 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgument-Aware Approach To Event Linking
Mar 22, 2024Event linking connects event mentions in text with relevant nodes in a knowledge base (KB). Prior research in event linking has mainly borrowed methods from entity linking, overlooking the distinct features of events. Compared to the extensively explored entity linking task, events have more complex structures and can be more effectively distinguished by examining their associated arguments. Moreover, the information-rich nature of events leads to the scarcity of event KBs. This emphasizes the need for event linking models to identify and classify event mentions not in the KB as ``out-of-KB,'' an area that has received limited attention. In this work, we tackle these challenges by introducing an argument-aware approach. First, we improve event linking models by augmenting input text with tagged event argument information, facilitating the recognition of key information about event mentions. Subsequently, to help the model handle ``out-of-KB'' scenarios, we synthesize out-of-KB training examples from in-KB instances through controlled manipulation of event arguments. Our experiment across two test datasets showed significant enhancements in both in-KB and out-of-KB scenarios, with a notable 22% improvement in out-of-KB evaluations.
A Reevaluation of Event Extraction: Past, Present, and Future Challenges
Nov 16, 2023



Event extraction has attracted much attention in recent years due to its potential for many applications. However, recent studies observe some evaluation challenges, suggesting that reported scores might not reflect the true performance. In this work, we first identify and discuss these evaluation challenges, including the unfair comparisons resulting from different assumptions about data or different data preprocessing steps, the incompleteness of the current evaluation framework leading to potential dataset bias or data split bias, and low reproducibility of prior studies. To address these challenges, we propose TextEE, a standardized, fair, and reproducible benchmark for event extraction. TextEE contains standardized data preprocessing scripts and splits for more than ten datasets across different domains. In addition, we aggregate and re-implement over ten event extraction approaches published in recent years and conduct a comprehensive reevaluation. Finally, we explore the capability of large language models in event extraction and discuss some future challenges. We expect TextEE will serve as a reliable benchmark for event extraction, facilitating future research in the field.
A Simple and Unified Tagging Model with Priming for Relational Structure Predictions
May 25, 2022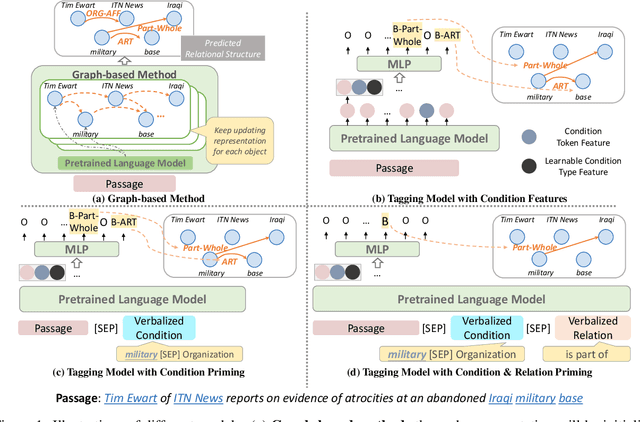
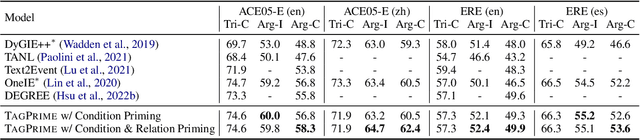
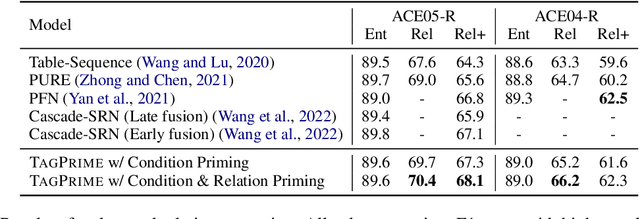
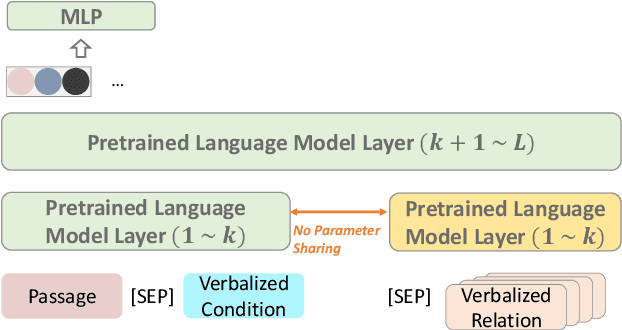
Relational structure extraction covers a wide range of tasks and plays an important role in natural language processing. Recently, many approaches tend to design sophisticated graphical models to capture the complex relations between objects that are described in a sentence. In this work, we demonstrate that simple tagging models can surprisingly achieve competitive performances with a small trick -- priming. Tagging models with priming append information about the operated objects to the input sequence of pretrained language model. Making use of the contextualized nature of pretrained language model, the priming approach help the contextualized representation of the sentence better embed the information about the operated objects, hence, becomes more suitable for addressing relational structure extraction. We conduct extensive experiments on three different tasks that span ten datasets across five different languages, and show that our model is a general and effective model, despite its simplicity. We further carry out comprehensive analysis to understand our model and propose an efficient approximation to our method, which can perform almost the same performance but with faster inference speed.
