 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking to Recall: How Reasoning Unlocks Parametric Knowledge in LLMs
Mar 10, 2026While reasoning in LLMs plays a natural role in math, code generation, and multi-hop factual questions, its effect on simple, single-hop factual questions remains unclear. Such questions do not require step-by-step logical decomposition, making the utility of reasoning highly counterintuitive. Nevertheless, we find that enabling reasoning substantially expands the capability boundary of the model's parametric knowledge recall, unlocking correct answers that are otherwise effectively unreachable. Why does reasoning aid parametric knowledge recall when there are no complex reasoning steps to be done? To answer this, we design a series of hypothesis-driven controlled experiments, and identify two key driving mechanisms: (1) a computational buffer effect, where the model uses the generated reasoning tokens to perform latent computation independent of their semantic content; and (2) factual priming, where generating topically related facts acts as a semantic bridge that facilitates correct answer retrieval. Importantly, this latter generative self-retrieval mechanism carries inherent risks: we demonstrate that hallucinating intermediate facts during reasoning increases the likelihood of hallucinations in the final answer. Finally, we show that our insights can be harnessed to directly improve model accuracy by prioritizing reasoning trajectories that contain hallucination-free factual statements.
Empty Shelves or Lost Keys? Recall Is the Bottleneck for Parametric Factuality
Feb 15, 2026Standard factuality evaluations of LLMs treat all errors alike, obscuring whether failures arise from missing knowledge (empty shelves) or from limited access to encoded facts (lost keys). We propose a behavioral framework that profiles factual knowledge at the level of facts rather than questions, characterizing each fact by whether it is encoded, and then by how accessible it is: cannot be recalled, can be directly recalled, or can only be recalled with inference-time computation (thinking). To support such profiling, we introduce WikiProfile, a new benchmark constructed via an automated pipeline with a prompted LLM grounded in web search. Across 4 million responses from 13 LLMs, we find that encoding is nearly saturated in frontier models on our benchmark, with GPT-5 and Gemini-3 encoding 95--98% of facts. However, recall remains a major bottleneck: many errors previously attributed to missing knowledge instead stem from failures to access it. These failures are systematic and disproportionately affect long-tail facts and reverse questions. Finally, we show that thinking improves recall and can recover a substantial fraction of failures, indicating that future gains may rely less on scaling and more on methods that improve how models utilize what they already encode.
Evaluating Alignment of Behavioral Dispositions in LLMs
Feb 11, 2026As LLMs integrate into our daily lives, understanding their behavior becomes essential. In this work, we focus on behavioral dispositions$-$the underlying tendencies that shape responses in social contexts$-$and introduce a framework to study how closely the dispositions expressed by LLMs align with those of humans. Our approach is grounded in established psychological questionnaires but adapts them for LLMs by transforming human self-report statements into Situational Judgment Tests (SJTs). These SJTs assess behavior by eliciting natural recommendations in realistic user-assistant scenarios. We generate 2,500 SJTs, each validated by three human annotators, and collect preferred actions from 10 annotators per SJT, from a large pool of 550 participants. In a comprehensive study involving 25 LLMs, we find that models often do not reflect the distribution of human preferences: (1) in scenarios with low human consensus, LLMs consistently exhibit overconfidence in a single response; (2) when human consensus is high, smaller models deviate significantly, and even some frontier models do not reflect the consensus in 15-20% of cases; (3) traits can exhibit cross-LLM patterns, e.g., LLMs may encourage emotion expression in contexts where human consensus favors composure. Lastly, mapping psychometric statements directly to behavioral scenarios presents a unique opportunity to evaluate the predictive validity of self-reports, revealing considerable gaps between LLMs' stated values and their revealed behavior.
Fine-Grained Detection of Context-Grounded Hallucinations Using LLMs
Sep 26, 2025Context-grounded hallucinations are cases where model outputs contain information not verifiable against the source text. We study the applicability of LLMs for localizing such hallucinations, as a more practical alternative to existing complex evaluation pipelines. In the absence of established benchmarks for meta-evaluation of hallucinations localization, we construct one tailored to LLMs, involving a challenging human annotation of over 1,000 examples. We complement the benchmark with an LLM-based evaluation protocol, verifying its quality in a human evaluation. Since existing representations of hallucinations limit the types of errors that can be expressed, we propose a new representation based on free-form textual descriptions, capturing the full range of possible errors. We conduct a comprehensive study, evaluating four large-scale LLMs, which highlights the benchmark's difficulty, as the best model achieves an F1 score of only 0.67. Through careful analysis, we offer insights into optimal prompting strategies for the task and identify the main factors that make it challenging for LLMs: (1) a tendency to incorrectly flag missing details as inconsistent, despite being instructed to check only facts in the output; and (2) difficulty with outputs containing factually correct information absent from the source - and thus not verifiable - due to alignment with the model's parametric knowledge.
