 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Competition to Collaboration: Designing Sustainable Mechanisms Between LLMs and Online Forums
Feb 04, 2026While Generative AI (GenAI) systems draw users away from (Q&A) forums, they also depend on the very data those forums produce to improve their performance. Addressing this paradox, we propose a framework of sequential interaction, in which a GenAI system proposes questions to a forum that can publish some of them. Our framework captures several intricacies of such a collaboration, including non-monetary exchanges, asymmetric information, and incentive misalignment. We bring the framework to life through comprehensive, data-driven simulations using real Stack Exchange data and commonly used LLMs. We demonstrate the incentive misalignment empirically, yet show that players can achieve roughly half of the utility in an ideal full-information scenario. Our results highlight the potential for sustainable collaboration that preserves effective knowledge sharing between AI systems and human knowledge platforms.
Lost in Space? Vision-Language Models Struggle with Relative Camera Pose Estimation
Jan 29, 2026Vision-Language Models (VLMs) perform well in 2D perception and semantic reasoning compared to their limited understanding of 3D spatial structure. We investigate this gap using relative camera pose estimation (RCPE), a fundamental vision task that requires inferring relative camera translation and rotation from a pair of images. We introduce VRRPI-Bench, a benchmark derived from unlabeled egocentric videos with verbalized annotations of relative camera motion, reflecting realistic scenarios with simultaneous translation and rotation around a shared object. We further propose VRRPI-Diag, a diagnostic benchmark that isolates individual motion degrees of freedom. Despite the simplicity of RCPE, most VLMs fail to generalize beyond shallow 2D heuristics, particularly for depth changes and roll transformations along the optical axis. Even state-of-the-art models such as GPT-5 ($0.64$) fall short of classic geometric baselines ($0.97$) and human performance ($0.92$). Moreover, VLMs exhibit difficulty in multi-image reasoning, with inconsistent performance (best $59.7\%$) when integrating spatial cues across frames. Our findings reveal limitations in grounding VLMs in 3D and multi-view spatial reasoning.
Iterative Multilingual Spectral Attribute Erasure
Jun 12, 2025Multilingual representations embed words with similar meanings to share a common semantic space across languages, creating opportunities to transfer debiasing effects between languages. However, existing methods for debiasing are unable to exploit this opportunity because they operate on individual languages. We present Iterative Multilingual Spectral Attribute Erasure (IMSAE), which identifies and mitigates joint bias subspaces across multiple languages through iterative SVD-based truncation. Evaluating IMSAE across eight languages and five demographic dimensions, we demonstrate its effectiveness in both standard and zero-shot settings, where target language data is unavailable, but linguistically similar languages can be used for debiasing. Our comprehensive experiments across diverse language models (BERT, LLaMA, Mistral) show that IMSAE outperforms traditional monolingual and cross-lingual approaches while maintaining model utility.
Towards Large Language Models with Self-Consistent Natural Language Explanations
Jun 09, 2025Large language models (LLMs) seem to offer an easy path to interpretability: just ask them to explain their decisions. Yet, studies show that these post-hoc explanations often misrepresent the true decision process, as revealed by mismatches in feature importance. Despite growing evidence of this inconsistency, no systematic solutions have emerged, partly due to the high cost of estimating feature importance, which limits evaluations to small datasets. To address this, we introduce the Post-hoc Self-Consistency Bank (PSCB) - a large-scale benchmark of decisions spanning diverse tasks and models, each paired with LLM-generated explanations and corresponding feature importance scores. Analysis of PSCB reveals that self-consistency scores barely differ between correct and incorrect predictions. We also show that the standard metric fails to meaningfully distinguish between explanations. To overcome this limitation, we propose an alternative metric that more effectively captures variation in explanation quality. We use it to fine-tune LLMs via Direct Preference Optimization (DPO), leading to significantly better alignment between explanations and decision-relevant features, even under domain shift. Our findings point to a scalable path toward more trustworthy, self-consistent LLMs.
Bootstrapping World Models from Dynamics Models in Multimodal Foundation Models
Jun 06, 2025To what extent do vision-and-language foundation models possess a realistic world model (observation $\times$ action $\rightarrow$ observation) and a dynamics model (observation $\times$ observation $\rightarrow$ action), when actions are expressed through language? While open-source foundation models struggle with both, we find that fine-tuning them to acquire a dynamics model through supervision is significantly easier than acquiring a world model. In turn, dynamics models can be used to bootstrap world models through two main strategies: 1) weakly supervised learning from synthetic data and 2) inference time verification. Firstly, the dynamics model can annotate actions for unlabelled pairs of video frame observations to expand the training data. We further propose a new objective, where image tokens in observation pairs are weighted by their importance, as predicted by a recognition model. Secondly, the dynamics models can assign rewards to multiple samples of the world model to score them, effectively guiding search at inference time. We evaluate the world models resulting from both strategies through the task of action-centric image editing on Aurora-Bench. Our best model achieves a performance competitive with state-of-the-art image editing models, improving on them by a margin of $15\%$ on real-world subsets according to GPT4o-as-judge, and achieving the best average human evaluation across all subsets of Aurora-Bench.
