 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpanning the Visual Analogy Space with a Weight Basis of LoRAs
Feb 17, 2026Visual analogy learning enables image manipulation through demonstration rather than textual description, allowing users to specify complex transformations difficult to articulate in words. Given a triplet $\{\mathbf{a}$, $\mathbf{a}'$, $\mathbf{b}\}$, the goal is to generate $\mathbf{b}'$ such that $\mathbf{a} : \mathbf{a}' :: \mathbf{b} : \mathbf{b}'$. Recent methods adapt text-to-image models to this task using a single Low-Rank Adaptation (LoRA) module, but they face a fundamental limitation: attempting to capture the diverse space of visual transformations within a fixed adaptation module constrains generalization capabilities. Inspired by recent work showing that LoRAs in constrained domains span meaningful, interpolatable semantic spaces, we propose LoRWeB, a novel approach that specializes the model for each analogy task at inference time through dynamic composition of learned transformation primitives, informally, choosing a point in a "space of LoRAs". We introduce two key components: (1) a learnable basis of LoRA modules, to span the space of different visual transformations, and (2) a lightweight encoder that dynamically selects and weighs these basis LoRAs based on the input analogy pair. Comprehensive evaluations demonstrate our approach achieves state-of-the-art performance and significantly improves generalization to unseen visual transformations. Our findings suggest that LoRA basis decompositions are a promising direction for flexible visual manipulation. Code and data are in https://research.nvidia.com/labs/par/lorweb
Policy Optimized Text-to-Image Pipeline Design
May 27, 2025Text-to-image generation has evolved beyond single monolithic models to complex multi-component pipelines. These combine fine-tuned generators, adapters, upscaling blocks and even editing steps, leading to significant improvements in image quality. However, their effective design requires substantial expertise. Recent approaches have shown promise in automating this process through large language models (LLMs), but they suffer from two critical limitations: extensive computational requirements from generating images with hundreds of predefined pipelines, and poor generalization beyond memorized training examples. We introduce a novel reinforcement learning-based framework that addresses these inefficiencies. Our approach first trains an ensemble of reward models capable of predicting image quality scores directly from prompt-workflow combinations, eliminating the need for costly image generation during training. We then implement a two-phase training strategy: initial workflow vocabulary training followed by GRPO-based optimization that guides the model toward higher-performing regions of the workflow space. Additionally, we incorporate a classifier-free guidance based enhancement technique that extrapolates along the path between the initial and GRPO-tuned models, further improving output quality. We validate our approach through a set of comparisons, showing that it can successfully create new flows with greater diversity and lead to superior image quality compared to existing baselines.
IP-Composer: Semantic Composition of Visual Concepts
Feb 19, 2025
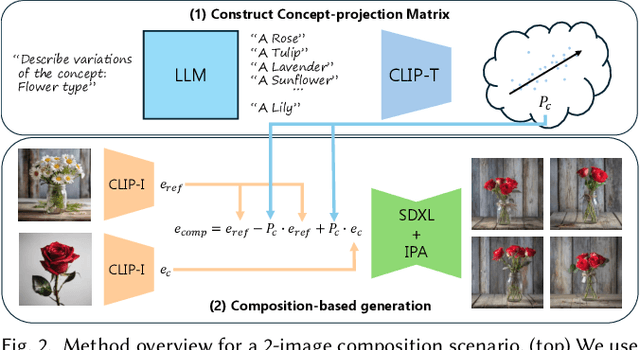


Content creators often draw inspiration from multiple visual sources, combining distinct elements to craft new compositions. Modern computational approaches now aim to emulate this fundamental creative process. Although recent diffusion models excel at text-guided compositional synthesis, text as a medium often lacks precise control over visual details. Image-based composition approaches can capture more nuanced features, but existing methods are typically limited in the range of concepts they can capture, and require expensive training procedures or specialized data. We present IP-Composer, a novel training-free approach for compositional image generation that leverages multiple image references simultaneously, while using natural language to describe the concept to be extracted from each image. Our method builds on IP-Adapter, which synthesizes novel images conditioned on an input image's CLIP embedding. We extend this approach to multiple visual inputs by crafting composite embeddings, stitched from the projections of multiple input images onto concept-specific CLIP-subspaces identified through text. Through comprehensive evaluation, we show that our approach enables more precise control over a larger range of visual concept compositions.
ImageRAG: Dynamic Image Retrieval for Reference-Guided Image Generation
Feb 13, 2025


