 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden Failures in Robustness: Why Supervised Uncertainty Quantification Needs Better Evaluation
Apr 13, 2026Recent work has shown that the hidden states of large language models contain signals useful for uncertainty estimation and hallucination detection, motivating a growing interest in efficient probe-based approaches. Yet it remains unclear how robust existing methods are, and which probe designs provide uncertainty estimates that are reliable under distribution shift. We present a systematic study of supervised uncertainty probes across models, tasks, and OOD settings, training over 2,000 probes while varying the representation layer, feature type, and token aggregation strategy. Our evaluation highlights poor robustness in current methods, particularly in the case of long-form generations. We also find that probe robustness is driven less by architecture and more by the probe inputs. Middle-layer representations generalise more reliably than final-layer hidden states, and aggregating across response tokens is consistently more robust than relying on single-token features. These differences are often largely invisible in-distribution but become more important under distribution shift. Informed by our evaluation, we explore a simple hybrid back-off strategy for improving robustness, arguing that better evaluation is a prerequisite for building more robust probes.
Large Language Models Generate Harmful Content Using a Distinct, Unified Mechanism
Apr 10, 2026Large language models (LLMs) undergo alignment training to avoid harmful behaviors, yet the resulting safeguards remain brittle: jailbreaks routinely bypass them, and fine-tuning on narrow domains can induce ``emergent misalignment'' that generalizes broadly. Whether this brittleness reflects a fundamental lack of coherent internal organization for harmfulness remains unclear. Here we use targeted weight pruning as a causal intervention to probe the internal organization of harmfulness in LLMs. We find that harmful content generation depends on a compact set of weights that are general across harm types and distinct from benign capabilities. Aligned models exhibit a greater compression of harm generation weights than unaligned counterparts, indicating that alignment reshapes harmful representations internally--despite the brittleness of safety guardrails at the surface level. This compression explains emergent misalignment: if weights of harmful capabilities are compressed, fine-tuning that engages these weights in one domain can trigger broad misalignment. Consistent with this, pruning harm generation weights in a narrow domain substantially reduces emergent misalignment. Notably, LLMs harmful generation capability is dissociated from how they recognize and explain such content. Together, these results reveal a coherent internal structure for harmfulness in LLMs that may serve as a foundation for more principled approaches to safety.
Agents of Chaos
Feb 23, 2026We report an exploratory red-teaming study of autonomous language-model-powered agents deployed in a live laboratory environment with persistent memory, email accounts, Discord access, file systems, and shell execution. Over a two-week period, twenty AI researchers interacted with the agents under benign and adversarial conditions. Focusing on failures emerging from the integration of language models with autonomy, tool use, and multi-party communication, we document eleven representative case studies. Observed behaviors include unauthorized compliance with non-owners, disclosure of sensitive information, execution of destructive system-level actions, denial-of-service conditions, uncontrolled resource consumption, identity spoofing vulnerabilities, cross-agent propagation of unsafe practices, and partial system takeover. In several cases, agents reported task completion while the underlying system state contradicted those reports. We also report on some of the failed attempts. Our findings establish the existence of security-, privacy-, and governance-relevant vulnerabilities in realistic deployment settings. These behaviors raise unresolved questions regarding accountability, delegated authority, and responsibility for downstream harms, and warrant urgent attention from legal scholars, policymakers, and researchers across disciplines. This report serves as an initial empirical contribution to that broader conversation.
MIB: A Mechanistic Interpretability Benchmark
Apr 17, 2025



How can we know whether new mechanistic interpretability methods achieve real improvements? In pursuit of meaningful and lasting evaluation standards, we propose MIB, a benchmark with two tracks spanning four tasks and five models. MIB favors methods that precisely and concisely recover relevant causal pathways or specific causal variables in neural language models. The circuit localization track compares methods that locate the model components - and connections between them - most important for performing a task (e.g., attribution patching or information flow routes). The causal variable localization track compares methods that featurize a hidden vector, e.g., sparse autoencoders (SAEs) or distributed alignment search (DAS), and locate model features for a causal variable relevant to the task. Using MIB, we find that attribution and mask optimization methods perform best on circuit localization. For causal variable localization, we find that the supervised DAS method performs best, while SAE features are not better than neurons, i.e., standard dimensions of hidden vectors. These findings illustrate that MIB enables meaningful comparisons of methods, and increases our confidence that there has been real progress in the field.
