 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThoughtTrace: Understanding User Thoughts in Real-World LLM Interactions
May 19, 2026Conversational AI has now reached billions of users, yet existing datasets capture only what people say, not what they think. We introduce ThoughtTrace, the first large-scale dataset that pairs real-world multi-turn human--AI conversations with users' self-reported thoughts: their reasons for sending prompts and reactions to assistant responses. ThoughtTrace comprises 1,058 users, 2,155 conversations, 17,058 turns, and 10,174 thought annotations collected across 20 language models. Our analysis shows that ThoughtTrace captures long-horizon, topically diverse interactions, and that thoughts are semantically distinct from messages, difficult for frontier LLMs to infer from context, diverse in content, and tied to conversation stages. We further demonstrate the utility of thoughts for downstream modeling. First, thoughts improve user-behavior prediction as inference-time context. Second, thought-guided rewrites provide fine-grained alignment signals for training personalized assistants. Together, ThoughtTrace establishes user thoughts as a new data modality for studying the cognitive dynamics behind human--AI interaction and provides a foundation for building assistants that better understand and adapt to users' latent goals, preferences, and needs.
Bottom-Up Synthesis of Knowledge-Grounded Task-Oriented Dialogues with Iteratively Self-Refined Prompts
Apr 19, 2025Training conversational question-answering (QA) systems requires a substantial amount of in-domain data, which is often scarce in practice. A common solution to this challenge is to generate synthetic data. Traditional methods typically follow a top-down approach, where a large language model (LLM) generates multi-turn dialogues from a broad prompt. Although this method produces coherent conversations, it offers limited fine-grained control over the content and is susceptible to hallucinations. We introduce a bottom-up conversation synthesis approach, where QA pairs are generated first and then combined into a coherent dialogue. This method offers greater control and precision by dividing the process into two distinct steps, allowing refined instructions and validations to be handled separately. Additionally, this structure allows the use of non-local models in stages that do not involve proprietary knowledge, enhancing the overall quality of the generated data. Both human and automated evaluations demonstrate that our approach produces more realistic and higher-quality dialogues compared to top-down methods.
Data-Centric Improvements for Enhancing Multi-Modal Understanding in Spoken Conversation Modeling
Dec 20, 2024Conversational assistants are increasingly popular across diverse real-world applications, highlighting the need for advanced multimodal speech modeling. Speech, as a natural mode of communication, encodes rich user-specific characteristics such as speaking rate and pitch, making it critical for effective interaction. Our work introduces a data-centric customization approach for efficiently enhancing multimodal understanding in conversational speech modeling. Central to our contributions is a novel multi-task learning paradigm that involves designing auxiliary tasks to utilize a small amount of speech data. Our approach achieves state-of-the-art performance on the Spoken-SQuAD benchmark, using only 10% of the training data with open-weight models, establishing a robust and efficient framework for audio-centric conversational modeling. We also introduce ASK-QA, the first dataset for multi-turn spoken dialogue with ambiguous user requests and dynamic evaluation inputs. Code and data forthcoming.
VarBench: Robust Language Model Benchmarking Through Dynamic Variable Perturbation
Jun 26, 2024



As large language models achieve impressive scores on traditional benchmarks, an increasing number of researchers are becoming concerned about benchmark data leakage during pre-training, commonly known as the data contamination problem. To ensure fair evaluation, recent benchmarks release only the training and validation sets, keeping the test set labels closed-source. They require anyone wishing to evaluate his language model to submit the model's predictions for centralized processing and then publish the model's result on their leaderboard. However, this submission process is inefficient and prevents effective error analysis. To address this issue, we propose to variabilize benchmarks and evaluate language models dynamically. Specifically, we extract variables from each test case and define a value range for each variable. For each evaluation, we sample new values from these value ranges to create unique test cases, thus ensuring a fresh evaluation each time. We applied this variable perturbation method to four datasets: GSM8K, ARC, CommonsenseQA, and TruthfulQA, which cover mathematical generation and multiple-choice tasks. Our experimental results demonstrate that this approach provides a more accurate assessment of the true capabilities of language models, effectively mitigating the contamination problem.
Learning to Clarify: Multi-turn Conversations with Action-Based Contrastive Self-Training
May 31, 2024



