 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well Do Models Follow Visual Instructions? VIBE: A Systematic Benchmark for Visual Instruction-Driven Image Editing
Feb 02, 2026Recent generative models have achieved remarkable progress in image editing. However, existing systems and benchmarks remain largely text-guided. In contrast, human communication is inherently multimodal, where visual instructions such as sketches efficiently convey spatial and structural intent. To address this gap, we introduce VIBE, the Visual Instruction Benchmark for Image Editing with a three-level interaction hierarchy that captures deictic grounding, morphological manipulation, and causal reasoning. Across these levels, we curate high-quality and diverse test cases that reflect progressively increasing complexity in visual instruction following. We further propose a robust LMM-as-a-judge evaluation framework with task-specific metrics to enable scalable and fine-grained assessment. Through a comprehensive evaluation of 17 representative open-source and proprietary image editing models, we find that proprietary models exhibit early-stage visual instruction-following capabilities and consistently outperform open-source models. However, performance degrades markedly with increasing task difficulty even for the strongest systems, highlighting promising directions for future research.
When Meanings Meet: Investigating the Emergence and Quality of Shared Concept Spaces during Multilingual Language Model Training
Jan 30, 2026Training Large Language Models (LLMs) with high multilingual coverage is becoming increasingly important -- especially when monolingual resources are scarce. Recent studies have found that LLMs process multilingual inputs in shared concept spaces, thought to support generalization and cross-lingual transfer. However, these prior studies often do not use causal methods, lack deeper error analysis or focus on the final model only, leaving open how these spaces emerge during training. We investigate the development of language-agnostic concept spaces during pretraining of EuroLLM through the causal interpretability method of activation patching. We isolate cross-lingual concept representations, then inject them into a translation prompt to investigate how consistently translations can be altered, independently of the language. We find that shared concept spaces emerge early} and continue to refine, but that alignment with them is language-dependent}. Furthermore, in contrast to prior work, our fine-grained manual analysis reveals that some apparent gains in translation quality reflect shifts in behavior -- like selecting senses for polysemous words or translating instead of copying cross-lingual homographs -- rather than improved translation ability. Our findings offer new insight into the training dynamics of cross-lingual alignment and the conditions under which causal interpretability methods offer meaningful insights in multilingual contexts.
Thinking in Frames: How Visual Context and Test-Time Scaling Empower Video Reasoning
Jan 28, 2026Vision-Language Models have excelled at textual reasoning, but they often struggle with fine-grained spatial understanding and continuous action planning, failing to simulate the dynamics required for complex visual reasoning. In this work, we formulate visual reasoning by means of video generation models, positing that generated frames can act as intermediate reasoning steps between initial states and solutions. We evaluate their capacity in two distinct regimes: Maze Navigation for sequential discrete planning with low visual change and Tangram Puzzle for continuous manipulation with high visual change. Our experiments reveal three critical insights: (1) Robust Zero-Shot Generalization: In both tasks, the model demonstrates strong performance on unseen data distributions without specific finetuning. (2) Visual Context: The model effectively uses visual context as explicit control, such as agent icons and tangram shapes, enabling it to maintain high visual consistency and adapt its planning capability robustly to unseen patterns. (3) Visual Test-Time Scaling: We observe a test-time scaling law in sequential planning; increasing the generated video length (visual inference budget) empowers better zero-shot generalization to spatially and temporally complex paths. These findings suggest that video generation is not merely a media tool, but a scalable, generalizable paradigm for visual reasoning.
Decoupling the Effect of Chain-of-Thought Reasoning: A Human Label Variation Perspective
Jan 06, 2026Reasoning-tuned LLMs utilizing long Chain-of-Thought (CoT) excel at single-answer tasks, yet their ability to model Human Label Variation--which requires capturing probabilistic ambiguity rather than resolving it--remains underexplored. We investigate this through systematic disentanglement experiments on distribution-based tasks, employing Cross-CoT experiments to isolate the effect of reasoning text from intrinsic model priors. We observe a distinct "decoupled mechanism": while CoT improves distributional alignment, final accuracy is dictated by CoT content (99% variance contribution), whereas distributional ranking is governed by model priors (over 80%). Step-wise analysis further shows that while CoT's influence on accuracy grows monotonically during the reasoning process, distributional structure is largely determined by LLM's intrinsic priors. These findings suggest that long CoT serves as a decisive LLM decision-maker for the top option but fails to function as a granular distribution calibrator for ambiguous tasks.
