 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE: Steerable Agentic Data Generation for Deep Search with Execution Feedback
Jan 26, 2026Deep search agents, which aim to answer complex questions requiring reasoning across multiple documents, can significantly speed up the information-seeking process. Collecting human annotations for this application is prohibitively expensive due to long and complex exploration trajectories. We propose an agentic pipeline that automatically generates high quality, difficulty-controlled deep search question-answer pairs for a given corpus and a target difficulty level. Our pipeline, SAGE, consists of a data generator which proposes QA pairs and a search agent which attempts to solve the generated question and provide execution feedback for the data generator. The two components interact over multiple rounds to iteratively refine the question-answer pairs until they satisfy the target difficulty level. Our intrinsic evaluation shows SAGE generates questions that require diverse reasoning strategies, while significantly increases the correctness and difficulty of the generated data. Our extrinsic evaluation demonstrates up to 23% relative performance gain on popular deep search benchmarks by training deep search agents with our synthetic data. Additional experiments show that agents trained on our data can adapt from fixed-corpus retrieval to Google Search at inference time, without further training.
Supervised Reinforcement Learning: From Expert Trajectories to Step-wise Reasoning
Oct 29, 2025Large Language Models (LLMs) often struggle with problems that require multi-step reasoning. For small-scale open-source models, Reinforcement Learning with Verifiable Rewards (RLVR) fails when correct solutions are rarely sampled even after many attempts, while Supervised Fine-Tuning (SFT) tends to overfit long demonstrations through rigid token-by-token imitation. To address this gap, we propose Supervised Reinforcement Learning (SRL), a framework that reformulates problem solving as generating a sequence of logical "actions". SRL trains the model to generate an internal reasoning monologue before committing to each action. It provides smoother rewards based on the similarity between the model's actions and expert actions extracted from the SFT dataset in a step-wise manner. This supervision offers richer learning signals even when all rollouts are incorrect, while encouraging flexible reasoning guided by expert demonstrations. As a result, SRL enables small models to learn challenging problems previously unlearnable by SFT or RLVR. Moreover, initializing training with SRL before refining with RLVR yields the strongest overall performance. Beyond reasoning benchmarks, SRL generalizes effectively to agentic software engineering tasks, establishing it as a robust and versatile training framework for reasoning-oriented LLMs.
In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents
Mar 11, 2025Large Language Models (LLMs) have made significant progress in open-ended dialogue, yet their inability to retain and retrieve relevant information from long-term interactions limits their effectiveness in applications requiring sustained personalization. External memory mechanisms have been proposed to address this limitation, enabling LLMs to maintain conversational continuity. However, existing approaches struggle with two key challenges. First, rigid memory granularity fails to capture the natural semantic structure of conversations, leading to fragmented and incomplete representations. Second, fixed retrieval mechanisms cannot adapt to diverse dialogue contexts and user interaction patterns. In this work, we propose Reflective Memory Management (RMM), a novel mechanism for long-term dialogue agents, integrating forward- and backward-looking reflections: (1) Prospective Reflection, which dynamically summarizes interactions across granularities-utterances, turns, and sessions-into a personalized memory bank for effective future retrieval, and (2) Retrospective Reflection, which iteratively refines the retrieval in an online reinforcement learning (RL) manner based on LLMs' cited evidence. Experiments show that RMM demonstrates consistent improvement across various metrics and benchmarks. For example, RMM shows more than 10% accuracy improvement over the baseline without memory management on the LongMemEval dataset.
Magnet: Multi-turn Tool-use Data Synthesis and Distillation via Graph Translation
Mar 10, 2025



Large language models (LLMs) have exhibited the ability to effectively utilize external tools to address user queries. However, their performance may be limited in complex, multi-turn interactions involving users and multiple tools. To address this, we propose Magnet, a principled framework for synthesizing high-quality training trajectories to enhance the function calling capability of large language model agents in multi-turn conversations with humans. The framework is based on automatic and iterative translations from a function signature path to a sequence of queries and executable function calls. We model the complicated function interactions in multi-turn cases with graph and design novel node operations to build reliable signature paths. Motivated by context distillation, when guiding the generation of positive and negative trajectories using a teacher model, we provide reference function call sequences as positive hints in context and contrastive, incorrect function calls as negative hints. Experiments show that training with the positive trajectories with supervised fine-tuning and preference optimization against negative trajectories, our 14B model, Magnet-14B-mDPO, obtains 68.01 on BFCL-v3 and 73.30 on ToolQuery, surpassing the performance of the teacher model Gemini-1.5-pro-002 by a large margin in function calling.
