 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre LLMs Better than Reported? Detecting Label Errors and Mitigating Their Effect on Model Performance
Oct 24, 2024



NLP benchmarks rely on standardized datasets for training and evaluating models and are crucial for advancing the field. Traditionally, expert annotations ensure high-quality labels; however, the cost of expert annotation does not scale well with the growing demand for larger datasets required by modern models. While crowd-sourcing provides a more scalable solution, it often comes at the expense of annotation precision and consistency. Recent advancements in large language models (LLMs) offer new opportunities to enhance the annotation process, particularly for detecting label errors in existing datasets. In this work, we consider the recent approach of LLM-as-a-judge, leveraging an ensemble of LLMs to flag potentially mislabeled examples. Through a case study of four datasets from the TRUE benchmark, covering different tasks and domains, we empirically analyze the labeling quality of existing datasets, and compare expert, crowd-sourced, and our LLM-based annotations in terms of agreement, label quality, and efficiency, demonstrating the strengths and limitations of each annotation method. Our findings reveal a substantial number of label errors, which, when corrected, induce a significant upward shift in reported model performance. This suggests that many of the LLMs so-called mistakes are due to label errors rather than genuine model failures. Additionally, we discuss the implications of mislabeled data and propose methods to mitigate them in training to improve model performance.
Multi-turn Reinforcement Learning from Preference Human Feedback
May 23, 2024



Reinforcement Learning from Human Feedback (RLHF) has become the standard approach for aligning Large Language Models (LLMs) with human preferences, allowing LLMs to demonstrate remarkable abilities in various tasks. Existing methods work by emulating the preferences at the single decision (turn) level, limiting their capabilities in settings that require planning or multi-turn interactions to achieve a long-term goal. In this paper, we address this issue by developing novel methods for Reinforcement Learning (RL) from preference feedback between two full multi-turn conversations. In the tabular setting, we present a novel mirror-descent-based policy optimization algorithm for the general multi-turn preference-based RL problem, and prove its convergence to Nash