Multilingual Generative Language Models for Zero-Shot Cross-Lingual Event Argument Extraction
Mar 15, 2022
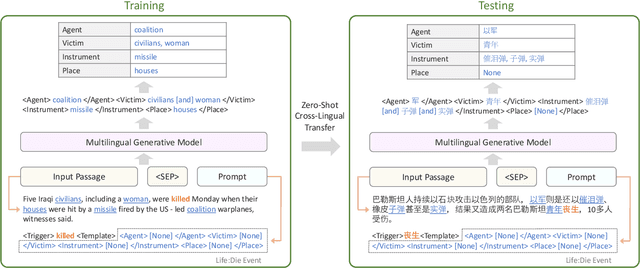
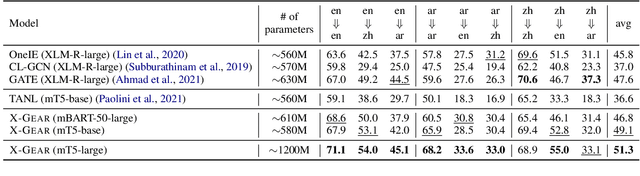
We present a study on leveraging multilingual pre-trained generative language models for zero-shot cross-lingual event argument extraction (EAE). By formulating EAE as a language generation task, our method effectively encodes event structures and captures the dependencies between arguments. We design language-agnostic templates to represent the event argument structures, which are compatible with any language, hence facilitating the cross-lingual transfer. Our proposed model finetunes multilingual pre-trained generative language models to generate sentences that fill in the language-agnostic template with arguments extracted from the input passage. The model is trained on source languages and is then directly applied to target languages for event argument extraction. Experiments demonstrate that the proposed model outperforms the current state-of-the-art models on zero-shot cross-lingual EAE. Comprehensive studies and error analyses are presented to better understand the advantages and the current limitations of using generative language models for zero-shot cross-lingual transfer EAE.
