 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturbing a Neural Network to Infer Effective Connectivity: Evidence from Synthetic EEG Data
Jul 19, 2023



Identifying causal relationships among distinct brain areas, known as effective connectivity, holds key insights into the brain's information processing and cognitive functions. Electroencephalogram (EEG) signals exhibit intricate dynamics and inter-areal interactions within the brain. However, methods for characterizing nonlinear causal interactions among multiple brain regions remain relatively underdeveloped. In this study, we proposed a data-driven framework to infer effective connectivity by perturbing the trained neural networks. Specifically, we trained neural networks (i.e., CNN, vanilla RNN, GRU, LSTM, and Transformer) to predict future EEG signals according to historical data and perturbed the networks' input to obtain effective connectivity (EC) between the perturbed EEG channel and the rest of the channels. The EC reflects the causal impact of perturbing one node on others. The performance was tested on the synthetic EEG generated by a biological-plausible Jansen-Rit model. CNN and Transformer obtained the best performance on both 3-channel and 90-channel synthetic EEG data, outperforming the classical Granger causality method. Our work demonstrated the potential of perturbing an artificial neural network, learned to predict future system dynamics, to uncover the underlying causal structure.
UIA-ViT: Unsupervised Inconsistency-Aware Method based on Vision Transformer for Face Forgery Detection
Oct 23, 2022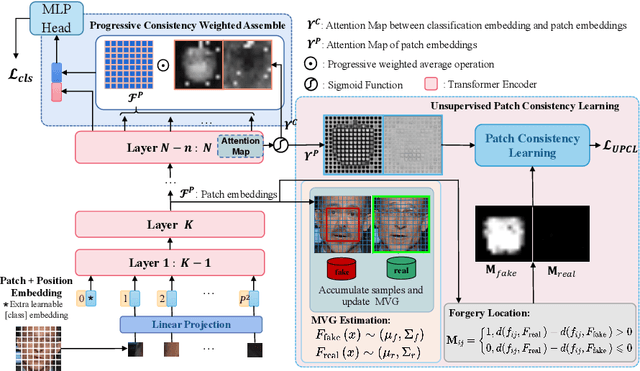


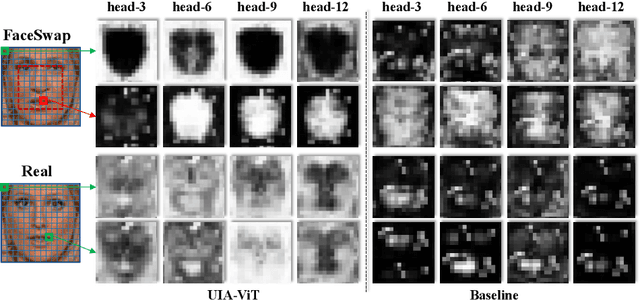
Intra-frame inconsistency has been proved to be effective for the generalization of face forgery detection. However, learning to focus on these inconsistency requires extra pixel-level forged location annotations. Acquiring such annotations is non-trivial. Some existing methods generate large-scale synthesized data with location annotations, which is only composed of real images and cannot capture the properties of forgery regions. Others generate forgery location labels by subtracting paired real and fake images, yet such paired data is difficult to collected and the generated label is usually discontinuous. To overcome these limitations, we propose a novel Unsupervised Inconsistency-Aware method based on Vision Transformer, called UIA-ViT, which only makes use of video-level labels and can learn inconsistency-aware feature without pixel-level annotations. Due to the self-attention mechanism, the attention map among patch embeddings naturally represents the consistency relation, making the vision Transformer suitable for the consistency representation learning. Based on vision Transformer, we propose two key components: Unsupervised Patch Consistency Learning (UPCL) and Progressive Consistency Weighted Assemble (PCWA). UPCL is designed for learning the consistency-related representation with progressive optimized pseudo annotations. PCWA enhances the final classification embedding with previous patch embeddings optimized by UPCL to further improve the detection performance. Extensive experiments demonstrate the effectiveness of the proposed method.