Knowing Before Saying: LLM Representations Encode Information About Chain-of-Thought Success Before Completion
May 30, 2025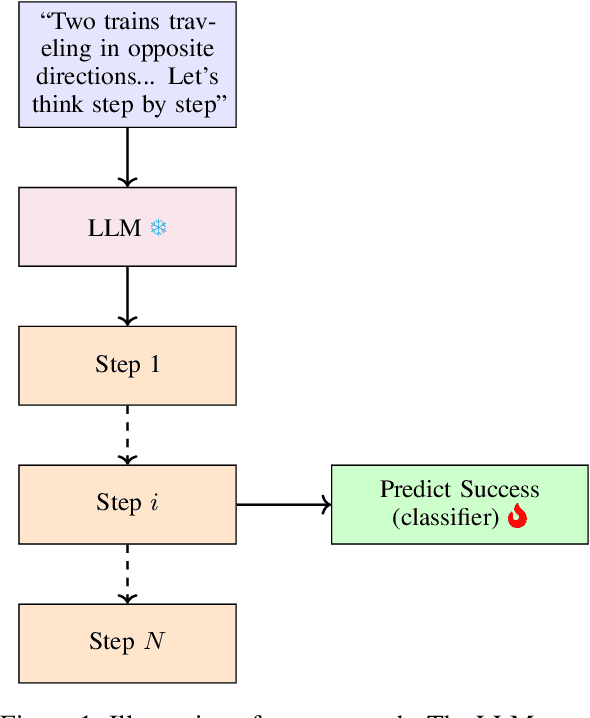
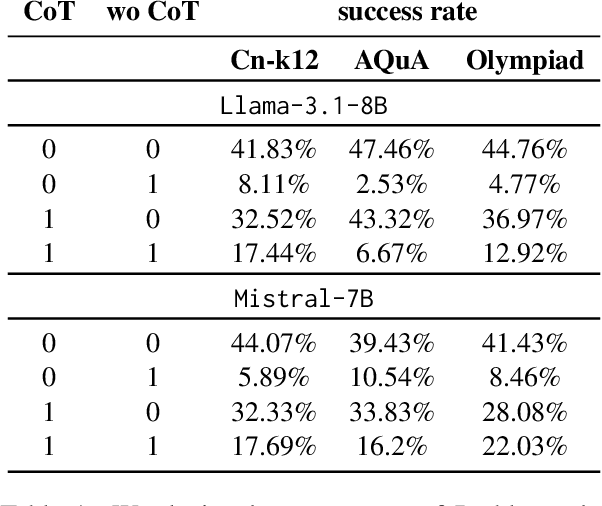
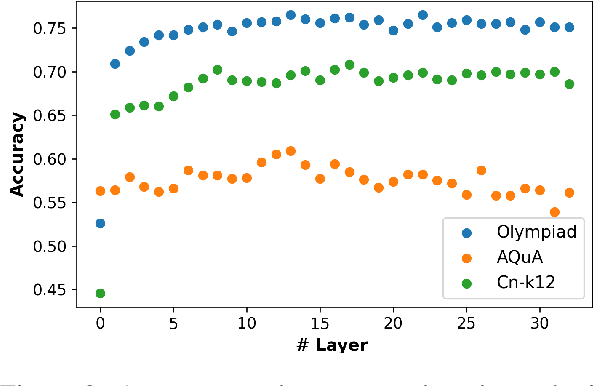
We investigate whether the success of a zero-shot Chain-of-Thought (CoT) process can be predicted before completion. We discover that a probing classifier, based on LLM representations, performs well \emph{even before a single token is generated}, suggesting that crucial information about the reasoning process is already present in the initial steps representations. In contrast, a strong BERT-based baseline, which relies solely on the generated tokens, performs worse, likely because it depends on shallow linguistic cues rather than deeper reasoning dynamics. Surprisingly, using later reasoning steps does not always improve classification. When additional context is unhelpful, earlier representations resemble later ones more, suggesting LLMs encode key information early. This implies reasoning can often stop early without loss. To test this, we conduct early stopping experiments, showing that truncating CoT reasoning still improves performance over not using CoT at all, though a gap remains compared to full reasoning. However, approaches like supervised learning or reinforcement learning designed to shorten CoT chains could leverage our classifier's guidance to identify when early stopping is effective. Our findings provide insights that may support such methods, helping to optimize CoT's efficiency while preserving its benefits.\footnote{Code and data is available at \href{https://github.com/anum94/CoTpred}{\texttt{github.com/anum94/CoTpred}}.
