 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Unified Face Attack Detection via Hierarchical Prompt Tuning
May 19, 2025Presentation Attack Detection and Face Forgery Detection are designed to protect face data from physical media-based Presentation Attacks and digital editing-based DeepFakes respectively. But separate training of these two models makes them vulnerable to unknown attacks and burdens deployment environments. The lack of a Unified Face Attack Detection model to handle both types of attacks is mainly due to two factors. First, there's a lack of adequate benchmarks for models to explore. Existing UAD datasets have limited attack types and samples, restricting the model's ability to address advanced threats. To address this, we propose UniAttackDataPlus (UniAttackData+), the most extensive and sophisticated collection of forgery techniques to date. It includes 2,875 identities and their 54 kinds of falsified samples, totaling 697,347 videos. Second, there's a lack of a reliable classification criterion. Current methods try to find an arbitrary criterion within the same semantic space, which fails when encountering diverse attacks. So, we present a novel Visual-Language Model-based Hierarchical Prompt Tuning Framework (HiPTune) that adaptively explores multiple classification criteria from different semantic spaces. We build a Visual Prompt Tree to explore various classification rules hierarchically. Then, by adaptively pruning the prompts, the model can select the most suitable prompts to guide the encoder to extract discriminative features at different levels in a coarse-to-fine way. Finally, to help the model understand the classification criteria in visual space, we propose a Dynamically Prompt Integration module to project the visual prompts to the text encoder for more accurate semantics. Experiments on 12 datasets have shown the potential to inspire further innovations in the UAD field.
Mixture-of-Noises Enhanced Forgery-Aware Predictor for Multi-Face Manipulation Detection and Localization
Aug 05, 2024



With the advancement of face manipulation technology, forgery images in multi-face scenarios are gradually becoming a more complex and realistic challenge. Despite this, detection and localization methods for such multi-face manipulations remain underdeveloped. Traditional manipulation localization methods either indirectly derive detection results from localization masks, resulting in limited detection performance, or employ a naive two-branch structure to simultaneously obtain detection and localization results, which cannot effectively benefit the localization capability due to limited interaction between two tasks. This paper proposes a new framework, namely MoNFAP, specifically tailored for multi-face manipulation detection and localization. The MoNFAP primarily introduces two novel modules: the Forgery-aware Unified Predictor (FUP) Module and the Mixture-of-Noises Module (MNM). The FUP integrates detection and localization tasks using a token learning strategy and multiple forgery-aware transformers, which facilitates the use of classification information to enhance localization capability. Besides, motivated by the crucial role of noise information in forgery detection, the MNM leverages multiple noise extractors based on the concept of the mixture of experts to enhance the general RGB features, further boosting the performance of our framework. Finally, we establish a comprehensive benchmark for multi-face detection and localization and the proposed \textit{MoNFAP} achieves significant performance. The codes will be made available.
