 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Holistic Approach for Detecting Human Image Forgery
Jan 08, 2026The rapid advancement of AI-generated content (AIGC) has escalated the threat of deepfakes, from facial manipulations to the synthesis of entire photorealistic human bodies. However, existing detection methods remain fragmented, specializing either in facial-region forgeries or full-body synthetic images, and consequently fail to generalize across the full spectrum of human image manipulations. We introduce HuForDet, a holistic framework for human image forgery detection, which features a dual-branch architecture comprising: (1) a face forgery detection branch that employs heterogeneous experts operating in both RGB and frequency domains, including an adaptive Laplacian-of-Gaussian (LoG) module designed to capture artifacts ranging from fine-grained blending boundaries to coarse-scale texture irregularities; and (2) a contextualized forgery detection branch that leverages a Multi-Modal Large Language Model (MLLM) to analyze full-body semantic consistency, enhanced with a confidence estimation mechanism that dynamically weights its contribution during feature fusion. We curate a human image forgery (HuFor) dataset that unifies existing face forgery data with a new corpus of full-body synthetic humans. Extensive experiments show that our HuForDet achieves state-of-the-art forgery detection performance and superior robustness across diverse human image forgeries.
TalkingHeadBench: A Multi-Modal Benchmark & Analysis of Talking-Head DeepFake Detection
May 30, 2025The rapid advancement of talking-head deepfake generation fueled by advanced generative models has elevated the realism of synthetic videos to a level that poses substantial risks in domains such as media, politics, and finance. However, current benchmarks for deepfake talking-head detection fail to reflect this progress, relying on outdated generators and offering limited insight into model robustness and generalization. We introduce TalkingHeadBench, a comprehensive multi-model multi-generator benchmark and curated dataset designed to evaluate the performance of state-of-the-art detectors on the most advanced generators. Our dataset includes deepfakes synthesized by leading academic and commercial models and features carefully constructed protocols to assess generalization under distribution shifts in identity and generator characteristics. We benchmark a diverse set of existing detection methods, including CNNs, vision transformers, and temporal models, and analyze their robustness and generalization capabilities. In addition, we provide error analysis using Grad-CAM visualizations to expose common failure modes and detector biases. TalkingHeadBench is hosted on https://huggingface.co/datasets/luchaoqi/TalkingHeadBench with open access to all data splits and protocols. Our benchmark aims to accelerate research towards more robust and generalizable detection models in the face of rapidly evolving generative techniques.
Benchmarking Unified Face Attack Detection via Hierarchical Prompt Tuning
May 19, 2025Presentation Attack Detection and Face Forgery Detection are designed to protect face data from physical media-based Presentation Attacks and digital editing-based DeepFakes respectively. But separate training of these two models makes them vulnerable to unknown attacks and burdens deployment environments. The lack of a Unified Face Attack Detection model to handle both types of attacks is mainly due to two factors. First, there's a lack of adequate benchmarks for models to explore. Existing UAD datasets have limited attack types and samples, restricting the model's ability to address advanced threats. To address this, we propose UniAttackDataPlus (UniAttackData+), the most extensive and sophisticated collection of forgery techniques to date. It includes 2,875 identities and their 54 kinds of falsified samples, totaling 697,347 videos. Second, there's a lack of a reliable classification criterion. Current methods try to find an arbitrary criterion within the same semantic space, which fails when encountering diverse attacks. So, we present a novel Visual-Language Model-based Hierarchical Prompt Tuning Framework (HiPTune) that adaptively explores multiple classification criteria from different semantic spaces. We build a Visual Prompt Tree to explore various classification rules hierarchically. Then, by adaptively pruning the prompts, the model can select the most suitable prompts to guide the encoder to extract discriminative features at different levels in a coarse-to-fine way. Finally, to help the model understand the classification criteria in visual space, we propose a Dynamically Prompt Integration module to project the visual prompts to the text encoder for more accurate semantics. Experiments on 12 datasets have shown the potential to inspire further innovations in the UAD field.