FIG: Forward-Inverse Generation for Low-Resource Domain-specific Event Detection
Feb 24, 2025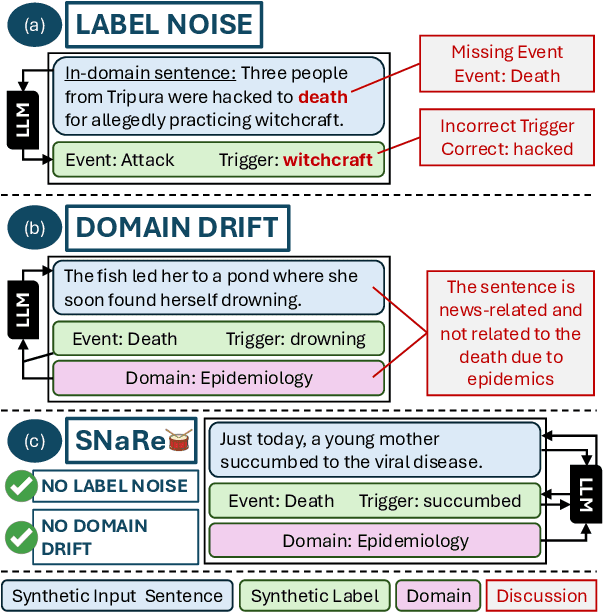
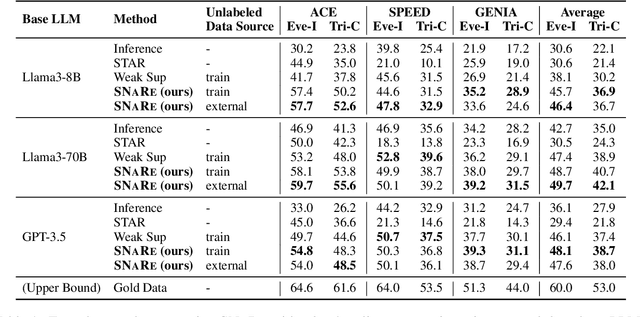
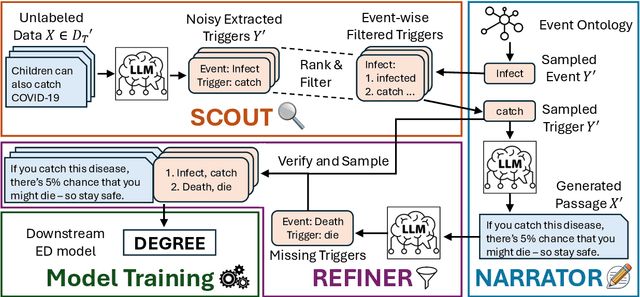
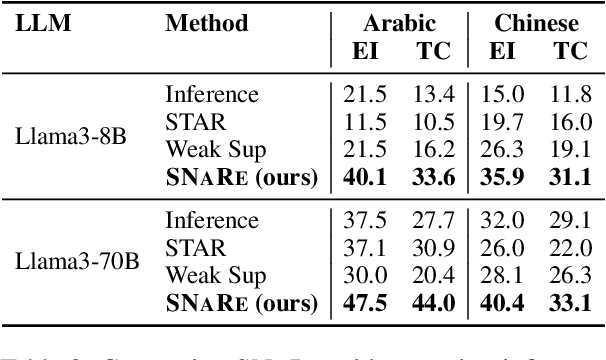
Event Detection (ED) is the task of identifying typed event mentions of interest from natural language text, which benefits domain-specific reasoning in biomedical, legal, and epidemiological domains. However, procuring supervised data for thousands of events for various domains is a laborious and expensive task. To this end, existing works have explored synthetic data generation via forward (generating labels for unlabeled sentences) and inverse (generating sentences from generated labels) generations. However, forward generation often produces noisy labels, while inverse generation struggles with domain drift and incomplete event annotations. To address these challenges, we introduce FIG, a hybrid approach that leverages inverse generation for high-quality data synthesis while anchoring it to domain-specific cues extracted via forward generation on unlabeled target data. FIG further enhances its synthetic data by adding missing annotations through forward generation-based refinement. Experimentation on three ED datasets from diverse domains reveals that FIG outperforms the best baseline achieving average gains of 3.3% F1 and 5.4% F1 in the zero-shot and few-shot settings respectively. Analyzing the generated trigger hit rate and human evaluation substantiates FIG's superior domain alignment and data quality compared to existing baselines.