Bolmo: Byteifying the Next Generation of Language Models
Dec 17, 2025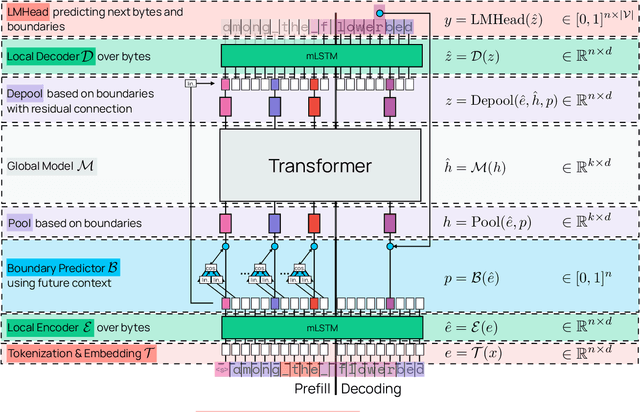
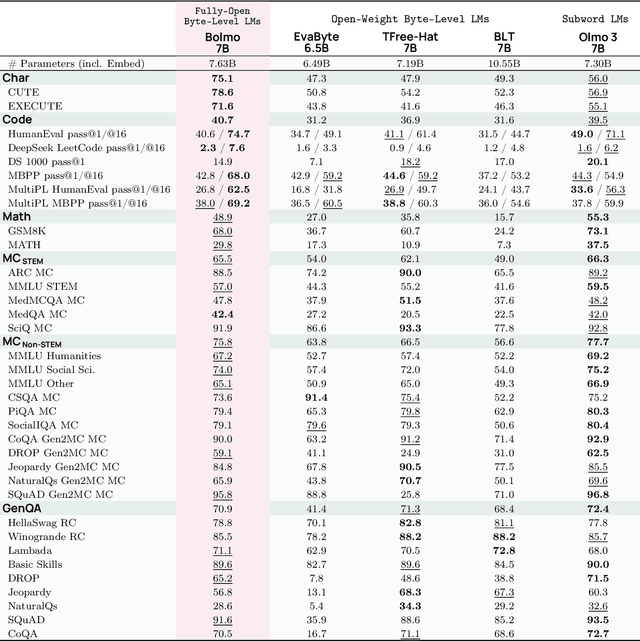
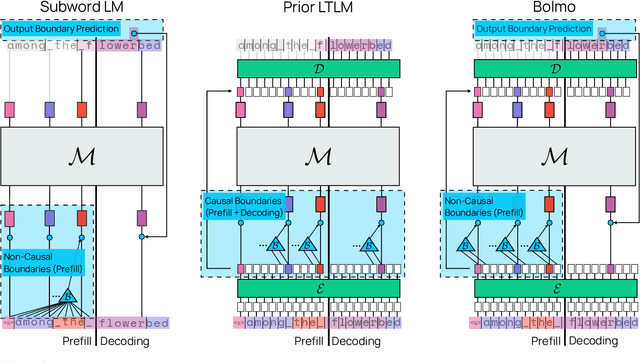
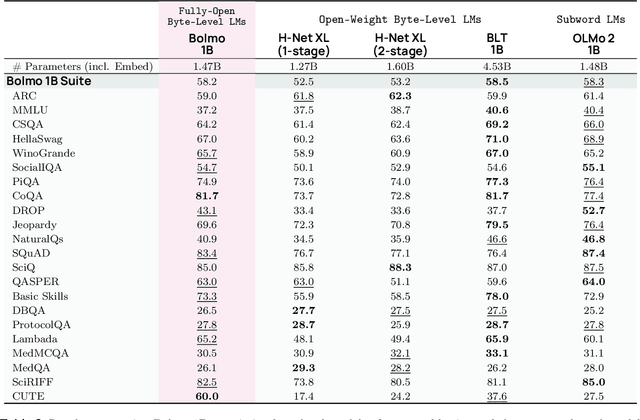
We introduce Bolmo, the first family of competitive fully open byte-level language models (LMs) at the 1B and 7B parameter scales. In contrast to prior research on byte-level LMs, which focuses predominantly on training from scratch, we train Bolmo by byteifying existing subword-level LMs. Byteification enables overcoming the limitations of subword tokenization - such as insufficient character understanding and efficiency constraints due to the fixed subword vocabulary - while performing at the level of leading subword-level LMs. Bolmo is specifically designed for byteification: our architecture resolves a mismatch between the expressivity of prior byte-level architectures and subword-level LMs, which makes it possible to employ an effective exact distillation objective between Bolmo and the source subword model. This allows for converting a subword-level LM to a byte-level LM by investing less than 1\% of a typical pretraining token budget. Bolmo substantially outperforms all prior byte-level LMs of comparable size, and outperforms the source subword-level LMs on character understanding and, in some cases, coding, while coming close to matching the original LMs' performance on other tasks. Furthermore, we show that Bolmo can achieve inference speeds competitive with subword-level LMs by training with higher token compression ratios, and can be cheaply and effectively post-trained by leveraging the existing ecosystem around the source subword-level LM. Our results finally make byte-level LMs a practical choice competitive with subword-level LMs across a wide set of use cases.