Exploiting Modality-Specific Features For Multi-Modal Manipulation Detection And Grounding
Sep 22, 2023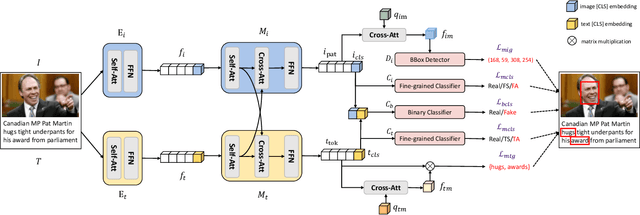
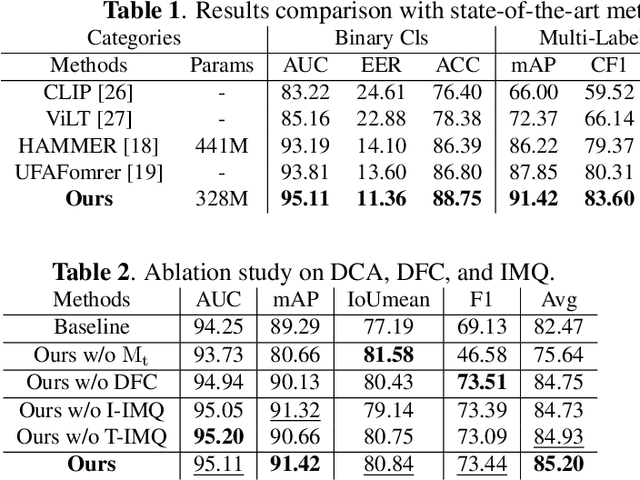

AI-synthesized text and images have gained significant attention, particularly due to the widespread dissemination of multi-modal manipulations on the internet, which has resulted in numerous negative impacts on society. Existing methods for multi-modal manipulation detection and grounding primarily focus on fusing vision-language features to make predictions, while overlooking the importance of modality-specific features, leading to sub-optimal results. In this paper, we construct a simple and novel transformer-based framework for multi-modal manipulation detection and grounding tasks. Our framework simultaneously explores modality-specific features while preserving the capability for multi-modal alignment. To achieve this, we introduce visual/language pre-trained encoders and dual-branch cross-attention (DCA) to extract and fuse modality-unique features. Furthermore, we design decoupled fine-grained classifiers (DFC) to enhance modality-specific feature mining and mitigate modality competition. Moreover, we propose an implicit manipulation query (IMQ) that adaptively aggregates global contextual cues within each modality using learnable queries, thereby improving the discovery of forged details. Extensive experiments on the $\rm DGM^4$ dataset demonstrate the superior performance of our proposed model compared to state-of-the-art approaches.
Multi-spectral Class Center Network for Face Manipulation Detection and Localization
May 18, 2023As Deepfake contents continue to proliferate on the internet, advancing face manipulation forensics has become a pressing issue. To combat this emerging threat, previous methods mainly focus on studying how to distinguish authentic and manipulated face images. Despite impressive, image-level classification lacks explainability and is limited to some specific application scenarios. Existing forgery localization methods suffer from imprecise and inconsistent pixel-level annotations. To alleviate these problems, this paper first re-constructs the FaceForensics++ dataset by introducing pixel-level annotations, then builds an extensive benchmark for localizing tampered regions. Next, a novel Multi-Spectral Class Center Network (MSCCNet) is proposed for face manipulation detection and localization. Specifically, inspired by the power of frequency-related forgery traces, we design Multi-Spectral Class Center (MSCC) module to learn more generalizable and semantic-agnostic features. Based on the features of different frequency bands, the MSCC module collects multispectral class centers and computes pixel-to-class relations. Applying multi-spectral class-level representations suppresses the semantic information of the visual concepts, which is insensitive to manipulations. Furthermore, we propose a Multi-level Features Aggregation (MFA) module to employ more low-level forgery artifacts and structure textures. Experimental results quantitatively and qualitatively indicate the effectiveness and superiority of the proposed MSCCNet on comprehensive localization benchmarks. We expect this work to inspire more studies on pixel-level face manipulation localization. The annotations and code will be available.
