 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference-based Category Discovery: Unsupervised Object Detection with Category Awareness
May 06, 2026Traditional one-shot detection methods have addressed the closed-set problem in object detection, but the high cost of data annotation remains a critical challenge. General unsupervised methods generate pseudo boxes without category labels, thus failing to achieve category-aware classification. To overcome these limitations, we propose Reference-based Category Discovery (RefCD), an unsupervised detector that enables category-aware\footnotemark[1] detection without any manually annotated labels. It leverages feature similarity between predicted objects and unlabeled reference images. Unlike previous unsupervised methods that lack category guidance and one-shot methods which require labeled data, RefCD introduces a carefully designed feature similarity loss to explicitly guide the learning of potential category-specific features. Additionally, RefCD supports category-agnostic detection without reference images, serving as a unified framework. Comprehensive quantitative and qualitative analysis of category-aware and category-agnostic detection results demonstrates its effectiveness, and RefCD can learn category information in an unsupervised paradigm even without category labels.
Unposed-to-3D: Learning Simulation-Ready Vehicles from Real-World Images
Apr 21, 2026Creating realistic and simulation-ready 3D assets is crucial for autonomous driving research and virtual environment construction. However, existing 3D vehicle generation methods are often trained on synthetic data with significant domain gaps from real-world distributions. The generated models often exhibit arbitrary poses and undefined scales, resulting in poor visual consistency when integrated into driving scenes. In this paper, we present Unposed-to-3D, a novel framework that learns to reconstruct 3D vehicles from real-world driving images using image-only supervision. Our approach consists of two stages. In the first stage, we train an image-to-3D reconstruction network using posed images with known camera parameters. In the second stage, we remove camera supervision and use a camera prediction head that directly estimates the camera parameters from unposed images. The predicted pose is then used for differentiable rendering to provide self-supervised photometric feedback, enabling the model to learn 3D geometry purely from unposed images. To ensure simulation readiness, we further introduce a scale-aware module to predict real-world size information, and a harmonization module that adapts the generated vehicles to the target driving scene with consistent lighting and appearance. Extensive experiments demonstrate that Unposed-to-3D effectively reconstructs realistic, pose-consistent, and harmonized 3D vehicle models from real-world images, providing a scalable path toward creating high-quality assets for driving scene simulation and digital twin environments.
RIRF: Reasoning Image Restoration Framework
Apr 10, 2026Universal image restoration (UIR) aims to recover clean images from diverse and unknown degradations using a unified model. Existing UIR methods primarily focus on pixel reconstruction and often lack explicit diagnostic reasoning over degradation composition, severity, and scene semantics prior to restoration. We propose Reason and Restore (R\&R), a novel framework that integrates structured Chain-of-Thought (CoT) reasoning into the image restoration pipeline. R\&R introduces an explicit reasoner, implemented by fine-tuning Qwen3-VL, to diagnose degradation types, quantify degradation severity, infer key degradation-related factors, and describe relevant scene and object semantics. The resulting structured reasoning provides interpretable and fine-grained diagnostic priors for the restorer. To further improve restoration quality, the quantified degradation severity produced by the reasoner is leveraged as reinforcement learning (RL) signals to guide and strengthen the restorer. Unlike existing multimodal LLM-based agentic systems that decouple reasoning from low-level vision tasks, R\&R tightly couples semantic diagnostic reasoning with pixel-level restoration in a unified framework. Extensive experiments across diverse UIR benchmarks demonstrate that R\&R achieves state-of-the-art performance while offering unique interpretability into the restoration process.
