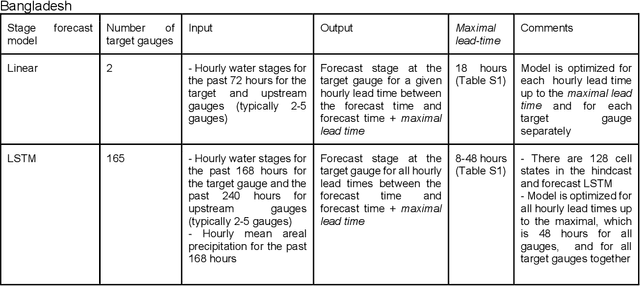
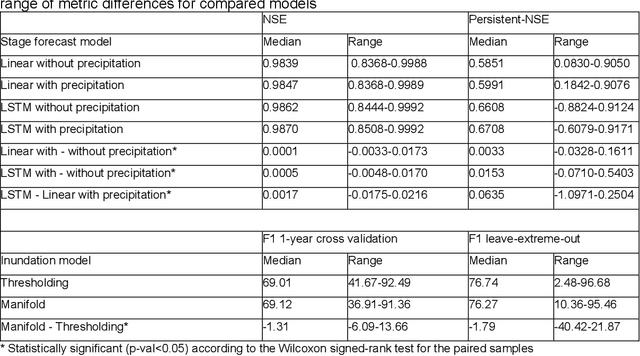
The operational flood forecasting system by Google was developed to provide accurate real-time flood warnings to agencies and the public, with a focus on riverine floods in large, gauged rivers. It became operational in 2018 and has since expanded geographically. This forecasting system consists of four subsystems: data validation, stage forecasting, inundation modeling, and alert distribution. Machine learning is used for two of the subsystems. Stage forecasting is modeled with the Long Short-Term Memory (LSTM) networks and the Linear models. Flood inundation is computed with the Thresholding and the Manifold models, where the former computes inundation extent and the latter computes both inundation extent and depth. The Manifold model, presented here for the first time, provides a machine-learning alternative to hydraulic modeling of flood inundation. When evaluated on historical data, all models achieve sufficiently high-performance metrics for operational use. The LSTM showed higher skills than the Linear model, while the Thresholding and Manifold models achieved similar performance metrics for modeling inundation extent. During the 2021 monsoon season, the flood warning system was operational in India and Bangladesh, covering flood-prone regions around rivers with a total area of 287,000 km2, home to more than 350M people. More than 100M flood alerts were sent to affected populations, to relevant authorities, and to emergency organizations. Current and future work on the system includes extending coverage to additional flood-prone locations, as well as improving modeling capabilities and accuracy.
Solving Sokoban with forward-backward reinforcement learning
May 22, 2021
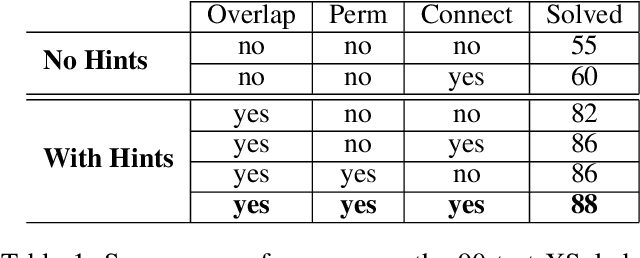
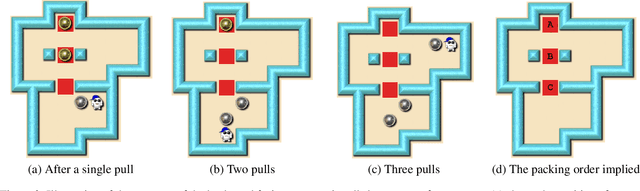
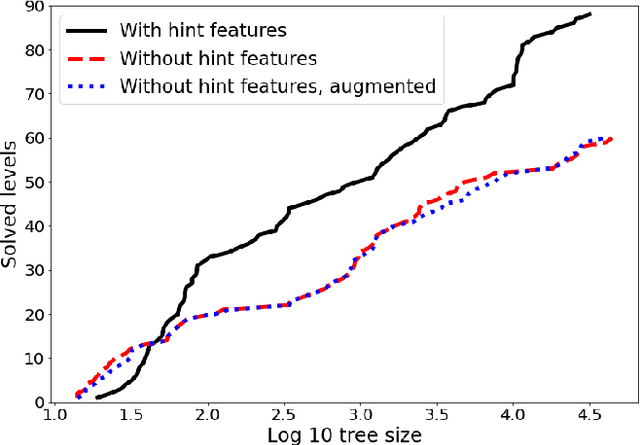
Despite seminal advances in reinforcement learning in recent years, many domains where the rewards are sparse, e.g. given only at task completion, remain quite challenging. In such cases, it can be beneficial to tackle the task both from its beginning and end, and make the two ends meet. Existing approaches that do so, however, are not effective in the common scenario where the strategy needed near the end goal is very different from the one that is effective earlier on. In this work we propose a novel RL approach for such settings. In short, we first train a backward-looking agent with a simple relaxed goal, and then augment the state representation of the forward-looking agent with straightforward hint features. This allows the learned forward agent to leverage information from backward plans, without mimicking their policy. We demonstrate the efficacy of our approach on the challenging game of Sokoban, where we substantially surpass learned solvers that generalize across levels, and are competitive with SOTA performance of the best highly-crafted systems. Impressively, we achieve these results while learning from a small number of practice levels and using simple RL techniques.