Large language models (LLMs) aligned through reinforcement learning from human feedback (RLHF) have quickly become one of the dominant paradigms for building intelligent conversational assistant agents. However, despite their strong performance across many benchmarks, LLM-based agents still lack conversational skills such as disambiguation: when generalized assistants are faced with ambiguity, they often overhedge or implicitly guess users' ground-truth intents rather than asking clarification questions, and under task-specific settings, high-quality conversation samples are often limited, affecting models' ability to learn optimal dialogue action policies. We propose Action-Based Contrastive Self-Training (henceforth ACT), a quasi-online preference optimization algorithm based on Direct Preference Optimization (DPO) which allows for sample-efficient dialogue policy learning in multi-turn conversation. We demonstrate ACT's efficacy under sample-efficient conditions in three difficult conversational tasks: tabular-grounded question-answering, machine reading comprehension, and AmbigSQL, a novel task for disambiguating information-seeking requests for text-to-SQL generation. Additionally, we propose evaluating LLMs' ability to function as conversational agents by examining whether they can implicitly recognize and reason about ambiguity in conversation. ACT demonstrates substantial conversation modeling improvements over standard approaches to supervised fine-tuning and DPO.
Prompt-Based Monte-Carlo Tree Search for Goal-Oriented Dialogue Policy Planning
May 23, 2023Planning for goal-oriented dialogue often requires simulating future dialogue interactions and estimating task progress. Many approaches thus consider training neural networks to perform look-ahead search algorithms such as A* search and Monte Carlo Tree Search (MCTS). However, this training often require abundant annotated data, which creates challenges when faced with noisy annotations or low-resource settings. We introduce GDP-Zero, an approach using Open-Loop MCTS to perform goal-oriented dialogue policy planning without any model training. GDP-Zero prompts a large language model to act as a policy prior, value function, user simulator, and system model during the tree search. We evaluate GDP-Zero on the goal-oriented task PersuasionForGood, and find that its responses are preferred over ChatGPT up to 59.32% of the time, and are rated more persuasive than ChatGPT during interactive evaluations.
Controllable Mixed-Initiative Dialogue Generation through Prompting
May 06, 2023



Mixed-initiative dialogue tasks involve repeated exchanges of information and conversational control. Conversational agents gain control by generating responses that follow particular dialogue intents or strategies, prescribed by a policy planner. The standard approach has been fine-tuning pre-trained language models to perform generation conditioned on these intents. However, these supervised generation models are limited by the cost and quality of data annotation. We instead prompt large language models as a drop-in replacement to fine-tuning on conditional generation. We formalize prompt construction for controllable mixed-initiative dialogue. Our findings show improvements over fine-tuning and ground truth responses according to human evaluation and automatic metrics for two tasks: PersuasionForGood and Emotional Support Conversations.
Pre-Finetuning for Few-Shot Emotional Speech Recognition
Feb 28, 2023