equilibrium. To evaluate performance, we create a new environment, Education Dialogue, where a teacher agent guides a student in learning a random topic, and show that a deep RL variant of our algorithm outperforms RLHF baselines. Finally, we show that in an environment with explicit rewards, our algorithm recovers the same performance as a reward-based RL baseline, despite relying solely on a weaker preference signal.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Factually Consistent Summarization via Reinforcement Learning with Textual Entailment Feedback
May 31, 2023



Despite the seeming success of contemporary grounded text generation systems, they often tend to generate factually inconsistent text with respect to their input. This phenomenon is emphasized in tasks like summarization, in which the generated summaries should be corroborated by their source article. In this work, we leverage recent progress on textual entailment models to directly address this problem for abstractive summarization systems. We use reinforcement learning with reference-free, textual entailment rewards to optimize for factual consistency and explore the ensuing trade-offs, as improved consistency may come at the cost of less informative or more extractive summaries. Our results, according to both automatic metrics and human evaluation, show that our method considerably improves the faithfulness, salience, and conciseness of the generated summaries.
Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning
Jul 25, 2022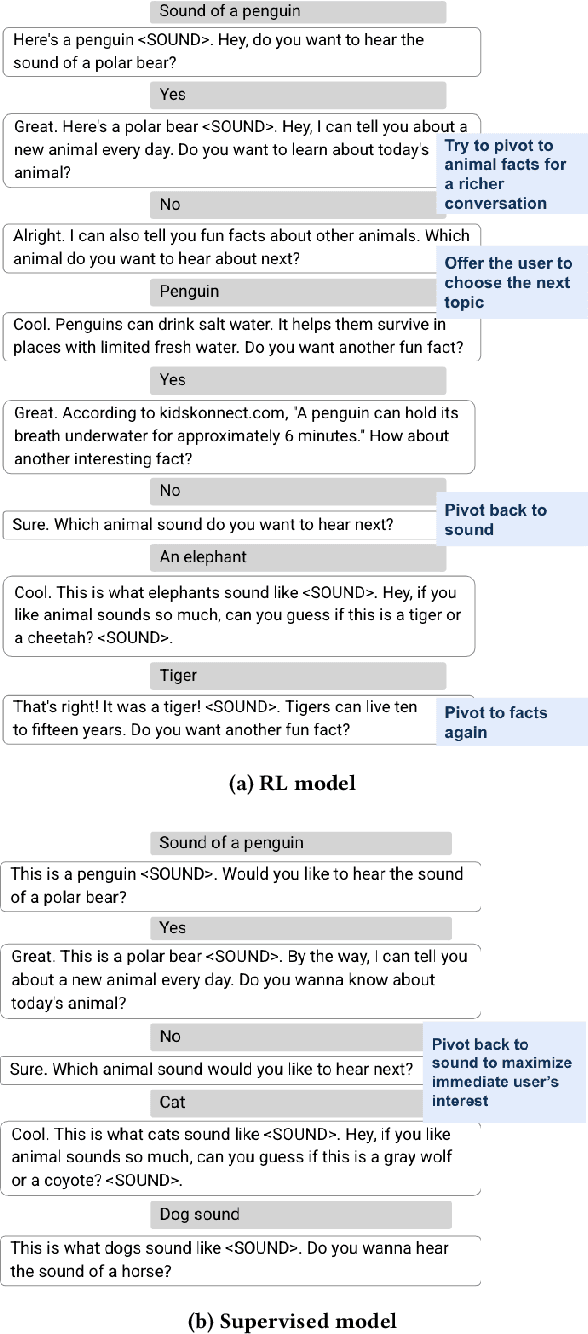
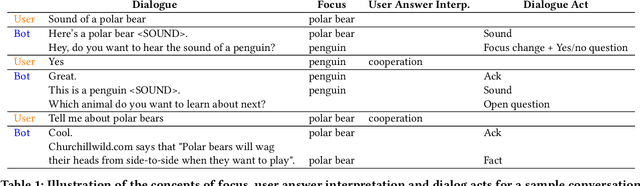

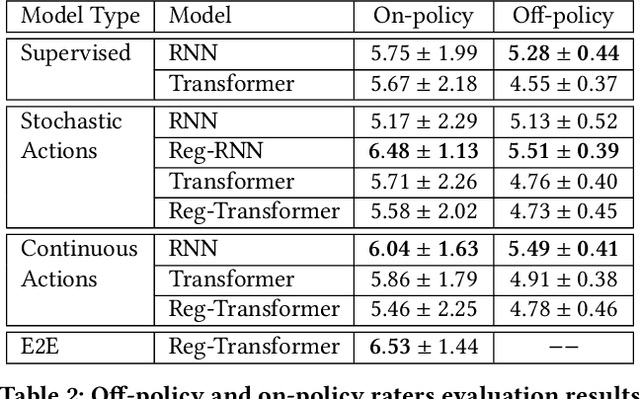
Despite recent advances in natural language understanding and generation, and decades of research on the development of conversational bots, building automated agents that can carry on rich open-ended conversations with humans "in the wild" remains a formidable challenge. In this work we develop a real-time, open-ended dialogue system that uses reinforcement learning (RL) to power a bot's conversational skill at scale. Our work pairs the succinct embedding of the conversation state generated using SOTA (supervised) language models with RL techniques that are particularly suited to a dynamic action space that changes as the conversation progresses. Trained using crowd-sourced data, our novel system is able to substantially exceeds the (strong) baseline supervised model with respect to several metrics of interest in a live experiment with real users of the Google Assistant.