Rethinking Vision-Language Model in Face Forensics: Multi-Modal Interpretable Forged Face Detector
Mar 26, 2025Deepfake detection is a long-established research topic vital for mitigating the spread of malicious misinformation. Unlike prior methods that provide either binary classification results or textual explanations separately, we introduce a novel method capable of generating both simultaneously. Our method harnesses the multi-modal learning capability of the pre-trained CLIP and the unprecedented interpretability of large language models (LLMs) to enhance both the generalization and explainability of deepfake detection. Specifically, we introduce a multi-modal face forgery detector (M2F2-Det) that employs tailored face forgery prompt learning, incorporating the pre-trained CLIP to improve generalization to unseen forgeries. Also, M2F2-Det incorporates an LLM to provide detailed textual explanations of its detection decisions, enhancing interpretability by bridging the gap between natural language and subtle cues of facial forgeries. Empirically, we evaluate M2F2-Det on both detection and explanation generation tasks, where it achieves state-of-the-art performance, demonstrating its effectiveness in identifying and explaining diverse forgeries.
FrustumFusionNets: A Three-Dimensional Object Detection Network Based on Tractor Road Scene
Mar 18, 2025To address the issues of the existing frustum-based methods' underutilization of image information in road three-dimensional object detection as well as the lack of research on agricultural scenes, we constructed an object detection dataset using an 80-line Light Detection And Ranging (LiDAR) and a camera in a complex tractor road scene and proposed a new network called FrustumFusionNets (FFNets). Initially, we utilize the results of image-based two-dimensional object detection to narrow down the search region in the three-dimensional space of the point cloud. Next, we introduce a Gaussian mask to enhance the point cloud information. Then, we extract the features from the frustum point cloud and the crop image using the point cloud feature extraction pipeline and the image feature extraction pipeline, respectively. Finally, we concatenate and fuse the data features from both modalities to achieve three-dimensional object detection. Experiments demonstrate that on the constructed test set of tractor road data, the FrustumFusionNetv2 achieves 82.28% and 95.68% accuracy in the three-dimensional object detection of the two main road objects, cars and people, respectively. This performance is 1.83% and 2.33% better than the original model. It offers a hybrid fusion-based multi-object, high-precision, real-time three-dimensional object detection technique for unmanned agricultural machines in tractor road scenarios. On the Karlsruhe Institute of Technology and Toyota Technological Institute (KITTI) Benchmark Suite validation set, the FrustumFusionNetv2 also demonstrates significant superiority in detecting road pedestrian objects compared with other frustum-based three-dimensional object detection methods.
Dense-Face: Personalized Face Generation Model via Dense Annotation Prediction
Dec 24, 2024The text-to-image (T2I) personalization diffusion model can generate images of the novel concept based on the user input text caption. However, existing T2I personalized methods either require test-time fine-tuning or fail to generate images that align well with the given text caption. In this work, we propose a new T2I personalization diffusion model, Dense-Face, which can generate face images with a consistent identity as the given reference subject and align well with the text caption. Specifically, we introduce a pose-controllable adapter for the high-fidelity image generation while maintaining the text-based editing ability of the pre-trained stable diffusion (SD). Additionally, we use internal features of the SD UNet to predict dense face annotations, enabling the proposed method to gain domain knowledge in face generation. Empirically, our method achieves state-of-the-art or competitive generation performance in image-text alignment, identity preservation, and pose control.
Language-guided Hierarchical Fine-grained Image Forgery Detection and Localization
Oct 31, 2024Differences in forgery attributes of images generated in CNN-synthesized and image-editing domains are large, and such differences make a unified image forgery detection and localization (IFDL) challenging. To this end, we present a hierarchical fine-grained formulation for IFDL representation learning. Specifically, we first represent forgery attributes of a manipulated image with multiple labels at different levels. Then, we perform fine-grained classification at these levels using the hierarchical dependency between them. As a result, the algorithm is encouraged to learn both comprehensive features and the inherent hierarchical nature of different forgery attributes. In this work, we propose a Language-guided Hierarchical Fine-grained IFDL, denoted as HiFi-Net++. Specifically, HiFi-Net++ contains four components: a multi-branch feature extractor, a language-guided forgery localization enhancer, as well as classification and localization modules. Each branch of the multi-branch feature extractor learns to classify forgery attributes at one level, while localization and classification modules segment pixel-level forgery regions and detect image-level forgery, respectively. Also, the language-guided forgery localization enhancer (LFLE), containing image and text encoders learned by contrastive language-image pre-training (CLIP), is used to further enrich the IFDL representation. LFLE takes specifically designed texts and the given image as multi-modal inputs and then generates the visual embedding and manipulation score maps, which are used to further improve HiFi-Net++ manipulation localization performance. Lastly, we construct a hierarchical fine-grained dataset to facilitate our study. We demonstrate the effectiveness of our method on $8$ by using different benchmarks for both tasks of IFDL and forgery attribute classification. Our source code and dataset are available.