Speech models have long been known to overfit individual speakers for many classification tasks. This leads to poor generalization in settings where the speakers are out-of-domain or out-of-distribution, as is common in production environments. We view speaker adaptation as a few-shot learning problem and propose investigating transfer learning approaches inspired by recent success with pre-trained models in natural language tasks. We propose pre-finetuning speech models on difficult tasks to distill knowledge into few-shot downstream classification objectives. We pre-finetune Wav2Vec2.0 on every permutation of four multiclass emotional speech recognition corpora and evaluate our pre-finetuned models through 33,600 few-shot fine-tuning trials on the Emotional Speech Dataset.
PLACES: Prompting Language Models for Social Conversation Synthesis
Feb 17, 2023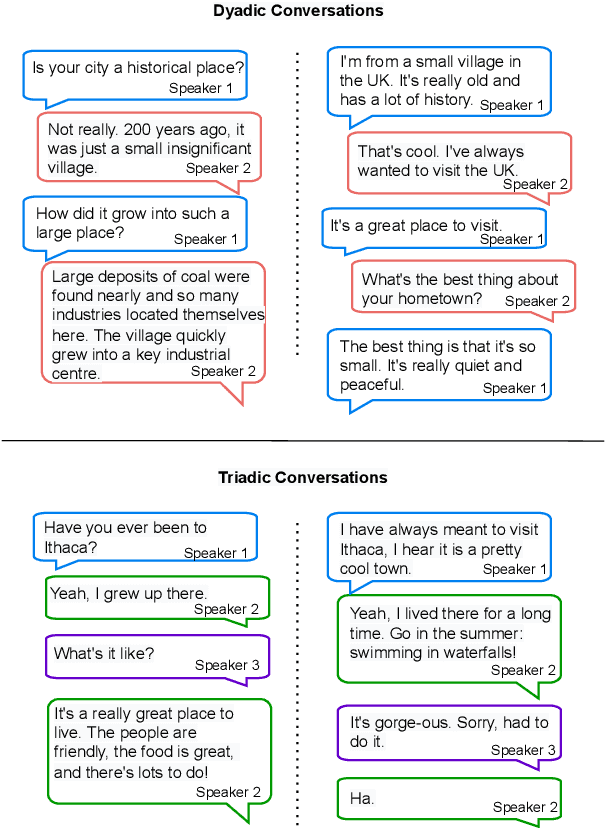
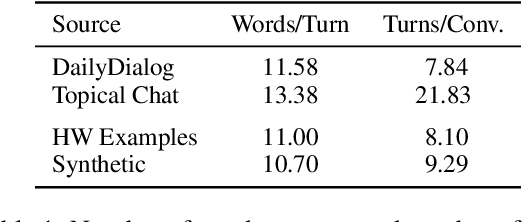
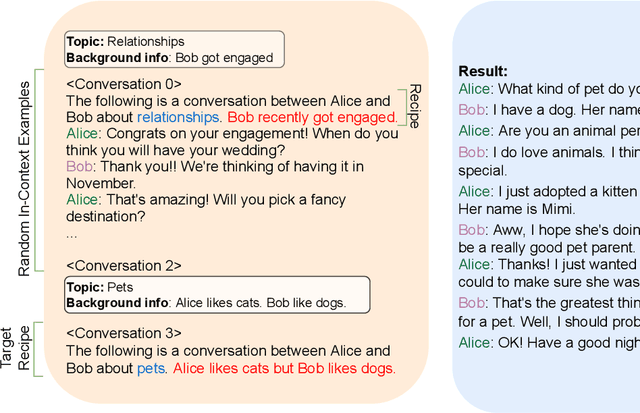
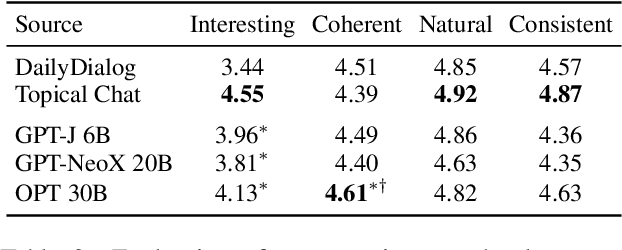
Collecting high quality conversational data can be very expensive for most applications and infeasible for others due to privacy, ethical, or similar concerns. A promising direction to tackle this problem is to generate synthetic dialogues by prompting large language models. In this work, we use a small set of expert-written conversations as in-context examples to synthesize a social conversation dataset using prompting. We perform several thorough evaluations of our synthetic conversations compared to human-collected conversations. This includes various dimensions of conversation quality with human evaluation directly on the synthesized conversations, and interactive human evaluation of chatbots fine-tuned on the synthetically generated dataset. We additionally demonstrate that this prompting approach is generalizable to multi-party conversations, providing potential to create new synthetic data for multi-party tasks. Our synthetic multi-party conversations were rated more favorably across all measured dimensions compared to conversation excerpts sampled from a human-collected multi-party dataset.
Weakly Supervised Data Augmentation Through Prompting for Dialogue Understanding
Nov 02, 2022



Dialogue understanding tasks often necessitate abundant annotated data to achieve good performance and that presents challenges in low-resource settings. To alleviate this barrier, we explore few-shot data augmentation for dialogue understanding by prompting large pre-trained language models and present a novel approach that iterates on augmentation quality by applying weakly-supervised filters. We evaluate our methods on the emotion and act classification tasks in DailyDialog and the intent classification task in Facebook Multilingual Task-Oriented Dialogue. Models fine-tuned on our augmented data mixed with few-shot ground truth data are able to approach or surpass existing state-of-the-art performance on both datasets. For DailyDialog specifically, using 10% of the ground truth data we outperform the current state-of-the-art model which uses 100% of the data.