 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Design: Optimizing Agents with Better Prompts and Topologies
Feb 04, 2025Large language models, employed as multiple agents that interact and collaborate with each other, have excelled at solving complex tasks. The agents are programmed with prompts that declare their functionality, along with the topologies that orchestrate interactions across agents. Designing prompts and topologies for multi-agent systems (MAS) is inherently complex. To automate the entire design process, we first conduct an in-depth analysis of the design space aiming to understand the factors behind building effective MAS. We reveal that prompts together with topologies play critical roles in enabling more effective MAS design. Based on the insights, we propose Multi-Agent System Search (MASS), a MAS optimization framework that efficiently exploits the complex MAS design space by interleaving its optimization stages, from local to global, from prompts to topologies, over three stages: 1) block-level (local) prompt optimization; 2) workflow topology optimization; 3) workflow-level (global) prompt optimization, where each stage is conditioned on the iteratively optimized prompts/topologies from former stages. We show that MASS-optimized multi-agent systems outperform a spectrum of existing alternatives by a substantial margin. Based on the MASS-found systems, we finally propose design principles behind building effective multi-agent systems.
Learn-by-interact: A Data-Centric Framework for Self-Adaptive Agents in Realistic Environments
Jan 18, 2025



Autonomous agents powered by large language models (LLMs) have the potential to enhance human capabilities, assisting with digital tasks from sending emails to performing data analysis. The abilities of existing LLMs at such tasks are often hindered by the lack of high-quality agent data from the corresponding environments they interact with. We propose Learn-by-interact, a data-centric framework to adapt LLM agents to any given environments without human annotations. Learn-by-interact synthesizes trajectories of agent-environment interactions based on documentations, and constructs instructions by summarizing or abstracting the interaction histories, a process called backward construction. We assess the quality of our synthetic data by using them in both training-based scenarios and training-free in-context learning (ICL), where we craft innovative retrieval approaches optimized for agents. Extensive experiments on SWE-bench, WebArena, OSWorld and Spider2-V spanning across realistic coding, web, and desktop environments show the effectiveness of Learn-by-interact in various downstream agentic tasks -- baseline results are improved by up to 12.2\% for ICL with Claude-3.5 and 19.5\% for training with Codestral-22B. We further demonstrate the critical role of backward construction, which provides up to 14.0\% improvement for training. Our ablation studies demonstrate the efficiency provided by our synthesized data in ICL and the superiority of our retrieval pipeline over alternative approaches like conventional retrieval-augmented generation (RAG). We expect that Learn-by-interact will serve as a foundation for agent data synthesis as LLMs are increasingly deployed at real-world environments.
Data-Centric Improvements for Enhancing Multi-Modal Understanding in Spoken Conversation Modeling
Dec 20, 2024Conversational assistants are increasingly popular across diverse real-world applications, highlighting the need for advanced multimodal speech modeling. Speech, as a natural mode of communication, encodes rich user-specific characteristics such as speaking rate and pitch, making it critical for effective interaction. Our work introduces a data-centric customization approach for efficiently enhancing multimodal understanding in conversational speech modeling. Central to our contributions is a novel multi-task learning paradigm that involves designing auxiliary tasks to utilize a small amount of speech data. Our approach achieves state-of-the-art performance on the Spoken-SQuAD benchmark, using only 10% of the training data with open-weight models, establishing a robust and efficient framework for audio-centric conversational modeling. We also introduce ASK-QA, the first dataset for multi-turn spoken dialogue with ambiguous user requests and dynamic evaluation inputs. Code and data forthcoming.
Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models
Oct 09, 2024



Retrieval-Augmented Generation (RAG), while effective in integrating external knowledge to address the limitations of large language models (LLMs), can be undermined by imperfect retrieval, which may introduce irrelevant, misleading, or even malicious information. Despite its importance, previous studies have rarely explored the behavior of RAG through joint analysis on how errors from imperfect retrieval attribute and propagate, and how potential conflicts arise between the LLMs' internal knowledge and external sources. We find that imperfect retrieval augmentation might be inevitable and quite harmful, through controlled analysis under realistic conditions. We identify the knowledge conflicts between LLM-internal and external knowledge from retrieval as a bottleneck to overcome in the post-retrieval stage of RAG. To render LLMs resilient to imperfect retrieval, we propose Astute RAG, a novel RAG approach that adaptively elicits essential information from LLMs' internal knowledge, iteratively consolidates internal and external knowledge with source-awareness, and finalizes the answer according to information reliability. Our experiments using Gemini and Claude demonstrate that Astute RAG significantly outperforms previous robustness-enhanced RAG methods. Notably, Astute RAG is the only approach that matches or exceeds the performance of LLMs without RAG under worst-case scenarios. Further analysis reveals that Astute RAG effectively resolves knowledge conflicts, improving the reliability and trustworthiness of RAG systems.
Learning to Clarify: Multi-turn Conversations with Action-Based Contrastive Self-Training
May 31, 2024Large language models (LLMs) aligned through reinforcement learning from human feedback (RLHF) have quickly become one of the dominant paradigms for building intelligent conversational assistant agents. However, despite their strong performance across many benchmarks, LLM-based agents still lack conversational skills such as disambiguation: when generalized assistants are faced with ambiguity, they often overhedge or implicitly guess users' ground-truth intents rather than asking clarification questions, and under task-specific settings, high-quality conversation samples are often limited, affecting models' ability to learn optimal dialogue action policies. We propose Action-Based Contrastive Self-Training (henceforth ACT), a quasi-online preference optimization algorithm based on Direct Preference Optimization (DPO) which allows for sample-efficient dialogue policy learning in multi-turn conversation. We demonstrate ACT's efficacy under sample-efficient conditions in three difficult conversational tasks: tabular-grounded question-answering, machine reading comprehension, and AmbigSQL, a novel task for disambiguating information-seeking requests for text-to-SQL generation. Additionally, we propose evaluating LLMs' ability to function as conversational agents by examining whether they can implicitly recognize and reason about ambiguity in conversation. ACT demonstrates substantial conversation modeling improvements over standard approaches to supervised fine-tuning and DPO.
Mitigating Object Hallucination via Data Augmented Contrastive Tuning
May 28, 2024Despite their remarkable progress, Multimodal Large Language Models (MLLMs) tend to hallucinate factually inaccurate information. In this work, we address object hallucinations in MLLMs, where information is offered about an object that is not present in the model input. We introduce a contrastive tuning method that can be applied to a pretrained off-the-shelf MLLM for mitigating hallucinations while preserving its general vision-language capabilities. For a given factual token, we create a hallucinated token through generative data augmentation by selectively altering the ground-truth information. The proposed contrastive tuning is applied at the token level to improve the relative likelihood of the factual token compared to the hallucinated one. Our thorough evaluation confirms the effectiveness of contrastive tuning in mitigating hallucination. Moreover, the proposed contrastive tuning is simple, fast, and requires minimal training with no additional overhead at inference.
COSTAR: Improved Temporal Counterfactual Estimation with Self-Supervised Learning
Nov 01, 2023



Estimation of temporal counterfactual outcomes from observed history is crucial for decision-making in many domains such as healthcare and e-commerce, particularly when randomized controlled trials (RCTs) suffer from high cost or impracticality. For real-world datasets, modeling time-dependent confounders is challenging due to complex dynamics, long-range dependencies and both past treatments and covariates affecting the future outcomes. In this paper, we introduce COunterfactual Self-supervised TrAnsformeR (COSTAR), a novel approach that integrates self-supervised learning for improved historical representations. The proposed framework combines temporal and feature-wise attention with a component-wise contrastive loss tailored for temporal treatment outcome observations, yielding superior performance in estimation accuracy and generalization to out-of-distribution data compared to existing models, as validated by empirical results on both synthetic and real-world datasets.