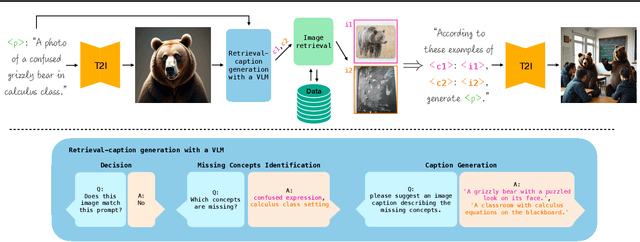
Diffusion models enable high-quality and diverse visual content synthesis. However, they struggle to generate rare or unseen concepts. To address this challenge, we explore the usage of Retrieval-Augmented Generation (RAG) with image generation models. We propose ImageRAG, a method that dynamically retrieves relevant images based on a given text prompt, and uses them as context to guide the generation process. Prior approaches that used retrieved images to improve generation, trained models specifically for retrieval-based generation. In contrast, ImageRAG leverages the capabilities of existing image conditioning models, and does not require RAG-specific training. Our approach is highly adaptable and can be applied across different model types, showing significant improvement in generating rare and fine-grained concepts using different base models. Our project page is available at: https://rotem-shalev.github.io/ImageRAG
Padding Tone: A Mechanistic Analysis of Padding Tokens in T2I Models
Jan 12, 2025



Text-to-image (T2I) diffusion models rely on encoded prompts to guide the image generation process. Typically, these prompts are extended to a fixed length by adding padding tokens before text encoding. Despite being a default practice, the influence of padding tokens on the image generation process has not been investigated. In this work, we conduct the first in-depth analysis of the role padding tokens play in T2I models. We develop two causal techniques to analyze how information is encoded in the representation of tokens across different components of the T2I pipeline. Using these techniques, we investigate when and how padding tokens impact the image generation process. Our findings reveal three distinct scenarios: padding tokens may affect the model's output during text encoding, during the diffusion process, or be effectively ignored. Moreover, we identify key relationships between these scenarios and the model's architecture (cross or self-attention) and its training process (frozen or trained text encoder). These insights contribute to a deeper understanding of the mechanisms of padding tokens, potentially informing future model design and training practices in T2I systems.
Nested Attention: Semantic-aware Attention Values for Concept Personalization
Jan 02, 2025Personalizing text-to-image models to generate images of specific subjects across diverse scenes and styles is a rapidly advancing field. Current approaches often face challenges in maintaining a balance between identity preservation and alignment with the input text prompt. Some methods rely on a single textual token to represent a subject, which limits expressiveness, while others employ richer representations but disrupt the model's prior, diminishing prompt alignment. In this work, we introduce Nested Attention, a novel mechanism that injects a rich and expressive image representation into the model's existing cross-attention layers. Our key idea is to generate query-dependent subject values, derived from nested attention layers that learn to select relevant subject features for each region in the generated image. We integrate these nested layers into an encoder-based personalization method, and show that they enable high identity preservation while adhering to input text prompts. Our approach is general and can be trained on various domains. Additionally, its prior preservation allows us to combine multiple personalized subjects from different domains in a single image.
Multi-Shot Character Consistency for Text-to-Video Generation
Dec 10, 2024

