 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS: Modular Agent with Reflective Search for Automated AI Research
Feb 02, 2026Automating AI research differs from general software engineering due to computationally expensive evaluation (e.g., model training) and opaque performance attribution. Current LLM-based agents struggle here, often generating monolithic scripts that ignore execution costs and causal factors. We introduce MARS (Modular Agent with Reflective Search), a framework optimized for autonomous AI research. MARS relies on three pillars: (1) Budget-Aware Planning via cost-constrained Monte Carlo Tree Search (MCTS) to explicitly balance performance with execution expense; (2) Modular Construction, employing a "Design-Decompose-Implement" pipeline to manage complex research repositories; and (3) Comparative Reflective Memory, which addresses credit assignment by analyzing solution differences to distill high-signal insights. MARS achieves state-of-the-art performance among open-source frameworks on MLE-Bench under comparable settings, maintaining competitiveness with the global leaderboard's top methods. Furthermore, the system exhibits qualitative "Aha!" moments, where 63% of all utilized lessons originate from cross-branch transfer, demonstrating that the agent effectively generalizes insights across search paths.
Co-RedTeam: Orchestrated Security Discovery and Exploitation with LLM Agents
Feb 02, 2026Large language models (LLMs) have shown promise in assisting cybersecurity tasks, yet existing approaches struggle with automatic vulnerability discovery and exploitation due to limited interaction, weak execution grounding, and a lack of experience reuse. We propose Co-RedTeam, a security-aware multi-agent framework designed to mirror real-world red-teaming workflows by integrating security-domain knowledge, code-aware analysis, execution-grounded iterative reasoning, and long-term memory. Co-RedTeam decomposes vulnerability analysis into coordinated discovery and exploitation stages, enabling agents to plan, execute, validate, and refine actions based on real execution feedback while learning from prior trajectories. Extensive evaluations on challenging security benchmarks demonstrate that Co-RedTeam consistently outperforms strong baselines across diverse backbone models, achieving over 60% success rate in vulnerability exploitation and over 10% absolute improvement in vulnerability detection. Ablation and iteration studies further confirm the critical role of execution feedback, structured interaction, and memory for building robust and generalizable cybersecurity agents.
PaperBanana: Automating Academic Illustration for AI Scientists
Jan 30, 2026Despite rapid advances in autonomous AI scientists powered by language models, generating publication-ready illustrations remains a labor-intensive bottleneck in the research workflow. To lift this burden, we introduce PaperBanana, an agentic framework for automated generation of publication-ready academic illustrations. Powered by state-of-the-art VLMs and image generation models, PaperBanana orchestrates specialized agents to retrieve references, plan content and style, render images, and iteratively refine via self-critique. To rigorously evaluate our framework, we introduce PaperBananaBench, comprising 292 test cases for methodology diagrams curated from NeurIPS 2025 publications, covering diverse research domains and illustration styles. Comprehensive experiments demonstrate that PaperBanana consistently outperforms leading baselines in faithfulness, conciseness, readability, and aesthetics. We further show that our method effectively extends to the generation of high-quality statistical plots. Collectively, PaperBanana paves the way for the automated generation of publication-ready illustrations.
ScholarPeer: A Context-Aware Multi-Agent Framework for Automated Peer Review
Jan 30, 2026Automated peer review has evolved from simple text classification to structured feedback generation. However, current state-of-the-art systems still struggle with "surface-level" critiques: they excel at summarizing content but often fail to accurately assess novelty and significance or identify deep methodological flaws because they evaluate papers in a vacuum, lacking the external context a human expert possesses. In this paper, we introduce ScholarPeer, a search-enabled multi-agent framework designed to emulate the cognitive processes of a senior researcher. ScholarPeer employs a dual-stream process of context acquisition and active verification. It dynamically constructs a domain narrative using a historian agent, identifies missing comparisons via a baseline scout, and verifies claims through a multi-aspect Q&A engine, grounding the critique in live web-scale literature. We evaluate ScholarPeer on DeepReview-13K and the results demonstrate that ScholarPeer achieves significant win-rates against state-of-the-art approaches in side-by-side evaluations and reduces the gap to human-level diversity.