Policy Optimized Text-to-Image Pipeline Design
May 27, 2025Text-to-image generation has evolved beyond single monolithic models to complex multi-component pipelines. These combine fine-tuned generators, adapters, upscaling blocks and even editing steps, leading to significant improvements in image quality. However, their effective design requires substantial expertise. Recent approaches have shown promise in automating this process through large language models (LLMs), but they suffer from two critical limitations: extensive computational requirements from generating images with hundreds of predefined pipelines, and poor generalization beyond memorized training examples. We introduce a novel reinforcement learning-based framework that addresses these inefficiencies. Our approach first trains an ensemble of reward models capable of predicting image quality scores directly from prompt-workflow combinations, eliminating the need for costly image generation during training. We then implement a two-phase training strategy: initial workflow vocabulary training followed by GRPO-based optimization that guides the model toward higher-performing regions of the workflow space. Additionally, we incorporate a classifier-free guidance based enhancement technique that extrapolates along the path between the initial and GRPO-tuned models, further improving output quality. We validate our approach through a set of comparisons, showing that it can successfully create new flows with greater diversity and lead to superior image quality compared to existing baselines.
Learning on LLM Output Signatures for gray-box LLM Behavior Analysis
Mar 18, 2025Large Language Models (LLMs) have achieved widespread adoption, yet our understanding of their behavior remains limited, particularly in detecting data contamination and hallucinations. While recently proposed probing techniques provide insights through activation analysis, they require "white-box" access to model internals, often unavailable. Current "gray-box" approaches typically analyze only the probability of the actual tokens in the sequence with simple task-specific heuristics. Importantly, these methods overlook the rich information contained in the full token distribution at each processing step. To address these limitations, we propose that gray-box analysis should leverage the complete observable output of LLMs, consisting of both the previously used token probabilities as well as the complete token distribution sequences - a unified data type we term LOS (LLM Output Signature). To this end, we develop a transformer-based approach to process LOS that theoretically guarantees approximation of existing techniques while enabling more nuanced analysis. Our approach achieves superior performance on hallucination and data contamination detection in gray-box settings, significantly outperforming existing baselines. Furthermore, it demonstrates strong transfer capabilities across datasets and LLMs, suggesting that LOS captures fundamental patterns in LLM behavior. Our code is available at: https://github.com/BarSGuy/LLM-Output-Signatures-Network.
TSPRank: Bridging Pairwise and Listwise Methods with a Bilinear Travelling Salesman Model
Nov 18, 2024



Traditional Learning-To-Rank (LETOR) approaches, including pairwise methods like RankNet and LambdaMART, often fall short by solely focusing on pairwise comparisons, leading to sub-optimal global rankings. Conversely, deep learning based listwise methods, while aiming to optimise entire lists, require complex tuning and yield only marginal improvements over robust pairwise models. To overcome these limitations, we introduce Travelling Salesman Problem Rank (TSPRank), a hybrid pairwise-listwise ranking method. TSPRank reframes the ranking problem as a Travelling Salesman Problem (TSP), a well-known combinatorial optimisation challenge that has been extensively studied for its numerous solution algorithms and applications. This approach enables the modelling of pairwise relationships and leverages combinatorial optimisation to determine the listwise ranking. This approach can be directly integrated as an additional component into embeddings generated by existing backbone models to enhance ranking performance. Our extensive experiments across three backbone models on diverse tasks, including stock ranking, information retrieval, and historical events ordering, demonstrate that TSPRank significantly outperforms both pure pairwise and listwise methods. Our qualitative analysis reveals that TSPRank's main advantage over existing methods is its ability to harness global information better while ranking. TSPRank's robustness and superior performance across different domains highlight its potential as a versatile and effective LETOR solution. The code and preprocessed data are available at https://github.com/waylonli/TSPRank-KDD2025.
Layer by Layer: Uncovering Where Multi-Task Learning Happens in Instruction-Tuned Large Language Models
Oct 25, 2024Fine-tuning pre-trained large language models (LLMs) on a diverse array of tasks has become a common approach for building models that can solve various natural language processing (NLP) tasks. However, where and to what extent these models retain task-specific knowledge remains largely unexplored. This study investigates the task-specific information encoded in pre-trained LLMs and the effects of instruction tuning on their representations across a diverse set of over 60 NLP tasks. We use a set of matrix analysis tools to examine the differences between the way pre-trained and instruction-tuned LLMs store task-specific information. Our findings reveal that while some tasks are already encoded within the pre-trained LLMs, others greatly benefit from instruction tuning. Additionally, we pinpointed the layers in which the model transitions from high-level general representations to more task-oriented representations. This finding extends our understanding of the governing mechanisms of LLMs and facilitates future research in the fields of parameter-efficient transfer learning and multi-task learning.