UIA-ViT: Unsupervised Inconsistency-Aware Method based on Vision Transformer for Face Forgery Detection
Oct 23, 2022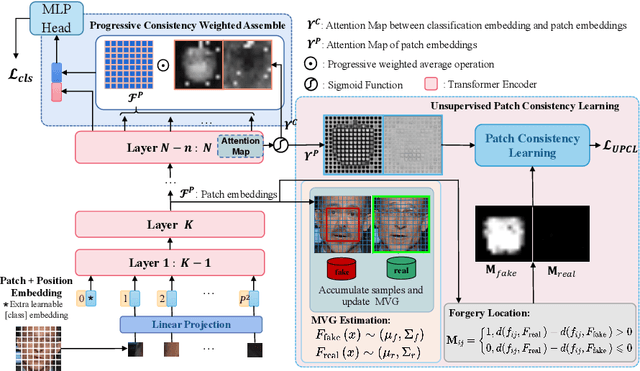


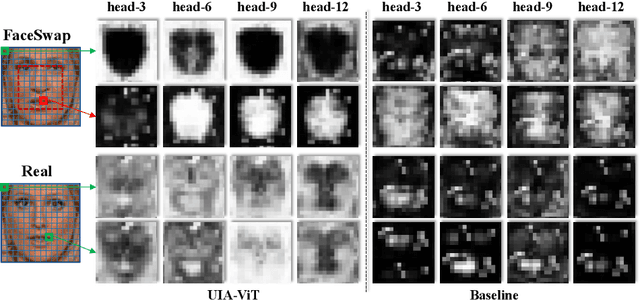
Intra-frame inconsistency has been proved to be effective for the generalization of face forgery detection. However, learning to focus on these inconsistency requires extra pixel-level forged location annotations. Acquiring such annotations is non-trivial. Some existing methods generate large-scale synthesized data with location annotations, which is only composed of real images and cannot capture the properties of forgery regions. Others generate forgery location labels by subtracting paired real and fake images, yet such paired data is difficult to collected and the generated label is usually discontinuous. To overcome these limitations, we propose a novel Unsupervised Inconsistency-Aware method based on Vision Transformer, called UIA-ViT, which only makes use of video-level labels and can learn inconsistency-aware feature without pixel-level annotations. Due to the self-attention mechanism, the attention map among patch embeddings naturally represents the consistency relation, making the vision Transformer suitable for the consistency representation learning. Based on vision Transformer, we propose two key components: Unsupervised Patch Consistency Learning (UPCL) and Progressive Consistency Weighted Assemble (PCWA). UPCL is designed for learning the consistency-related representation with progressive optimized pseudo annotations. PCWA enhances the final classification embedding with previous patch embeddings optimized by UPCL to further improve the detection performance. Extensive experiments demonstrate the effectiveness of the proposed method.
Towards Intrinsic Common Discriminative Features Learning for Face Forgery Detection using Adversarial Learning
Jul 08, 2022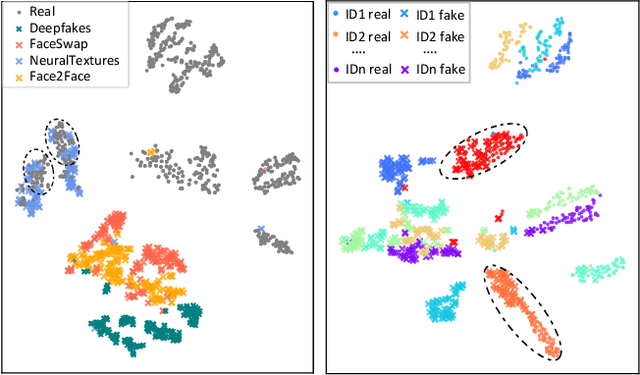


Existing face forgery detection methods usually treat face forgery detection as a binary classification problem and adopt deep convolution neural networks to learn discriminative features. The ideal discriminative features should be only related to the real/fake labels of facial images. However, we observe that the features learned by vanilla classification networks are correlated to unnecessary properties, such as forgery methods and facial identities. Such phenomenon would limit forgery detection performance especially for the generalization ability. Motivated by this, we propose a novel method which utilizes adversarial learning to eliminate the negative effect of different forgery methods and facial identities, which helps classification network to learn intrinsic common discriminative features for face forgery detection. To leverage data lacking ground truth label of facial identities, we design a special identity discriminator based on similarity information derived from off-the-shelf face recognition model. With the help of adversarial learning, our face forgery detection model learns to extract common discriminative features through eliminating the effect of forgery methods and facial identities. Extensive experiments demonstrate the effectiveness of the proposed method under both intra-dataset and cross-dataset evaluation settings.
DFGC 2021: A DeepFake Game Competition
Jun 02, 2021



This paper presents a summary of the DFGC 2021 competition. DeepFake technology is developing fast, and realistic face-swaps are increasingly deceiving and hard to detect. At the same time, DeepFake detection methods are also improving. There is a two-party game between DeepFake creators and detectors. This competition provides a common platform for benchmarking the adversarial game between current state-of-the-art DeepFake creation and detection methods. In this paper, we present the organization, results and top solutions of this competition and also share our insights obtained during this event. We also release the DFGC-21 testing dataset collected from our participants to further benefit the research community.