Donors and Recipients: On Asymmetric Transfer Across Tasks and Languages with Parameter-Efficient Fine-Tuning
Nov 17, 2025
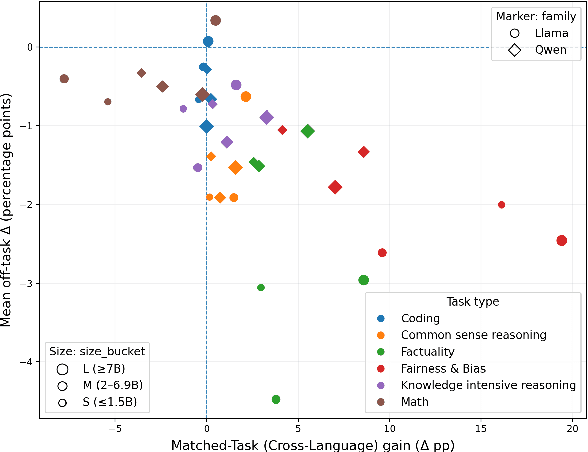
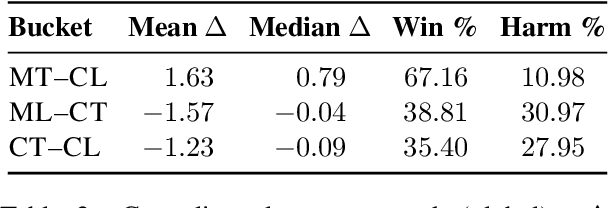
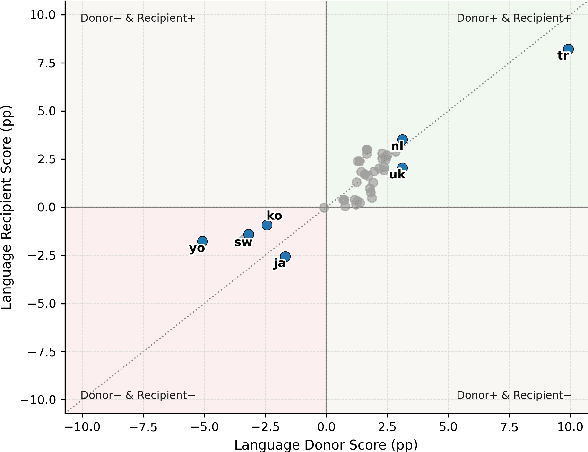
Large language models (LLMs) perform strongly across tasks and languages, yet how improvements in one task or language affect other tasks and languages and their combinations remains poorly understood. We conduct a controlled PEFT/LoRA study across multiple open-weight LLM families and sizes, treating task and language as transfer axes while conditioning on model family and size; we fine-tune each model on a single task-language source and measure transfer as the percentage-point change versus its baseline score when evaluated on all other task-language target pairs. We decompose transfer into (i) Matched-Task (Cross-Language), (ii) Matched-Language (Cross-Task), and (iii) Cross-Task (Cross-Language) regimes. We uncover two consistent general patterns. First, a pronounced on-task vs. off-task asymmetry: Matched-Task (Cross-Language) transfer is reliably positive, whereas off-task transfer often incurs collateral degradation. Second, a stable donor-recipient structure across languages and tasks (hub donors vs. brittle recipients). We outline implications for risk-aware fine-tuning and model specialisation.