SAGE: Steerable Agentic Data Generation for Deep Search with Execution Feedback
Jan 26, 2026Deep search agents, which aim to answer complex questions requiring reasoning across multiple documents, can significantly speed up the information-seeking process. Collecting human annotations for this application is prohibitively expensive due to long and complex exploration trajectories. We propose an agentic pipeline that automatically generates high quality, difficulty-controlled deep search question-answer pairs for a given corpus and a target difficulty level. Our pipeline, SAGE, consists of a data generator which proposes QA pairs and a search agent which attempts to solve the generated question and provide execution feedback for the data generator. The two components interact over multiple rounds to iteratively refine the question-answer pairs until they satisfy the target difficulty level. Our intrinsic evaluation shows SAGE generates questions that require diverse reasoning strategies, while significantly increases the correctness and difficulty of the generated data. Our extrinsic evaluation demonstrates up to 23% relative performance gain on popular deep search benchmarks by training deep search agents with our synthetic data. Additional experiments show that agents trained on our data can adapt from fixed-corpus retrieval to Google Search at inference time, without further training.
DocLens : A Tool-Augmented Multi-Agent Framework for Long Visual Document Understanding
Nov 14, 2025Comprehending long visual documents, where information is distributed across extensive pages of text and visual elements, is a critical but challenging task for modern Vision-Language Models (VLMs). Existing approaches falter on a fundamental challenge: evidence localization. They struggle to retrieve relevant pages and overlook fine-grained details within visual elements, leading to limited performance and model hallucination. To address this, we propose DocLens, a tool-augmented multi-agent framework that effectively ``zooms in'' on evidence like a lens. It first navigates from the full document to specific visual elements on relevant pages, then employs a sampling-adjudication mechanism to generate a single, reliable answer. Paired with Gemini-2.5-Pro, DocLens achieves state-of-the-art performance on MMLongBench-Doc and FinRAGBench-V, surpassing even human experts. The framework's superiority is particularly evident on vision-centric and unanswerable queries, demonstrating the power of its enhanced localization capabilities.
Synapse: Adaptive Arbitration of Complementary Expertise in Time Series Foundational Models
Nov 07, 2025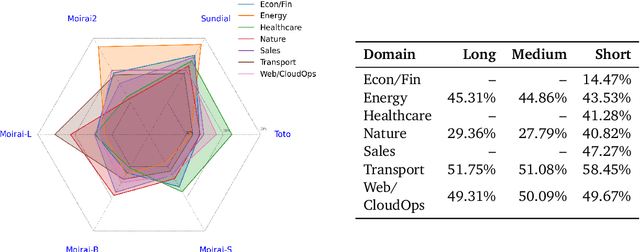
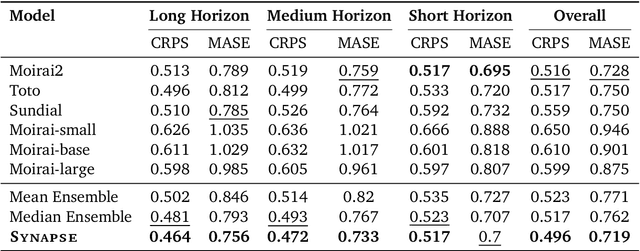
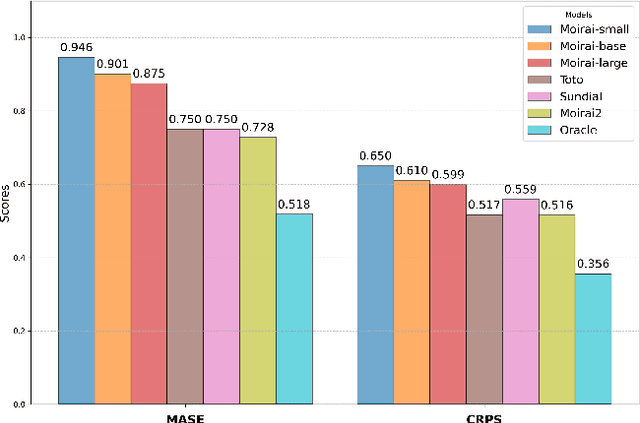

Pre-trained Time Series Foundational Models (TSFMs) represent a significant advance, capable of forecasting diverse time series with complex characteristics, including varied seasonalities, trends, and long-range dependencies. Despite their primary goal of universal time series forecasting, their efficacy is far from uniform; divergent training protocols and data sources cause individual TSFMs to exhibit highly variable performance across different forecasting tasks, domains, and horizons. Leveraging this complementary expertise by arbitrating existing TSFM outputs presents a compelling strategy, yet this remains a largely unexplored area of research. In this paper, we conduct a thorough examination of how different TSFMs exhibit specialized performance profiles across various forecasting settings, and how we can effectively leverage this behavior in arbitration between different time series models. We specifically analyze how factors such as model selection and forecast horizon distribution can influence the efficacy of arbitration strategies. Based on this analysis, we propose Synapse, a novel arbitration framework for TSFMs. Synapse is designed to dynamically leverage a pool of TSFMs, assign and adjust predictive weights based on their relative, context-dependent performance, and construct a robust forecast distribution by adaptively sampling from the output quantiles of constituent models. Experimental results demonstrate that Synapse consistently outperforms other popular ensembling techniques as well as individual TSFMs, demonstrating Synapse's efficacy in time series forecasting.
