 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUIA-ViT: Unsupervised Inconsistency-Aware Method based on Vision Transformer for Face Forgery Detection
Paper and Code
Oct 23, 2022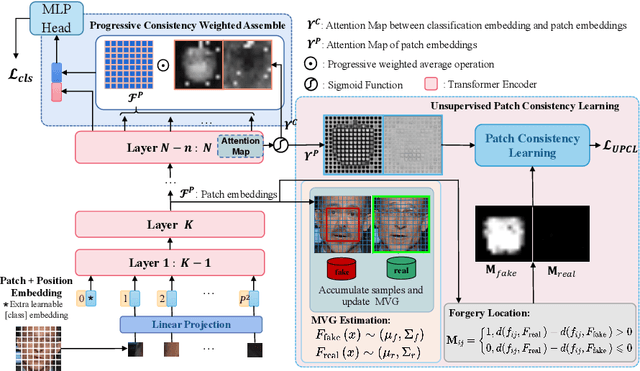


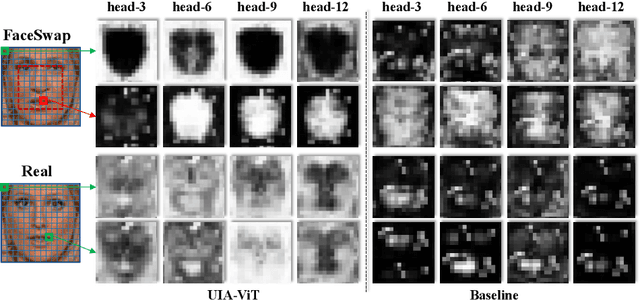
Intra-frame inconsistency has been proved to be effective for the generalization of face forgery detection. However, learning to focus on these inconsistency requires extra pixel-level forged location annotations. Acquiring such annotations is non-trivial. Some existing methods generate large-scale synthesized data with location annotations, which is only composed of real images and cannot capture the properties of forgery regions. Others generate forgery location labels by subtracting paired real and fake images, yet such paired data is difficult to collected and the generated label is usually discontinuous. To overcome these limitations, we propose a novel Unsupervised Inconsistency-Aware method based on Vision Transformer, called UIA-ViT, which only makes use of video-level labels and can learn inconsistency-aware feature without pixel-level annotations. Due to the self-attention mechanism, the attention map among patch embeddings naturally represents the consistency relation, making the vision Transformer suitable for the consistency representation learning. Based on vision Transformer, we propose two key components: Unsupervised Patch Consistency Learning (UPCL) and Progressive Consistency Weighted Assemble (PCWA). UPCL is designed for learning the consistency-related representation with progressive optimized pseudo annotations. PCWA enhances the final classification embedding with previous patch embeddings optimized by UPCL to further improve the detection performance. Extensive experiments demonstrate the effectiveness of the proposed method.