Inside-Out: Hidden Factual Knowledge in LLMs
Mar 19, 2025This work presents a framework for assessing whether large language models (LLMs) encode more factual knowledge in their parameters than what they express in their outputs. While a few studies hint at this possibility, none has clearly defined or demonstrated this phenomenon. We first propose a formal definition of knowledge, quantifying it for a given question as the fraction of correct-incorrect answer pairs where the correct one is ranked higher. This gives rise to external and internal knowledge, depending on the information used to score individual answer candidates: either the model's observable token-level probabilities or its intermediate computations. Hidden knowledge arises when internal knowledge exceeds external knowledge. We then present a case study, applying this framework to three popular open-weights LLMs in a closed-book QA setup. Our results indicate that: (1) LLMs consistently encode more factual knowledge internally than what they express externally, with an average gap of 40%. (2) Surprisingly, some knowledge is so deeply hidden that a model can internally know an answer perfectly, yet fail to generate it even once, despite large-scale repeated sampling of 1,000 answers. This reveals fundamental limitations in the generation capabilities of LLMs, which (3) puts a practical constraint on scaling test-time compute via repeated answer sampling in closed-book QA: significant performance improvements remain inaccessible because some answers are practically never sampled, yet if they were, we would be guaranteed to rank them first.
Confidence Improves Self-Consistency in LLMs
Feb 10, 2025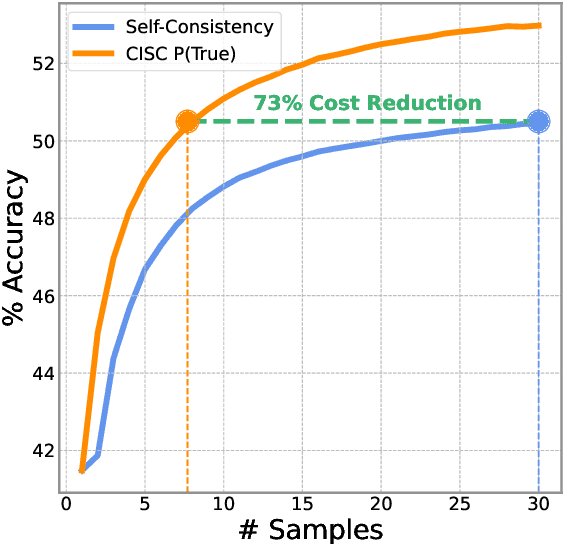
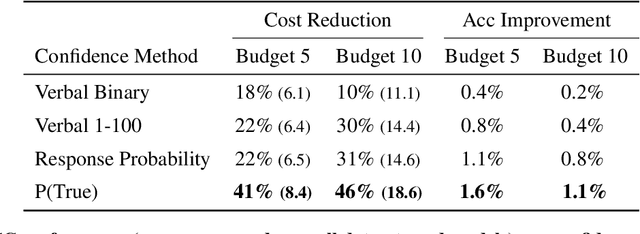

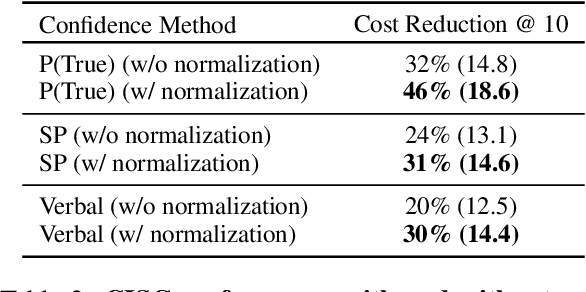
Self-consistency decoding enhances LLMs' performance on reasoning tasks by sampling diverse reasoning paths and selecting the most frequent answer. However, it is computationally expensive, as sampling many of these (lengthy) paths is required to increase the chances that the correct answer emerges as the most frequent one. To address this, we introduce Confidence-Informed Self-Consistency (CISC). CISC performs a weighted majority vote based on confidence scores obtained directly from the model. By prioritizing high-confidence paths, it can identify the correct answer with a significantly smaller sample size. When tested on nine models and four datasets, CISC outperforms self-consistency in nearly all configurations, reducing the required number of reasoning paths by over 40% on average. In addition, we introduce the notion of within-question confidence evaluation, after showing that standard evaluation methods are poor predictors of success in distinguishing correct and incorrect answers to the same question. In fact, the most calibrated confidence method proved to be the least effective for CISC. Lastly, beyond these practical implications, our results and analyses show that LLMs can effectively judge the correctness of their own outputs, contributing to the ongoing debate on this topic.
LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations
Oct 03, 2024
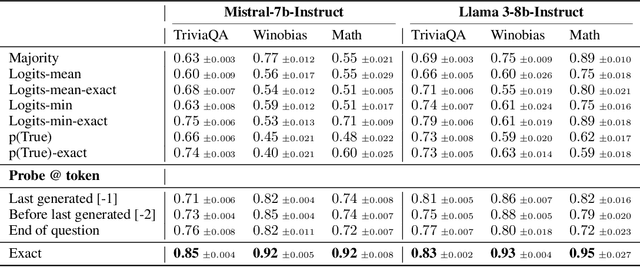
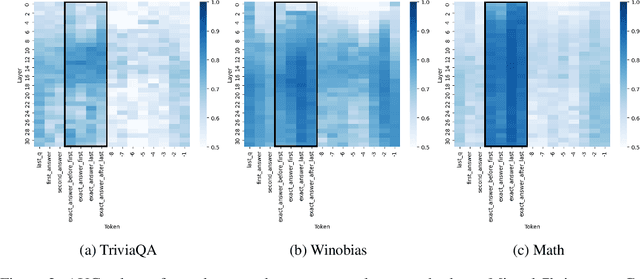
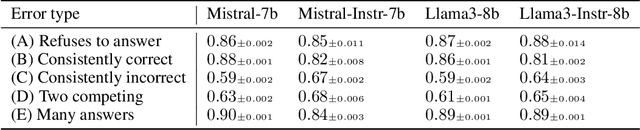
Large language models (LLMs) often produce errors, including factual inaccuracies, biases, and reasoning failures, collectively referred to as "hallucinations". Recent studies have demonstrated that LLMs' internal states encode information regarding the truthfulness of their outputs, and that this information can be utilized to detect errors. In this work, we show that the internal representations of LLMs encode much more information about truthfulness than previously recognized. We first discover that the truthfulness information is concentrated in specific tokens, and leveraging this property significantly enhances error detection performance. Yet, we show that such error detectors fail to generalize across datasets, implying that -- contrary to prior claims -- truthfulness encoding is not universal but rather multifaceted. Next, we show that internal representations can also be used for predicting the types of errors the model is likely to make, facilitating the development of tailored mitigation strategies. Lastly, we reveal a discrepancy between LLMs' internal encoding and external behavior: they may encode the correct answer, yet consistently generate an incorrect one. Taken together, these insights deepen our understanding of LLM errors from the model's internal perspective, which can guide future research on enhancing error analysis and mitigation.
NL-Eye: Abductive NLI for Images
Oct 03, 2024
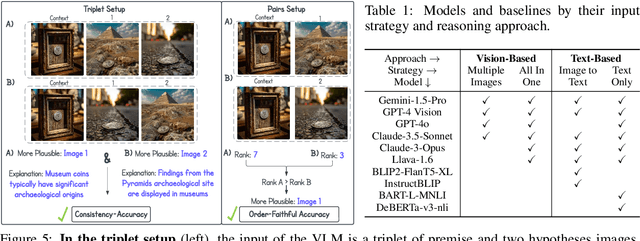

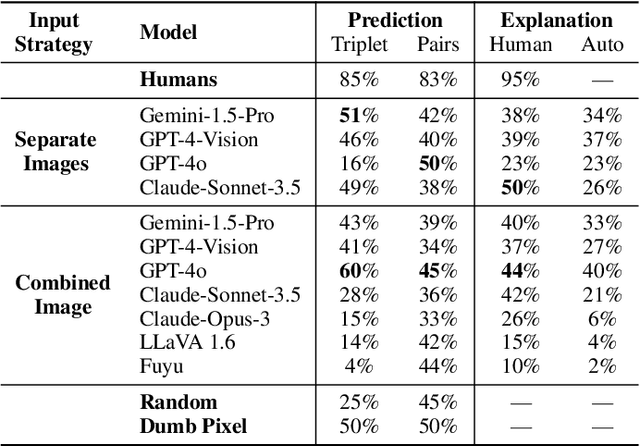
Will a Visual Language Model (VLM)-based bot warn us about slipping if it detects a wet floor? Recent VLMs have demonstrated impressive capabilities, yet their ability to infer outcomes and causes remains underexplored. To address this, we introduce NL-Eye, a benchmark designed to assess VLMs' visual abductive reasoning skills. NL-Eye adapts the abductive Natural Language Inference (NLI) task to the visual domain, requiring models to evaluate the plausibility of hypothesis images based on a premise image and explain their decisions. NL-Eye consists of 350 carefully curated triplet examples (1,050 images) spanning diverse reasoning categories: physical, functional, logical, emotional, cultural, and social. The data curation process involved two steps - writing textual descriptions and generating images using text-to-image models, both requiring substantial human involvement to ensure high-quality and challenging scenes. Our experiments show that VLMs struggle significantly on NL-Eye, often performing at random baseline levels, while humans excel in both plausibility prediction and explanation quality. This demonstrates a deficiency in the abductive reasoning capabilities of modern VLMs. NL-Eye represents a crucial step toward developing VLMs capable of robust multimodal reasoning for real-world applications, including accident-prevention bots and generated video verification.