On the Robustness of Dialogue History Representation in Conversational Question Answering: A Comprehensive Study and a New Prompt-based Method
Jun 29, 2022
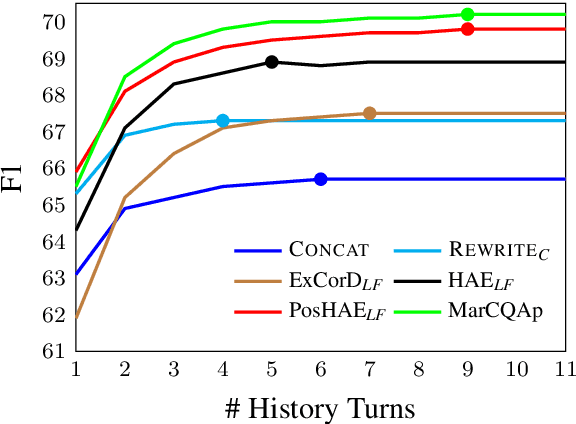
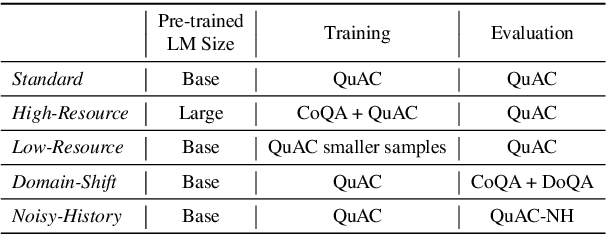
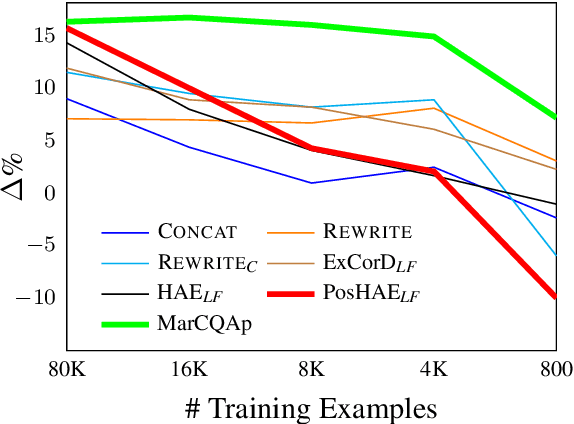
Most works on modeling the conversation history in Conversational Question Answering (CQA) report a single main result on a common CQA benchmark. While existing models show impressive results on CQA leaderboards, it remains unclear whether they are robust to shifts in setting (sometimes to more realistic ones), training data size (e.g. from large to small sets) and domain. In this work, we design and conduct the first large-scale robustness study of history modeling approaches for CQA. We find that high benchmark scores do not necessarily translate to strong robustness, and that various methods can perform extremely differently under different settings. Equipped with the insights from our study, we design a novel prompt-based history modeling approach, and demonstrate its strong robustness across various settings. Our approach is inspired by existing methods that highlight historic answers in the passage. However, instead of highlighting by modifying the passage token embeddings, we add textual prompts directly in the passage text. Our approach is simple, easy-to-plug into practically any model, and highly effective, thus we recommend it as a starting point for future model developers. We also hope that our study and insights will raise awareness to the importance of robustness-focused evaluation, in addition to obtaining high leaderboard scores, leading to better CQA systems.
Semantically Driven Sentence Fusion: Modeling and Evaluation
Oct 06, 2020
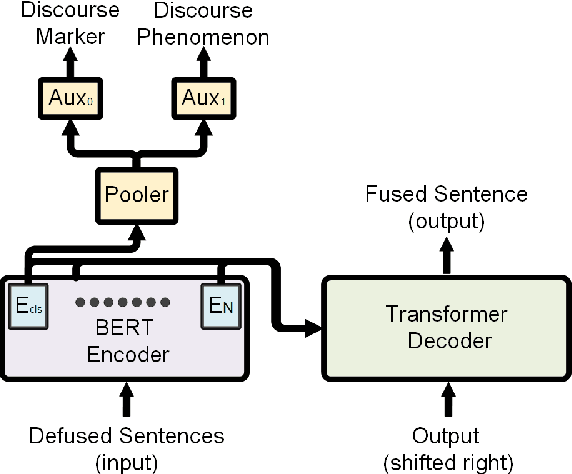
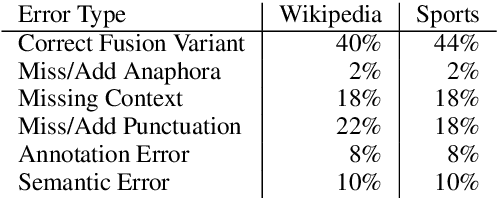
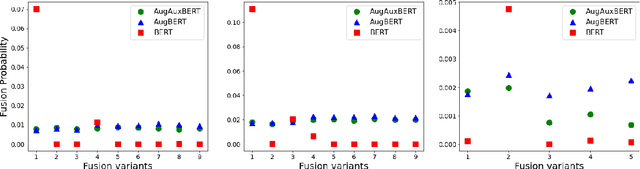
Sentence fusion is the task of joining related sentences into coherent text. Current training and evaluation schemes for this task are based on single reference ground-truths and do not account for valid fusion variants. We show that this hinders models from robustly capturing the semantic relationship between input sentences. To alleviate this, we present an approach in which ground-truth solutions are automatically expanded into multiple references via curated equivalence classes of connective phrases. We apply this method to a large-scale dataset and use the augmented dataset for both model training and evaluation. To improve the learning of semantic representation using multiple references, we enrich the model with auxiliary discourse classification tasks under a multi-tasking framework. Our experiments highlight the improvements of our approach over state-of-the-art models.