Explaining in Style: Training a GAN to explain a classifier in StyleSpace
Apr 27, 2021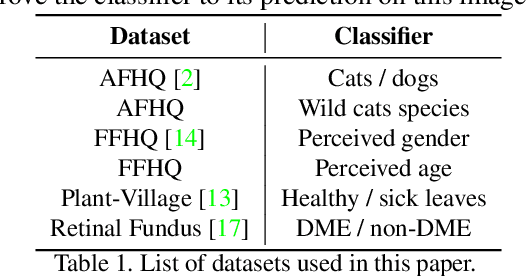
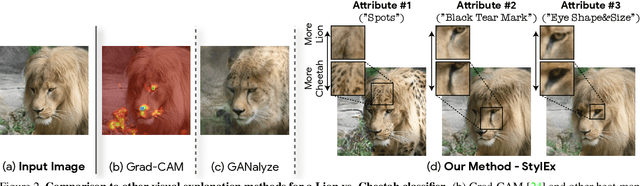
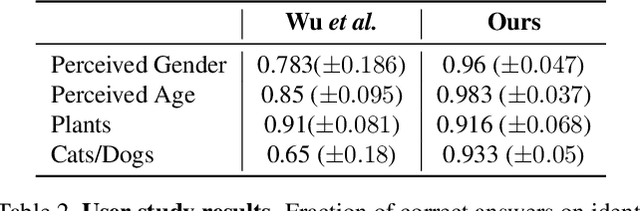
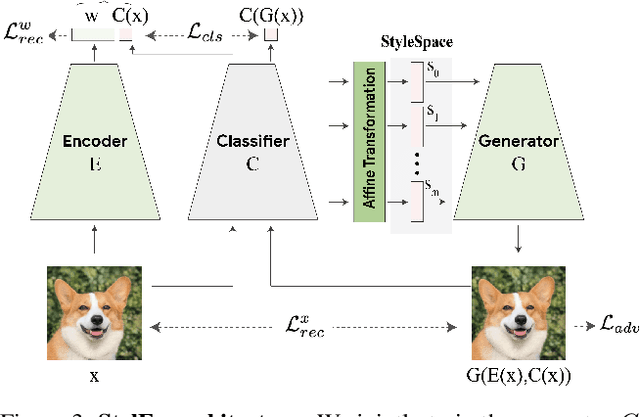
Image classification models can depend on multiple different semantic attributes of the image. An explanation of the decision of the classifier needs to both discover and visualize these properties. Here we present StylEx, a method for doing this, by training a generative model to specifically explain multiple attributes that underlie classifier decisions. A natural source for such attributes is the StyleSpace of StyleGAN, which is known to generate semantically meaningful dimensions in the image. However, because standard GAN training is not dependent on the classifier, it may not represent these attributes which are important for the classifier decision, and the dimensions of StyleSpace may represent irrelevant attributes. To overcome this, we propose a training procedure for a StyleGAN, which incorporates the classifier model, in order to learn a classifier-specific StyleSpace. Explanatory attributes are then selected from this space. These can be used to visualize the effect of changing multiple attributes per image, thus providing image-specific explanations. We apply StylEx to multiple domains, including animals, leaves, faces and retinal images. For these, we show how an image can be modified in different ways to change its classifier output. Our results show that the method finds attributes that align well with semantic ones, generate meaningful image-specific explanations, and are human-interpretable as measured in user-studies.