CaLM: Contrasting Large and Small Language Models to Verify Grounded Generation
Jun 08, 2024Grounded generation aims to equip language models (LMs) with the ability to produce more credible and accountable responses by accurately citing verifiable sources. However, existing methods, by either feeding LMs with raw or preprocessed materials, remain prone to errors. To address this, we introduce CaLM, a novel verification framework. CaLM leverages the insight that a robust grounded response should be consistent with information derived solely from its cited sources. Our framework empowers smaller LMs, which rely less on parametric memory and excel at processing relevant information given a query, to validate the output of larger LMs. Larger LM responses that closely align with the smaller LMs' output, which relies exclusively on cited documents, are verified. Responses showing discrepancies are iteratively refined through a feedback loop. Experiments on three open-domain question-answering datasets demonstrate significant performance gains of 1.5% to 7% absolute average without any required model fine-tuning.
Argument-Aware Approach To Event Linking
Mar 22, 2024Event linking connects event mentions in text with relevant nodes in a knowledge base (KB). Prior research in event linking has mainly borrowed methods from entity linking, overlooking the distinct features of events. Compared to the extensively explored entity linking task, events have more complex structures and can be more effectively distinguished by examining their associated arguments. Moreover, the information-rich nature of events leads to the scarcity of event KBs. This emphasizes the need for event linking models to identify and classify event mentions not in the KB as ``out-of-KB,'' an area that has received limited attention. In this work, we tackle these challenges by introducing an argument-aware approach. First, we improve event linking models by augmenting input text with tagged event argument information, facilitating the recognition of key information about event mentions. Subsequently, to help the model handle ``out-of-KB'' scenarios, we synthesize out-of-KB training examples from in-KB instances through controlled manipulation of event arguments. Our experiment across two test datasets showed significant enhancements in both in-KB and out-of-KB scenarios, with a notable 22% improvement in out-of-KB evaluations.
A Reevaluation of Event Extraction: Past, Present, and Future Challenges
Nov 16, 2023



Event extraction has attracted much attention in recent years due to its potential for many applications. However, recent studies observe some evaluation challenges, suggesting that reported scores might not reflect the true performance. In this work, we first identify and discuss these evaluation challenges, including the unfair comparisons resulting from different assumptions about data or different data preprocessing steps, the incompleteness of the current evaluation framework leading to potential dataset bias or data split bias, and low reproducibility of prior studies. To address these challenges, we propose TextEE, a standardized, fair, and reproducible benchmark for event extraction. TextEE contains standardized data preprocessing scripts and splits for more than ten datasets across different domains. In addition, we aggregate and re-implement over ten event extraction approaches published in recent years and conduct a comprehensive reevaluation. Finally, we explore the capability of large language models in event extraction and discuss some future challenges. We expect TextEE will serve as a reliable benchmark for event extraction, facilitating future research in the field.
Contextual Label Projection for Cross-Lingual Structure Extraction
Sep 16, 2023Translating training data into target languages has proven beneficial for cross-lingual transfer. However, for structure extraction tasks, translating data requires a label projection step, which translates input text and obtains translated labels in the translated text jointly. Previous research in label projection mostly compromises translation quality by either facilitating easy identification of translated labels from translated text or using word-level alignment between translation pairs to assemble translated phrase-level labels from the aligned words. In this paper, we introduce CLAP, which first translates text to the target language and performs contextual translation on the labels using the translated text as the context, ensuring better accuracy for the translated labels. We leverage instruction-tuned language models with multilingual capabilities as our contextual translator, imposing the constraint of the presence of translated labels in the translated text via instructions. We compare CLAP with other label projection techniques for creating pseudo-training data in target languages on event argument extraction, a representative structure extraction task. Results show that CLAP improves by 2-2.5 F1-score over other methods on the Chinese and Arabic ACE05 datasets.
Code-Switched Text Synthesis in Unseen Language Pairs
May 26, 2023Existing efforts on text synthesis for code-switching mostly require training on code-switched texts in the target language pairs, limiting the deployment of the models to cases lacking code-switched data. In this work, we study the problem of synthesizing code-switched texts for language pairs absent from the training data. We introduce GLOSS, a model built on top of a pre-trained multilingual machine translation model (PMMTM) with an additional code-switching module. This module, either an adapter or extra prefixes, learns code-switching patterns from code-switched data during training, while the primary component of GLOSS, i.e., the PMMTM, is frozen. The design of only adjusting the code-switching module prevents our model from overfitting to the constrained training data for code-switching. Hence, GLOSS exhibits the ability to generalize and synthesize code-switched texts across a broader spectrum of language pairs. Additionally, we develop a self-training algorithm on target language pairs further to enhance the reliability of GLOSS. Automatic evaluations on four language pairs show that GLOSS achieves at least 55% relative BLEU and METEOR scores improvements compared to strong baselines. Human evaluations on two language pairs further validate the success of GLOSS.