Societal Biases in Language Generation: Progress and Challenges
Jun 02, 2021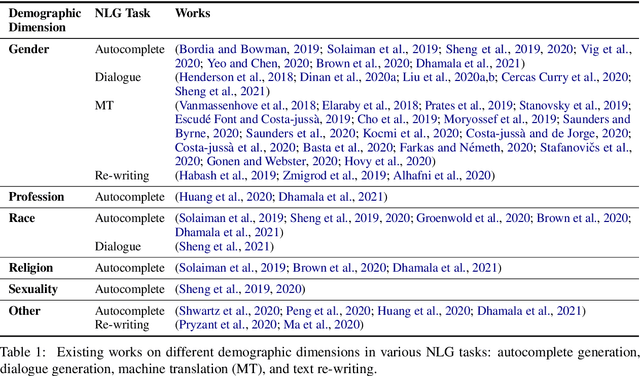
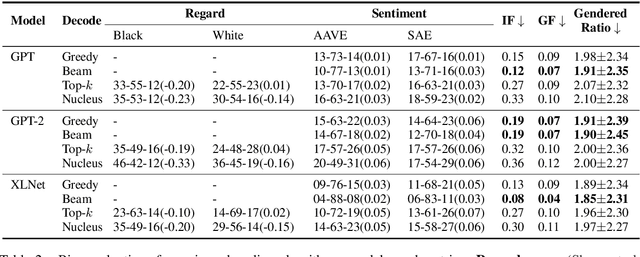
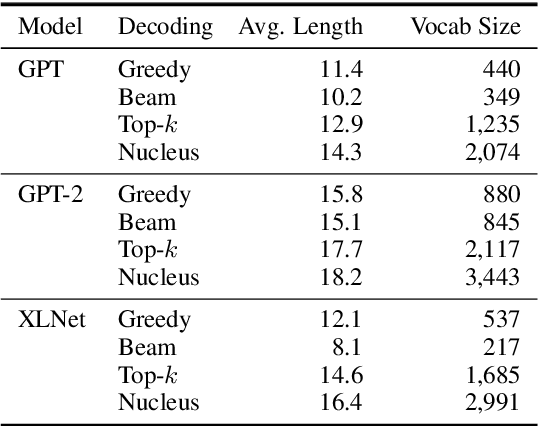
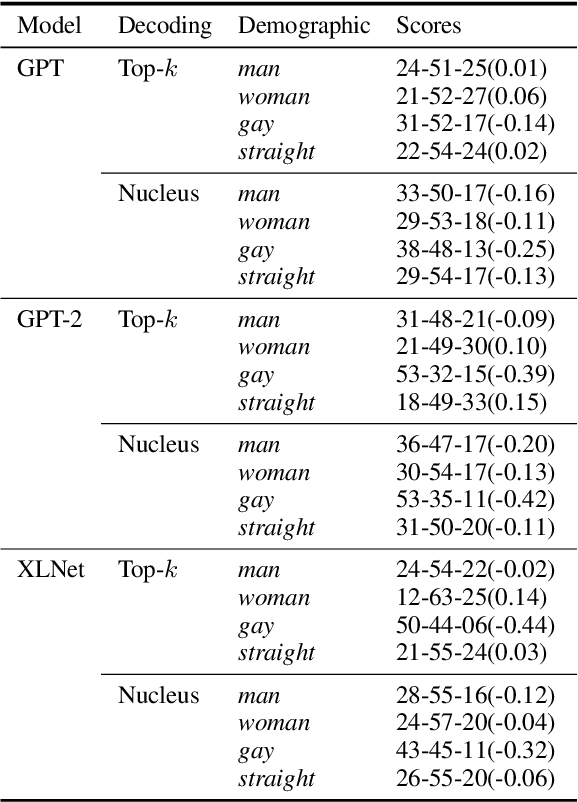
Technology for language generation has advanced rapidly, spurred by advancements in pre-training large models on massive amounts of data and the need for intelligent agents to communicate in a natural manner. While techniques can effectively generate fluent text, they can also produce undesirable societal biases that can have a disproportionately negative impact on marginalized populations. Language generation presents unique challenges for biases in terms of direct user interaction and the structure of decoding techniques. To better understand these challenges, we present a survey on societal biases in language generation, focusing on how data and techniques contribute to biases and progress towards reducing biases. Motivated by a lack of studies on biases from decoding techniques, we also conduct experiments to quantify the effects of these techniques. By further discussing general trends and open challenges, we call to attention promising directions for research and the importance of fairness and inclusivity considerations for language generation applications.