OVS-DINO: Open-Vocabulary Segmentation via Structure-Aligned SAM-DINO with Language Guidance
Apr 09, 2026Open-Vocabulary Segmentation (OVS) aims to segment image regions beyond predefined category sets by leveraging semantic descriptions. While CLIP based approaches excel in semantic generalization, they frequently lack the fine-grained spatial awareness required for dense prediction. Recent efforts have incorporated Vision Foundation Models (VFMs) like DINO to alleviate these limitations. However, these methods still struggle with the precise edge perception necessary for high fidelity segmentation. In this paper, we analyze internal representations of DINO and discover that its inherent boundary awareness is not absent but rather undergoes progressive attenuation as features transition into deeper transformer blocks. To address this, we propose OVS-DINO, a novel framework that revitalizes latent edge-sensitivity of DINO through structural alignment with the Segment Anything Model (SAM). Specifically, we introduce a Structure-Aware Encoder (SAE) and a Structure-Modulated Decoder (SMD) to effectively activate boundary features of DINO using SAM's structural priors, complemented by a supervision strategy utilizing SAM generated pseudo-masks. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple weakly-supervised OVS benchmarks, improving the average score by 2.1% (from 44.8% to 46.9%). Notably, our approach significantly enhances segmentation accuracy in complex, cluttered scenarios, with a gain of 6.3% on Cityscapes (from 36.6% to 42.9%).
XYZCylinder: Feedforward Reconstruction for Driving Scenes Based on A Unified Cylinder Lifting Method
Oct 09, 2025Recently, more attention has been paid to feedforward reconstruction paradigms, which mainly learn a fixed view transformation implicitly and reconstruct the scene with a single representation. However, their generalization capability and reconstruction accuracy are still limited while reconstructing driving scenes, which results from two aspects: (1) The fixed view transformation fails when the camera configuration changes, limiting the generalization capability across different driving scenes equipped with different camera configurations. (2) The small overlapping regions between sparse views of the $360^\circ$ panorama and the complexity of driving scenes increase the learning difficulty, reducing the reconstruction accuracy. To handle these difficulties, we propose \textbf{XYZCylinder}, a feedforward model based on a unified cylinder lifting method which involves camera modeling and feature lifting. Specifically, to improve the generalization capability, we design a Unified Cylinder Camera Modeling (UCCM) strategy, which avoids the learning of viewpoint-dependent spatial correspondence and unifies different camera configurations with adjustable parameters. To improve the reconstruction accuracy, we propose a hybrid representation with several dedicated modules based on newly designed Cylinder Plane Feature Group (CPFG) to lift 2D image features to 3D space. Experimental results show that XYZCylinder achieves state-of-the-art performance under different evaluation settings, and can be generalized to other driving scenes in a zero-shot manner. Project page: \href{https://yuyuyu223.github.io/XYZCYlinder-projectpage/}{here}.
MAFE R-CNN: Selecting More Samples to Learn Category-aware Features for Small Object Detection
May 22, 2025Small object detection in intricate environments has consistently represented a major challenge in the field of object detection. In this paper, we identify that this difficulty stems from the detectors' inability to effectively learn discriminative features for objects of small size, compounded by the complexity of selecting high-quality small object samples during training, which motivates the proposal of the Multi-Clue Assignment and Feature Enhancement R-CNN.Specifically, MAFE R-CNN integrates two pivotal components.The first is the Multi-Clue Sample Selection (MCSS) strategy, in which the Intersection over Union (IoU) distance, predicted category confidence, and ground truth region sizes are leveraged as informative clues in the sample selection process. This methodology facilitates the selection of diverse positive samples and ensures a balanced distribution of object sizes during training, thereby promoting effective model learning.The second is the Category-aware Feature Enhancement Mechanism (CFEM), where we propose a simple yet effective category-aware memory module to explore the relationships among object features. Subsequently, we enhance the object feature representation by facilitating the interaction between category-aware features and candidate box features.Comprehensive experiments conducted on the large-scale small object dataset SODA validate the effectiveness of the proposed method. The code will be made publicly available.