On Learning Multi-Modal Forgery Representation for Diffusion Generated Video Detection
Oct 31, 2024Large numbers of synthesized videos from diffusion models pose threats to information security and authenticity, leading to an increasing demand for generated content detection. However, existing video-level detection algorithms primarily focus on detecting facial forgeries and often fail to identify diffusion-generated content with a diverse range of semantics. To advance the field of video forensics, we propose an innovative algorithm named Multi-Modal Detection(MM-Det) for detecting diffusion-generated videos. MM-Det utilizes the profound perceptual and comprehensive abilities of Large Multi-modal Models (LMMs) by generating a Multi-Modal Forgery Representation (MMFR) from LMM's multi-modal space, enhancing its ability to detect unseen forgery content. Besides, MM-Det leverages an In-and-Across Frame Attention (IAFA) mechanism for feature augmentation in the spatio-temporal domain. A dynamic fusion strategy helps refine forgery representations for the fusion. Moreover, we construct a comprehensive diffusion video dataset, called Diffusion Video Forensics (DVF), across a wide range of forgery videos. MM-Det achieves state-of-the-art performance in DVF, demonstrating the effectiveness of our algorithm. Both source code and DVF are available at https://github.com/SparkleXFantasy/MM-Det.
Towards Effective User Attribution for Latent Diffusion Models via Watermark-Informed Blending
Sep 17, 2024



Rapid advancements in multimodal large language models have enabled the creation of hyper-realistic images from textual descriptions. However, these advancements also raise significant concerns about unauthorized use, which hinders their broader distribution. Traditional watermarking methods often require complex integration or degrade image quality. To address these challenges, we introduce a novel framework Towards Effective user Attribution for latent diffusion models via Watermark-Informed Blending (TEAWIB). TEAWIB incorporates a unique ready-to-use configuration approach that allows seamless integration of user-specific watermarks into generative models. This approach ensures that each user can directly apply a pre-configured set of parameters to the model without altering the original model parameters or compromising image quality. Additionally, noise and augmentation operations are embedded at the pixel level to further secure and stabilize watermarked images. Extensive experiments validate the effectiveness of TEAWIB, showcasing the state-of-the-art performance in perceptual quality and attribution accuracy.
Tracing Hyperparameter Dependencies for Model Parsing via Learnable Graph Pooling Network
Dec 03, 2023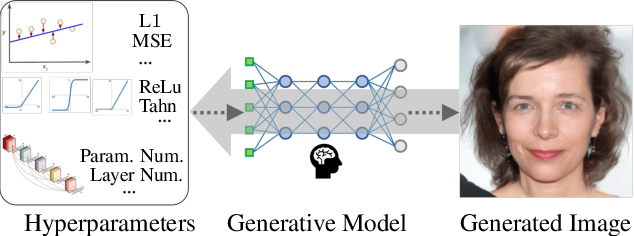



Model Parsing defines the research task of predicting hyperparameters of the generative model (GM), given a generated image as input. Since a diverse set of hyperparameters is jointly employed by the generative model, and dependencies often exist among them, it is crucial to learn these hyperparameter dependencies for the improved model parsing performance. To explore such important dependencies, we propose a novel model parsing method called Learnable Graph Pooling Network (LGPN). Specifically, we transform model parsing into a graph node classification task, using graph nodes and edges to represent hyperparameters and their dependencies, respectively. Furthermore, LGPN incorporates a learnable pooling-unpooling mechanism tailored to model parsing, which adaptively learns hyperparameter dependencies of GMs used to generate the input image. We also extend our proposed method to CNN-generated image detection and coordinate attacks detection. Empirically, we achieve state-of-the-art results in model parsing and its extended applications, showing the effectiveness of our method. Our source code are available.