Can LLMs Learn Macroeconomic Narratives from Social Media?
Jun 17, 2024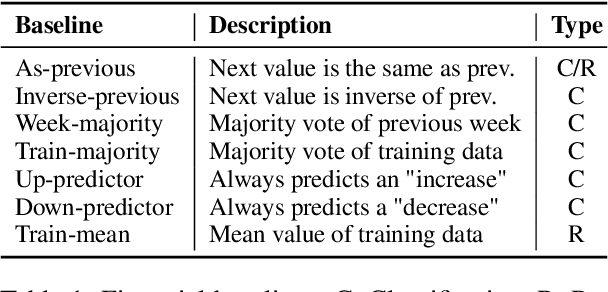


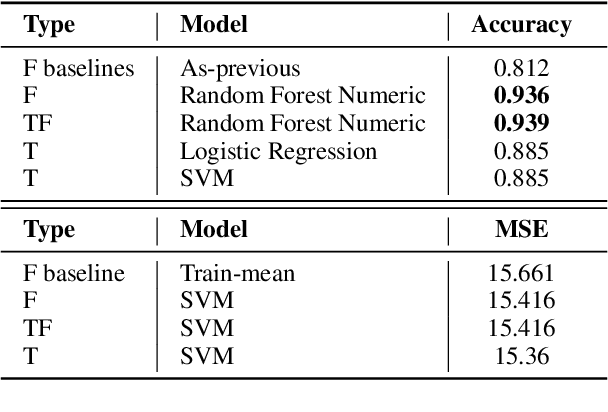
This study empirically tests the $\textit{Narrative Economics}$ hypothesis, which posits that narratives (ideas that are spread virally and affect public beliefs) can influence economic fluctuations. We introduce two curated datasets containing posts from X (formerly Twitter) which capture economy-related narratives (Data will be shared upon paper acceptance). Employing Natural Language Processing (NLP) methods, we extract and summarize narratives from the tweets. We test their predictive power for $\textit{macroeconomic}$ forecasting by incorporating the tweets' or the extracted narratives' representations in downstream financial prediction tasks. Our work highlights the challenges in improving macroeconomic models with narrative data, paving the way for the research community to realistically address this important challenge. From a scientific perspective, our investigation offers valuable insights and NLP tools for narrative extraction and summarization using Large Language Models (LLMs), contributing to future research on the role of narratives in economics.
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
May 09, 2024

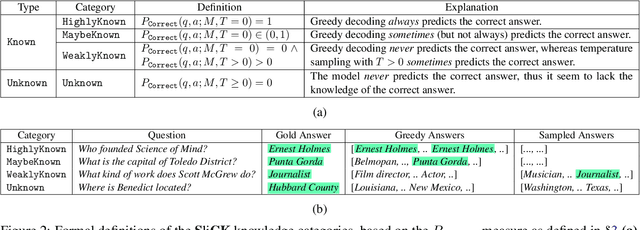
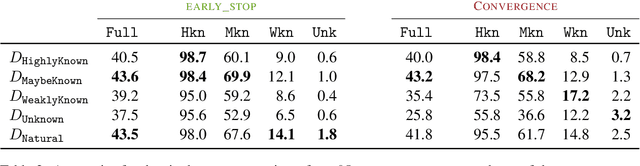
When large language models are aligned via supervised fine-tuning, they may encounter new factual information that was not acquired through pre-training. It is often conjectured that this can teach the model the behavior of hallucinating factually incorrect responses, as the model is trained to generate facts that are not grounded in its pre-existing knowledge. In this work, we study the impact of such exposure to new knowledge on the capability of the fine-tuned model to utilize its pre-existing knowledge. To this end, we design a controlled setup, focused on closed-book QA, where we vary the proportion of the fine-tuning examples that introduce new knowledge. We demonstrate that large language models struggle to acquire new factual knowledge through fine-tuning, as fine-tuning examples that introduce new knowledge are learned significantly slower than those consistent with the model's knowledge. However, we also find that as the examples with new knowledge are eventually learned, they linearly increase the model's tendency to hallucinate. Taken together, our results highlight the risk in introducing new factual knowledge through fine-tuning, and support the view that large language models mostly acquire factual knowledge through pre-training, whereas fine-tuning teaches them to use it more efficiently.