Supervised Reinforcement Learning: From Expert Trajectories to Step-wise Reasoning
Oct 29, 2025Large Language Models (LLMs) often struggle with problems that require multi-step reasoning. For small-scale open-source models, Reinforcement Learning with Verifiable Rewards (RLVR) fails when correct solutions are rarely sampled even after many attempts, while Supervised Fine-Tuning (SFT) tends to overfit long demonstrations through rigid token-by-token imitation. To address this gap, we propose Supervised Reinforcement Learning (SRL), a framework that reformulates problem solving as generating a sequence of logical "actions". SRL trains the model to generate an internal reasoning monologue before committing to each action. It provides smoother rewards based on the similarity between the model's actions and expert actions extracted from the SFT dataset in a step-wise manner. This supervision offers richer learning signals even when all rollouts are incorrect, while encouraging flexible reasoning guided by expert demonstrations. As a result, SRL enables small models to learn challenging problems previously unlearnable by SFT or RLVR. Moreover, initializing training with SRL before refining with RLVR yields the strongest overall performance. Beyond reasoning benchmarks, SRL generalizes effectively to agentic software engineering tasks, establishing it as a robust and versatile training framework for reasoning-oriented LLMs.
Watch and Learn: Learning to Use Computers from Online Videos
Oct 06, 2025Computer use agents (CUAs) need to plan task workflows grounded in diverse, ever-changing applications and environments, but learning is hindered by the scarcity of large-scale, high-quality training data in the target application. Existing datasets are domain-specific, static, and costly to annotate, while current synthetic data generation methods often yield simplistic or misaligned task demonstrations. To address these limitations, we introduce Watch & Learn (W&L), a framework that converts human demonstration videos readily available on the Internet into executable UI trajectories at scale. Instead of directly generating trajectories or relying on ad hoc reasoning heuristics, we cast the problem as an inverse dynamics objective: predicting the user's action from consecutive screen states. This formulation reduces manual engineering, is easier to learn, and generalizes more robustly across applications. Concretely, we develop an inverse dynamics labeling pipeline with task-aware video retrieval, generate over 53k high-quality trajectories from raw web videos, and demonstrate that these trajectories improve CUAs both as in-context demonstrations and as supervised training data. On the challenging OSWorld benchmark, UI trajectories extracted with W&L consistently enhance both general-purpose and state-of-the-art frameworks in-context, and deliver stronger gains for open-source models under supervised training. These results highlight web-scale human demonstration videos as a practical and scalable foundation for advancing CUAs towards real-world deployment.
PLAN-TUNING: Post-Training Language Models to Learn Step-by-Step Planning for Complex Problem Solving
Jul 10, 2025Recently, decomposing complex problems into simple subtasks--a crucial part of human-like natural planning--to solve the given problem has significantly boosted the performance of large language models (LLMs). However, leveraging such planning structures during post-training to boost the performance of smaller open-source LLMs remains underexplored. Motivated by this, we introduce PLAN-TUNING, a unified post-training framework that (i) distills synthetic task decompositions (termed "planning trajectories") from large-scale LLMs and (ii) fine-tunes smaller models via supervised and reinforcement-learning objectives designed to mimic these planning processes to improve complex reasoning. On GSM8k and the MATH benchmarks, plan-tuned models outperform strong baselines by an average $\sim7\%$. Furthermore, plan-tuned models show better generalization capabilities on out-of-domain datasets, with average $\sim10\%$ and $\sim12\%$ performance improvements on OlympiadBench and AIME 2024, respectively. Our detailed analysis demonstrates how planning trajectories improves complex reasoning capabilities, showing that PLAN-TUNING is an effective strategy for improving task-specific performance of smaller LLMs.