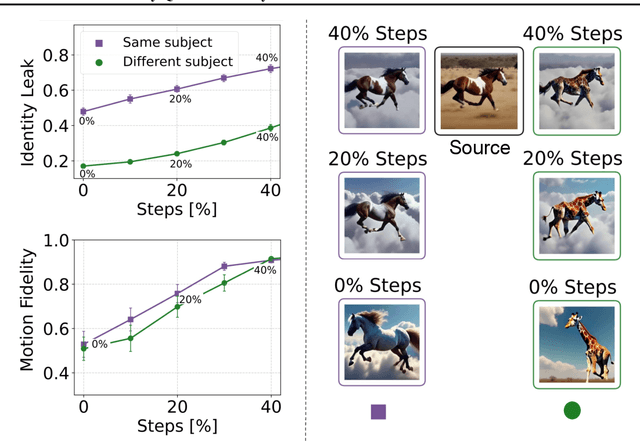

Text-to-video models have made significant strides in generating short video clips from textual descriptions. Yet, a significant challenge remains: generating several video shots of the same characters, preserving their identity without hurting video quality, dynamics, and responsiveness to text prompts. We present Video Storyboarding, a training-free method to enable pretrained text-to-video models to generate multiple shots with consistent characters, by sharing features between them. Our key insight is that self-attention query features (Q) encode both motion and identity. This creates a hard-to-avoid trade-off between preserving character identity and making videos dynamic, when features are shared. To address this issue, we introduce a novel query injection strategy that balances identity preservation and natural motion retention. This approach improves upon naive consistency techniques applied to videos, which often struggle to maintain this delicate equilibrium. Our experiments demonstrate significant improvements in character consistency across scenes while maintaining high-quality motion and text alignment. These results offer insights into critical stages of video generation and the interplay of structure and motion in video diffusion models.
Add-it: Training-Free Object Insertion in Images With Pretrained Diffusion Models
Nov 12, 2024
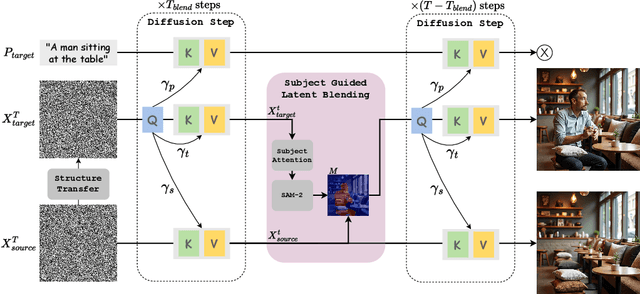
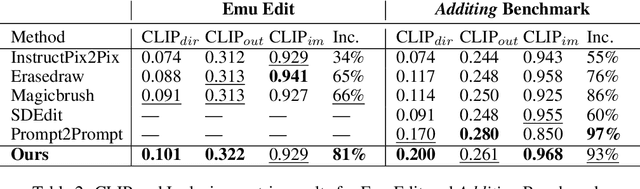
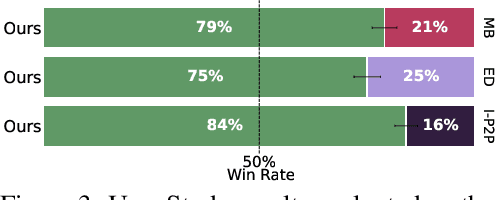
Adding Object into images based on text instructions is a challenging task in semantic image editing, requiring a balance between preserving the original scene and seamlessly integrating the new object in a fitting location. Despite extensive efforts, existing models often struggle with this balance, particularly with finding a natural location for adding an object in complex scenes. We introduce Add-it, a training-free approach that extends diffusion models' attention mechanisms to incorporate information from three key sources: the scene image, the text prompt, and the generated image itself. Our weighted extended-attention mechanism maintains structural consistency and fine details while ensuring natural object placement. Without task-specific fine-tuning, Add-it achieves state-of-the-art results on both real and generated image insertion benchmarks, including our newly constructed "Additing Affordance Benchmark" for evaluating object placement plausibility, outperforming supervised methods. Human evaluations show that Add-it is preferred in over 80% of cases, and it also demonstrates improvements in various automated metrics.
ComfyGen: Prompt-Adaptive Workflows for Text-to-Image Generation
Oct 02, 2024



The practical use of text-to-image generation has evolved from simple, monolithic models to complex workflows that combine multiple specialized components. While workflow-based approaches can lead to improved image quality, crafting effective workflows requires significant expertise, owing to the large number of available components, their complex inter-dependence, and their dependence on the generation prompt. Here, we introduce the novel task of prompt-adaptive workflow generation, where the goal is to automatically tailor a workflow to each user prompt. We propose two LLM-based approaches to tackle this task: a tuning-based method that learns from user-preference data, and a training-free method that uses the LLM to select existing flows. Both approaches lead to improved image quality when compared to monolithic models or generic, prompt-independent workflows. Our work shows that prompt-dependent flow prediction offers a new pathway to improving text-to-image generation quality, complementing existing research directions in the field.
TurboEdit: Text-Based Image Editing Using Few-Step Diffusion Models
Aug 01, 2024Diffusion models have opened the path to a wide range of text-based image editing frameworks. However, these typically build on the multi-step nature of the diffusion backwards process, and adapting them to distilled, fast-sampling methods has proven surprisingly challenging. Here, we focus on a popular line of text-based editing frameworks - the ``edit-friendly'' DDPM-noise inversion approach. We analyze its application to fast sampling methods and categorize its failures into two classes: the appearance of visual artifacts, and insufficient editing strength. We trace the artifacts to mismatched noise statistics between inverted noises and the expected noise schedule, and suggest a shifted noise schedule which corrects for this offset. To increase editing strength, we propose a pseudo-guidance approach that efficiently increases the magnitude of edits without introducing new artifacts. All in all, our method enables text-based image editing with as few as three diffusion steps, while providing novel insights into the mechanisms behind popular text-based editing approaches.