Multi-Object Tracking in the Dark
May 10, 2024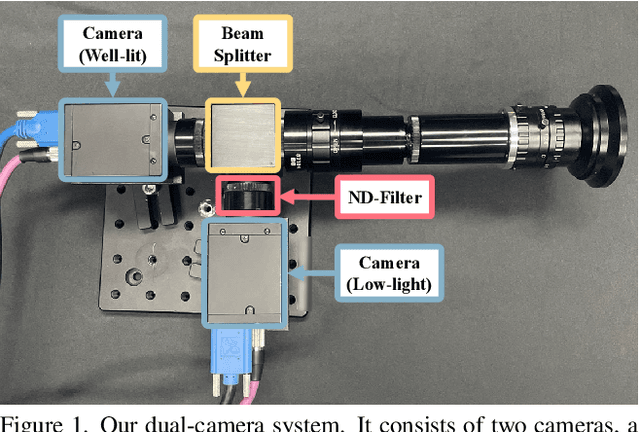
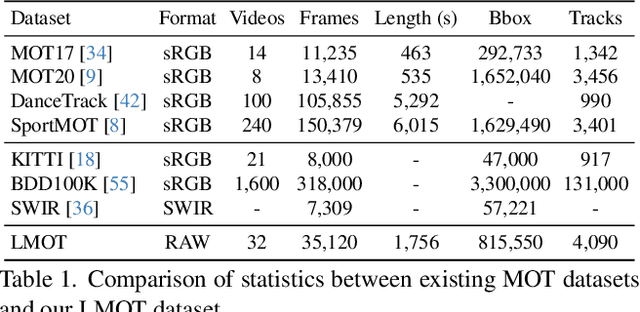

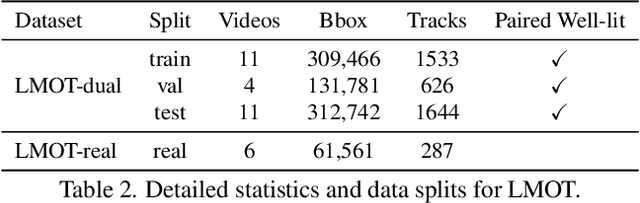
Low-light scenes are prevalent in real-world applications (e.g. autonomous driving and surveillance at night). Recently, multi-object tracking in various practical use cases have received much attention, but multi-object tracking in dark scenes is rarely considered. In this paper, we focus on multi-object tracking in dark scenes. To address the lack of datasets, we first build a Low-light Multi-Object Tracking (LMOT) dataset. LMOT provides well-aligned low-light video pairs captured by our dual-camera system, and high-quality multi-object tracking annotations for all videos. Then, we propose a low-light multi-object tracking method, termed as LTrack. We introduce the adaptive low-pass downsample module to enhance low-frequency components of images outside the sensor noises. The degradation suppression learning strategy enables the model to learn invariant information under noise disturbance and image quality degradation. These components improve the robustness of multi-object tracking in dark scenes. We conducted a comprehensive analysis of our LMOT dataset and proposed LTrack. Experimental results demonstrate the superiority of the proposed method and its competitiveness in real night low-light scenes. Dataset and Code: https: //github.com/ying-fu/LMOT
Transformer based Pluralistic Image Completion with Reduced Information Loss
Apr 15, 2024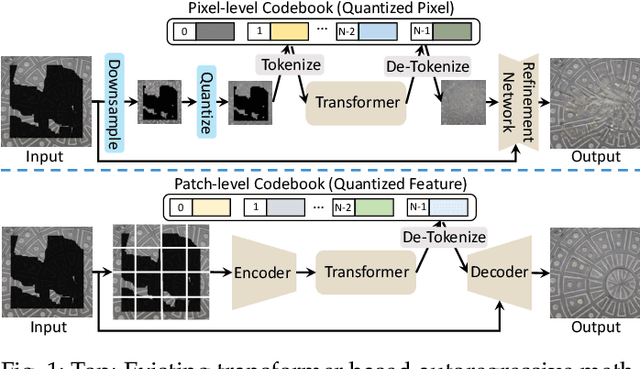


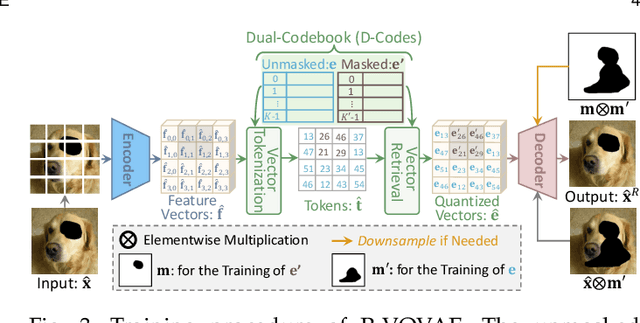
Transformer based methods have achieved great success in image inpainting recently. However, we find that these solutions regard each pixel as a token, thus suffering from an information loss issue from two aspects: 1) They downsample the input image into much lower resolutions for efficiency consideration. 2) They quantize $256^3$ RGB values to a small number (such as 512) of quantized color values. The indices of quantized pixels are used as tokens for the inputs and prediction targets of the transformer. To mitigate these issues, we propose a new transformer based framework called "PUT". Specifically, to avoid input downsampling while maintaining computation efficiency, we design a patch-based auto-encoder P-VQVAE. The encoder converts the masked image into non-overlapped patch tokens and the decoder recovers the masked