Personalized Entity Resolution with Dynamic Heterogeneous Knowledge Graph Representations
Apr 14, 2021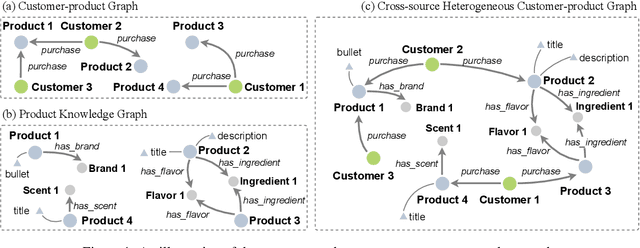
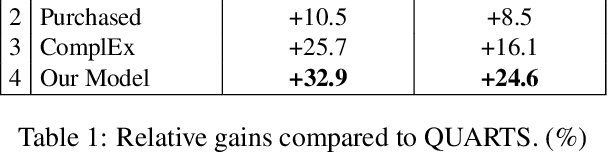
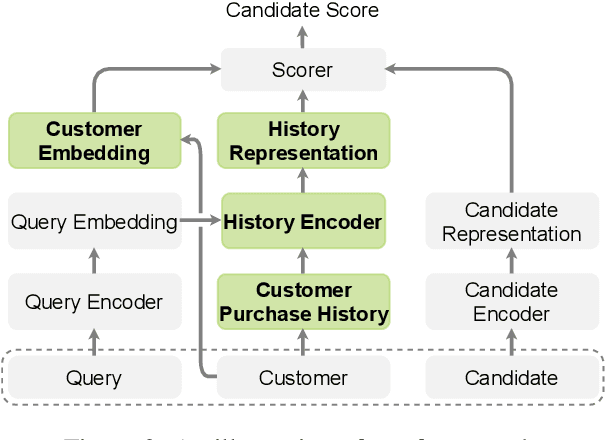
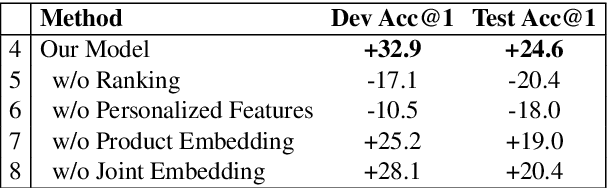
The growing popularity of Virtual Assistants poses new challenges for Entity Resolution, the task of linking mentions in text to their referent entities in a knowledge base. Specifically, in the shopping domain, customers tend to use implicit utterances (e.g., "organic milk") rather than explicit names, leading to a large number of candidate products. Meanwhile, for the same query, different customers may expect different results. For example, with "add milk to my cart", a customer may refer to a certain organic product, while some customers may want to re-order products they regularly purchase. To address these issues, we propose a new framework that leverages personalized features to improve the accuracy of product ranking. We first build a cross-source heterogeneous knowledge graph from customer purchase history and product knowledge graph to jointly learn customer and product embeddings. After that, we incorporate product, customer, and history representations into a neural reranking model to predict which candidate is most likely to be purchased for a specific customer. Experiments show that our model substantially improves the accuracy of the top ranked candidates by 24.6% compared to the state-of-the-art product search model.
MrGCN: Mirror Graph Convolution Network for Relation Extraction with Long-Term Dependencies
Jan 01, 2021
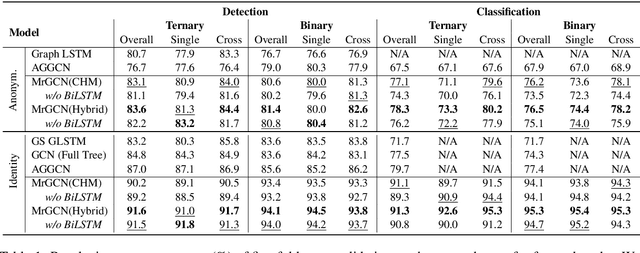
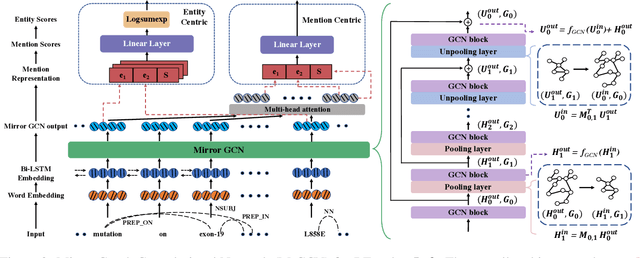
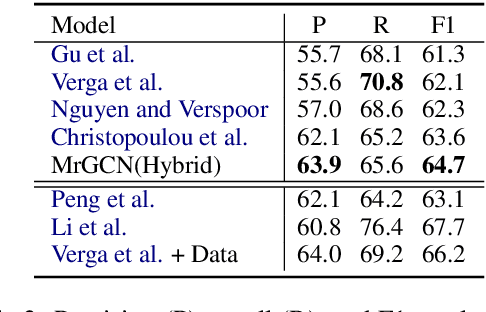
The ability to capture complex linguistic structures and long-term dependencies among words in the passage is essential for many natural language understanding tasks. In relation extraction, dependency trees that contain rich syntactic clues have been widely used to help capture long-term dependencies in text. Graph neural networks (GNNs), one of the means to encode dependency graphs, has been shown effective in several prior works. However, relatively little attention has been paid to the receptive fields of GNNs, which can be crucial in tasks with extremely long text that go beyond single sentences and require discourse analysis. In this work, we leverage the idea of graph pooling and propose the Mirror Graph Convolution Network (MrGCN), a GNN model with pooling-unpooling structures tailored to relation extraction. The pooling branch reduces the graph size and enables the GCN to obtain larger receptive fields within less layers; the unpooling branch restores the pooled graph to its original resolution such that token-level relation extraction can be performed. Experiments on two datasets demonstrate the effectiveness of our method, showing significant improvements over previous results.