Towards Generalizable and Robust Face Manipulation Detection via Bag-of-local-feature
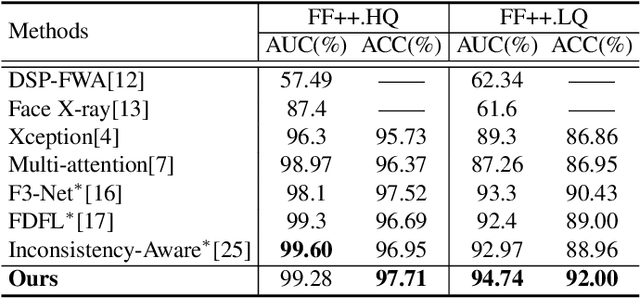
Mar 14, 2021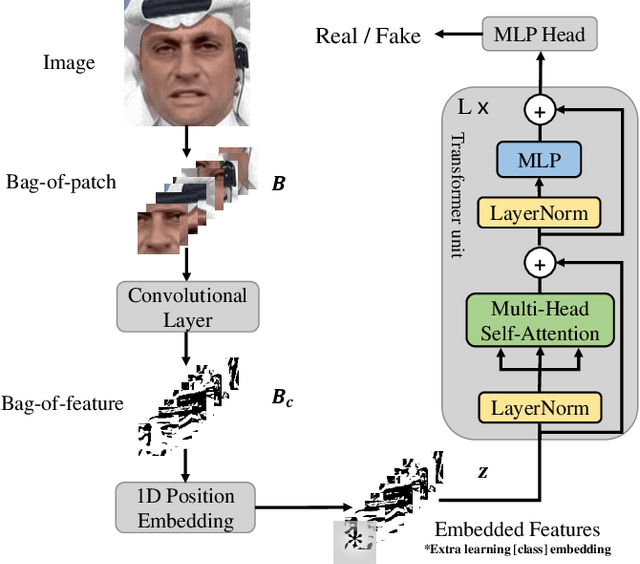
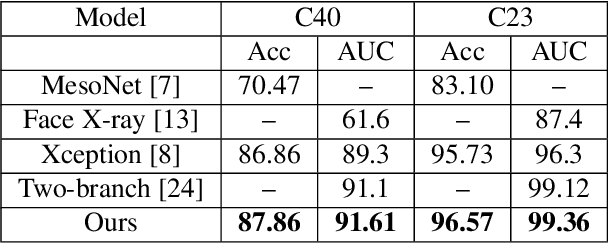

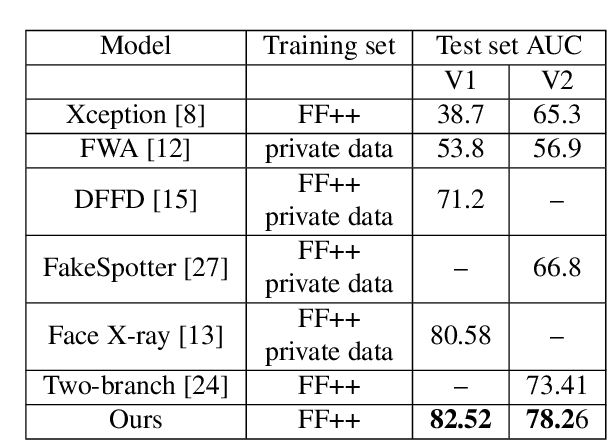
Over the past several years, in order to solve the problem of malicious abuse of facial manipulation technology, face manipulation detection technology has obtained considerable attention and achieved remarkable progress. However, most existing methods have very impoverished generalization ability and robustness. In this paper, we propose a novel method for face manipulation detection, which can improve the generalization ability and robustness by bag-of-local-feature. Specifically, we extend Transformers using bag-of-feature approach to encode inter-patch relationships, allowing it to learn local forgery features without any explicit supervision. Extensive experiments demonstrate that our method can outperform competing state-of-the-art methods on FaceForensics++, Celeb-DF and DeeperForensics-1.0 datasets.