Resource-Efficient Neural Architect
Jun 12, 2018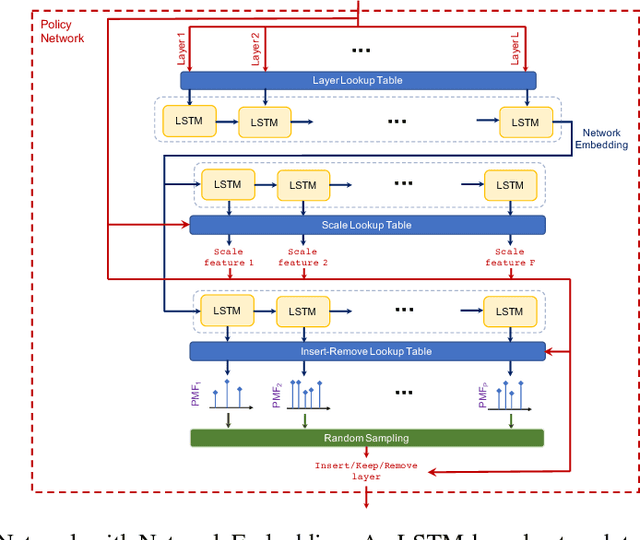
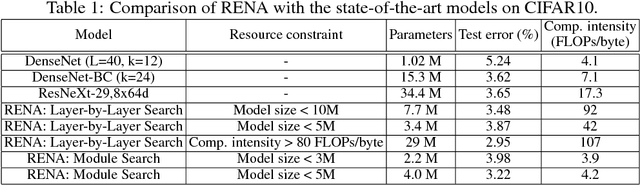
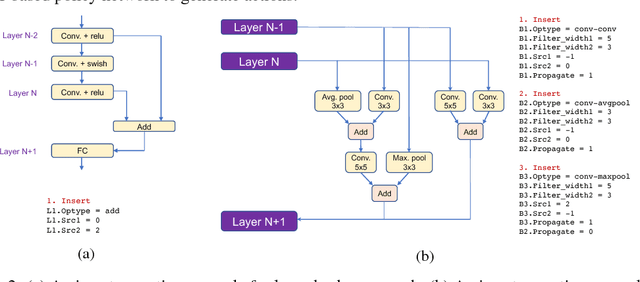
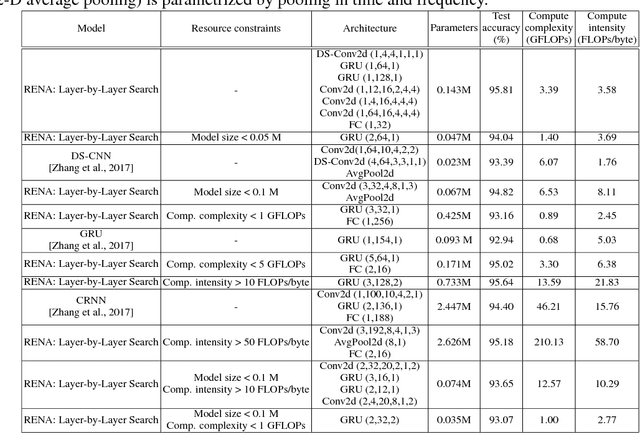
Neural Architecture Search (NAS) is a laborious process. Prior work on automated NAS targets mainly on improving accuracy, but lacks consideration of computational resource use. We propose the Resource-Efficient Neural Architect (RENA), an efficient resource-constrained NAS using reinforcement learning with network embedding. RENA uses a policy network to process the network embeddings to generate new configurations. We demonstrate RENA on image recognition and keyword spotting (KWS) problems. RENA can find novel architectures that achieve high performance even with tight resource constraints. For CIFAR10, it achieves 2.95% test error when compute intensity is greater than 100 FLOPs/byte, and 3.87% test error when model size is less than 3M parameters. For Google Speech Commands Dataset, RENA achieves the state-of-the-art accuracy without resource constraints, and it outperforms the optimized architectures with tight resource constraints.