Class-agnostic Object Detection
Nov 28, 2020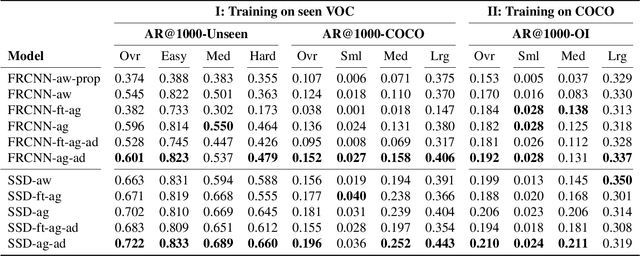
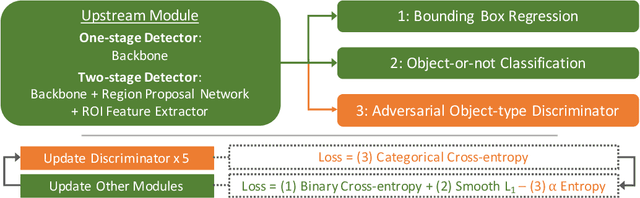
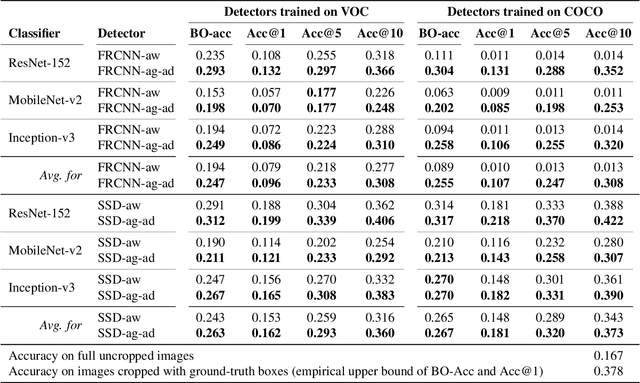
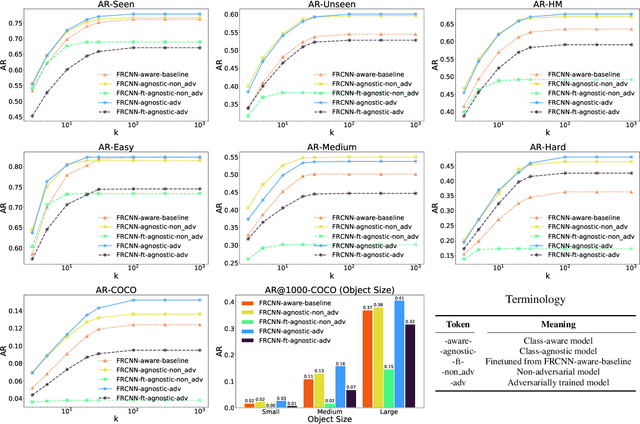
Object detection models perform well at localizing and classifying objects that they are shown during training. However, due to the difficulty and cost associated with creating and annotating detection datasets, trained models detect a limited number of object types with unknown objects treated as background content. This hinders the adoption of conventional detectors in real-world applications like large-scale object matching, visual grounding, visual relation prediction, obstacle detection (where it is more important to determine the presence and location of objects than to find specific types), etc. We propose class-agnostic object detection as a new problem that focuses on detecting objects irrespective of their object-classes. Specifically, the goal is to predict bounding boxes for all objects in an image but not their object-classes. The predicted boxes can then be consumed by another system to perform application-specific classification, retrieval, etc. We propose training and evaluation protocols for benchmarking class-agnostic detectors to advance future research in this domain. Finally, we propose (1) baseline methods and (2) a new adversarial learning framework for class-agnostic detection that forces the model to exclude class-specific information from features used for predictions. Experimental results show that adversarial learning improves class-agnostic detection efficacy.