Inside-Out: Hidden Factual Knowledge in LLMs
Mar 19, 2025This work presents a framework for assessing whether large language models (LLMs) encode more factual knowledge in their parameters than what they express in their outputs. While a few studies hint at this possibility, none has clearly defined or demonstrated this phenomenon. We first propose a formal definition of knowledge, quantifying it for a given question as the fraction of correct-incorrect answer pairs where the correct one is ranked higher. This gives rise to external and internal knowledge, depending on the information used to score individual answer candidates: either the model's observable token-level probabilities or its intermediate computations. Hidden knowledge arises when internal knowledge exceeds external knowledge. We then present a case study, applying this framework to three popular open-weights LLMs in a closed-book QA setup. Our results indicate that: (1) LLMs consistently encode more factual knowledge internally than what they express externally, with an average gap of 40%. (2) Surprisingly, some knowledge is so deeply hidden that a model can internally know an answer perfectly, yet fail to generate it even once, despite large-scale repeated sampling of 1,000 answers. This reveals fundamental limitations in the generation capabilities of LLMs, which (3) puts a practical constraint on scaling test-time compute via repeated answer sampling in closed-book QA: significant performance improvements remain inaccessible because some answers are practically never sampled, yet if they were, we would be guaranteed to rank them first.
Position-aware Automatic Circuit Discovery
Feb 07, 2025A widely used strategy to discover and understand language model mechanisms is circuit analysis. A circuit is a minimal subgraph of a model's computation graph that executes a specific task. We identify a gap in existing circuit discovery methods: they assume circuits are position-invariant, treating model components as equally relevant across input positions. This limits their ability to capture cross-positional interactions or mechanisms that vary across positions. To address this gap, we propose two improvements to incorporate positionality into circuits, even on tasks containing variable-length examples. First, we extend edge attribution patching, a gradient-based method for circuit discovery, to differentiate between token positions. Second, we introduce the concept of a dataset schema, which defines token spans with similar semantics across examples, enabling position-aware circuit discovery in datasets with variable length examples. We additionally develop an automated pipeline for schema generation and application using large language models. Our approach enables fully automated discovery of position-sensitive circuits, yielding better trade-offs between circuit size and faithfulness compared to prior work.
Padding Tone: A Mechanistic Analysis of Padding Tokens in T2I Models
Jan 12, 2025



Text-to-image (T2I) diffusion models rely on encoded prompts to guide the image generation process. Typically, these prompts are extended to a fixed length by adding padding tokens before text encoding. Despite being a default practice, the influence of padding tokens on the image generation process has not been investigated. In this work, we conduct the first in-depth analysis of the role padding tokens play in T2I models. We develop two causal techniques to analyze how information is encoded in the representation of tokens across different components of the T2I pipeline. Using these techniques, we investigate when and how padding tokens impact the image generation process. Our findings reveal three distinct scenarios: padding tokens may affect the model's output during text encoding, during the diffusion process, or be effectively ignored. Moreover, we identify key relationships between these scenarios and the model's architecture (cross or self-attention) and its training process (frozen or trained text encoder). These insights contribute to a deeper understanding of the mechanisms of padding tokens, potentially informing future model design and training practices in T2I systems.
LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations
Oct 03, 2024
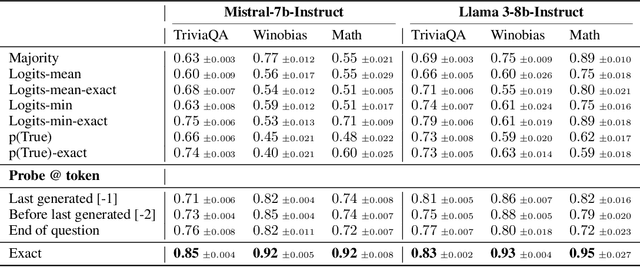
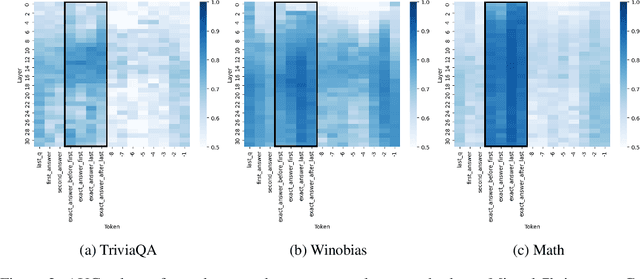
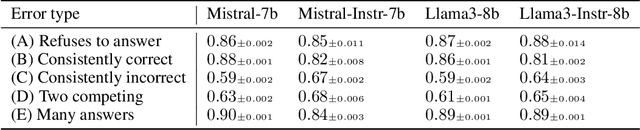
Large language models (LLMs) often produce errors, including factual inaccuracies, biases, and reasoning failures, collectively referred to as "hallucinations". Recent studies have demonstrated that LLMs' internal states encode information regarding the truthfulness of their outputs, and that this information can be utilized to detect errors. In this work, we show that the internal representations of LLMs encode much more information about truthfulness than previously recognized. We first discover that the truthfulness information is concentrated in specific tokens, and leveraging this property significantly enhances error detection performance. Yet, we show that such error detectors fail to generalize across datasets, implying that -- contrary to prior claims -- truthfulness encoding is not universal but rather multifaceted. Next, we show that internal representations can also be used for predicting the types of errors the model is likely to make, facilitating the development of tailored mitigation strategies. Lastly, we reveal a discrepancy between LLMs' internal encoding and external behavior: they may encode the correct answer, yet consistently generate an incorrect one. Taken together, these insights deepen our understanding of LLM errors from the model's internal perspective, which can guide future research on enhancing error analysis and mitigation.
Diffusion Lens: Interpreting Text Encoders in Text-to-Image Pipelines
Mar 09, 2024
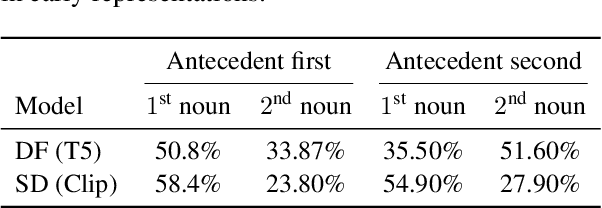

Text-to-image diffusion models (T2I) use a latent representation of a text prompt to guide the image generation process. However, the process by which the encoder produces the text representation is unknown. We propose the Diffusion Lens, a method for analyzing the text encoder of T2I models by generating images from its intermediate representations. Using the Diffusion Lens, we perform an extensive analysis of two recent T2I models. Exploring compound prompts, we find that complex scenes describing multiple objects are composed progressively and more slowly compared to simple scenes; Exploring knowledge retrieval, we find that representation of uncommon concepts requires further computation compared to common concepts, and that knowledge retrieval is gradual across layers. Overall, our findings provide valuable insights into the text encoder component in T2I pipelines.
Unified Concept Editing in Diffusion Models
Aug 25, 2023



Text-to-image models suffer from various safety issues that may limit their suitability for deployment. Previous methods have separately addressed individual issues of bias, copyright, and offensive content in text-to-image models. However, in the real world, all of these issues appear simultaneously in the same model. We present a method that tackles all issues with a single approach. Our method, Unified Concept Editing (UCE), edits the model without training using a closed-form solution, and scales seamlessly to concurrent edits on text-conditional diffusion models. We demonstrate scalable simultaneous debiasing, style erasure, and content moderation by editing text-to-image projections, and we present extensive experiments demonstrating improved efficacy and scalability over prior work. Our code is available at https://unified.baulab.info