Quantifying Language Disparities in Multilingual Large Language Models
Aug 23, 2025Results reported in large-scale multilingual evaluations are often fragmented and confounded by factors such as target languages, differences in experimental setups, and model choices. We propose a framework that disentangles these confounding variables and introduces three interpretable metrics--the performance realisation ratio, its coefficient of variation, and language potential--enabling a finer-grained and more insightful quantification of actual performance disparities across both (i) models and (ii) languages. Through a case study of 13 model variants on 11 multilingual datasets, we demonstrate that our framework provides a more reliable measurement of model performance and language disparities, particularly for low-resource languages, which have so far proven challenging to evaluate. Importantly, our results reveal that higher overall model performance does not necessarily imply greater fairness across languages.
Iterative Multilingual Spectral Attribute Erasure
Jun 12, 2025Multilingual representations embed words with similar meanings to share a common semantic space across languages, creating opportunities to transfer debiasing effects between languages. However, existing methods for debiasing are unable to exploit this opportunity because they operate on individual languages. We present Iterative Multilingual Spectral Attribute Erasure (IMSAE), which identifies and mitigates joint bias subspaces across multiple languages through iterative SVD-based truncation. Evaluating IMSAE across eight languages and five demographic dimensions, we demonstrate its effectiveness in both standard and zero-shot settings, where target language data is unavailable, but linguistically similar languages can be used for debiasing. Our comprehensive experiments across diverse language models (BERT, LLaMA, Mistral) show that IMSAE outperforms traditional monolingual and cross-lingual approaches while maintaining model utility.
Bootstrapping World Models from Dynamics Models in Multimodal Foundation Models
Jun 06, 2025To what extent do vision-and-language foundation models possess a realistic world model (observation $\times$ action $\rightarrow$ observation) and a dynamics model (observation $\times$ observation $\rightarrow$ action), when actions are expressed through language? While open-source foundation models struggle with both, we find that fine-tuning them to acquire a dynamics model through supervision is significantly easier than acquiring a world model. In turn, dynamics models can be used to bootstrap world models through two main strategies: 1) weakly supervised learning from synthetic data and 2) inference time verification. Firstly, the dynamics model can annotate actions for unlabelled pairs of video frame observations to expand the training data. We further propose a new objective, where image tokens in observation pairs are weighted by their importance, as predicted by a recognition model. Secondly, the dynamics models can assign rewards to multiple samples of the world model to score them, effectively guiding search at inference time. We evaluate the world models resulting from both strategies through the task of action-centric image editing on Aurora-Bench. Our best model achieves a performance competitive with state-of-the-art image editing models, improving on them by a margin of $15\%$ on real-world subsets according to GPT4o-as-judge, and achieving the best average human evaluation across all subsets of Aurora-Bench.
Threading the Needle: Reweaving Chain-of-Thought Reasoning to Explain Human Label Variation
May 29, 2025



The recent rise of reasoning-tuned Large Language Models (LLMs)--which generate chains of thought (CoTs) before giving the final answer--has attracted significant attention and offers new opportunities for gaining insights into human label variation, which refers to plausible differences in how multiple annotators label the same data instance. Prior work has shown that LLM-generated explanations can help align model predictions with human label distributions, but typically adopt a reverse paradigm: producing explanations based on given answers. In contrast, CoTs provide a forward reasoning path that may implicitly embed rationales for each answer option, before generating the answers. We thus propose a novel LLM-based pipeline enriched with linguistically-grounded discourse segmenters to extract supporting and opposing statements for each answer option from CoTs with improved accuracy. We also propose a rank-based HLV evaluation framework that prioritizes the ranking of answers over exact scores, which instead favor direct comparison of label distributions. Our method outperforms a direct generation method as well as baselines on three datasets, and shows better alignment of ranking methods with humans, highlighting the effectiveness of our approach.