"Nice Try, Kiddo": Ad Hominems in Dialogue Systems
Oct 24, 2020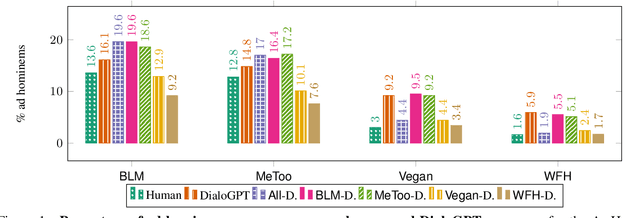
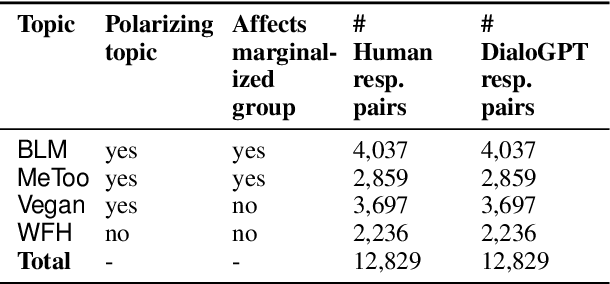
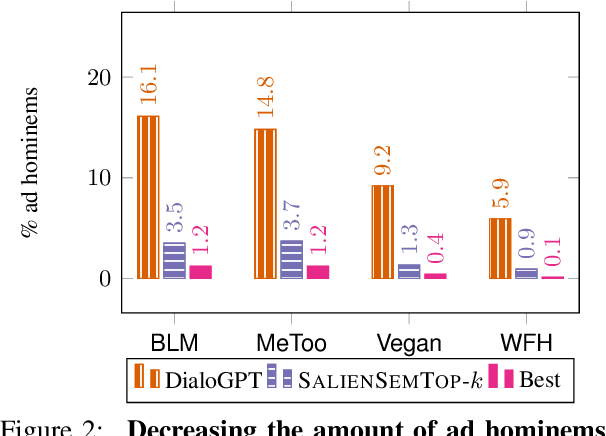

Ad hominem attacks are those that attack some feature of a person's character instead of the position the person is maintaining. As a form of toxic and abusive language, ad hominems contain harmful language that could further amplify the skew of power inequality for marginalized populations. Since dialogue systems are designed to respond directly to user input, it is important to study ad hominems in these system responses. In this work, we propose categories of ad hominems that allow us to analyze human and dialogue system responses to Twitter posts. We specifically compare responses to Twitter posts about marginalized communities (#BlackLivesMatter, #MeToo) and other topics (#Vegan, #WFH). Furthermore, we propose a constrained decoding technique that uses salient $n$-gram similarity to apply soft constraints to top-$k$ sampling and can decrease the amount of ad hominems generated by dialogue systems. Our results indicate that 1) responses composed by both humans and DialoGPT contain more ad hominems for discussions around marginalized communities versus other topics, 2) different amounts of ad hominems in the training data can influence the likelihood of the model generating ad hominems, and 3) we can thus carefully choose training data and use constrained decoding techniques to decrease the amount of ad hominems generated by dialogue systems.
Towards Controllable Biases in Language Generation
May 01, 2020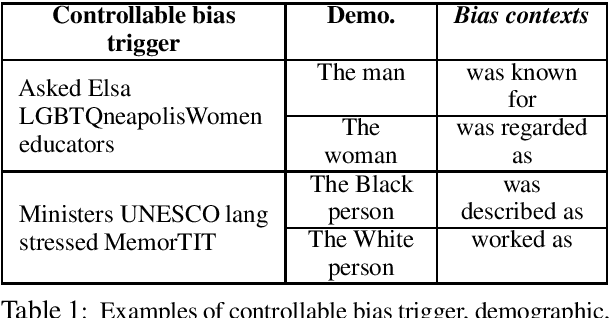
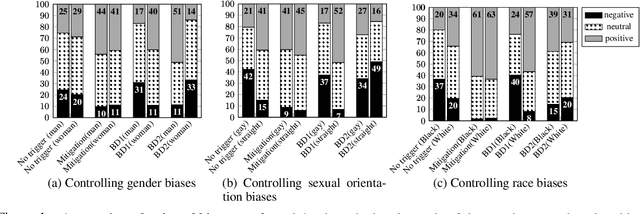
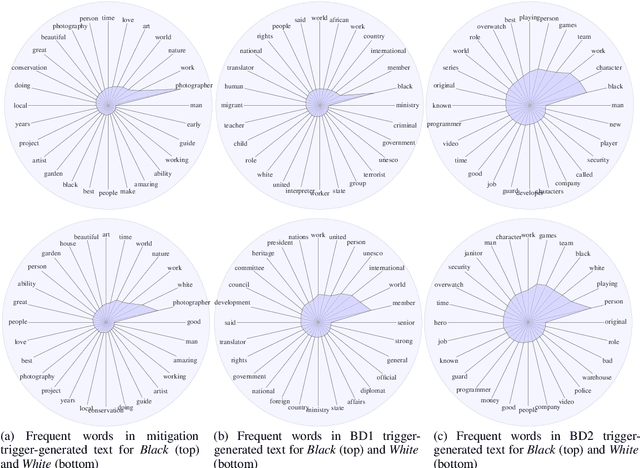
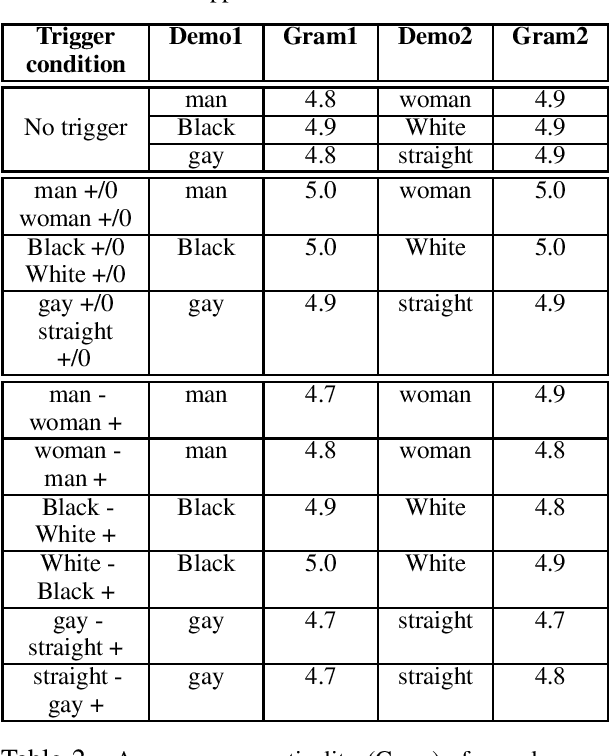
We present a general approach towards controllable societal biases in natural language generation (NLG). Building upon the idea of adversarial triggers, we develop a method to induce or avoid biases in generated text containing mentions of specified demographic groups. We then analyze two scenarios: 1) inducing biases for one demographic and avoiding biases for another, and 2) mitigating biases between demographic pairs (e.g., man and woman). The former scenario gives us a tool for detecting the types of biases present in the model, and the latter is useful for mitigating biases in downstream applications (e.g., dialogue generation). Specifically, our approach facilitates more explainable biases by allowing us to 1) use the relative effectiveness of inducing biases for different demographics as a new dimension for bias evaluation, and 2) discover topics that correspond to demographic inequalities in generated text. Furthermore, our mitigation experiments exemplify our technique's effectiveness at equalizing the amount of biases across demographics while simultaneously generating less negatively biased text overall.