regions from the inpainted tokens while keeping the unmasked regions unchanged. To eliminate the information loss caused by input quantization, an Un-quantized Transformer is applied. It directly takes features from the P-VQVAE encoder as input without any quantization and only regards the quantized tokens as prediction targets. Furthermore, to make the inpainting process more controllable, we introduce semantic and structural conditions as extra guidance. Extensive experiments show that our method greatly outperforms existing transformer based methods on image fidelity and achieves much higher diversity and better fidelity than state-of-the-art pluralistic inpainting methods on complex large-scale datasets (e.g., ImageNet). Codes are available at https://github.com/liuqk3/PUT.
Infrared Small Target Detection with Scale and Location Sensitivity
Mar 28, 2024



Recently, infrared small target detection (IRSTD) has been dominated by deep-learning-based methods. However, these methods mainly focus on the design of complex model structures to extract discriminative features, leaving the loss functions for IRSTD under-explored. For example, the widely used Intersection over Union (IoU) and Dice losses lack sensitivity to the scales and locations of targets, limiting the detection performance of detectors. In this paper, we focus on boosting detection performance with a more effective loss but a simpler model structure. Specifically, we first propose a novel Scale and Location Sensitive (SLS) loss to handle the limitations of existing losses: 1) for scale sensitivity, we compute a weight for the IoU loss based on target scales to help the detector distinguish targets with different scales: 2) for location sensitivity, we introduce a penalty term based on the center points of targets to help the detector localize targets more precisely. Then, we design a simple Multi-Scale Head to the plain U-Net (MSHNet). By applying SLS loss to each scale of the predictions, our MSHNet outperforms existing state-of-the-art methods by a large margin. In addition, the detection performance of existing detectors can be further improved when trained with our SLS loss, demonstrating the effectiveness and generalization of our SLS loss. The code is available at https://github.com/ying-fu/MSHNet.
Towards More Unified In-context Visual Understanding
Dec 05, 2023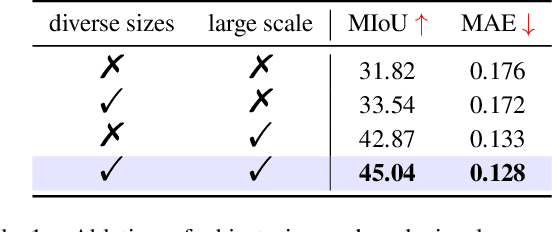
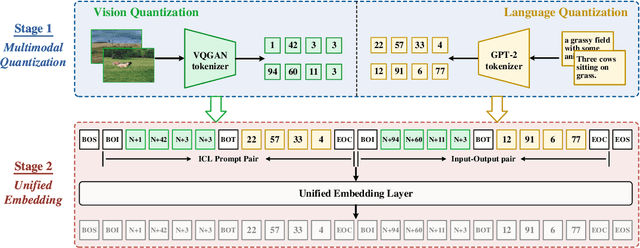

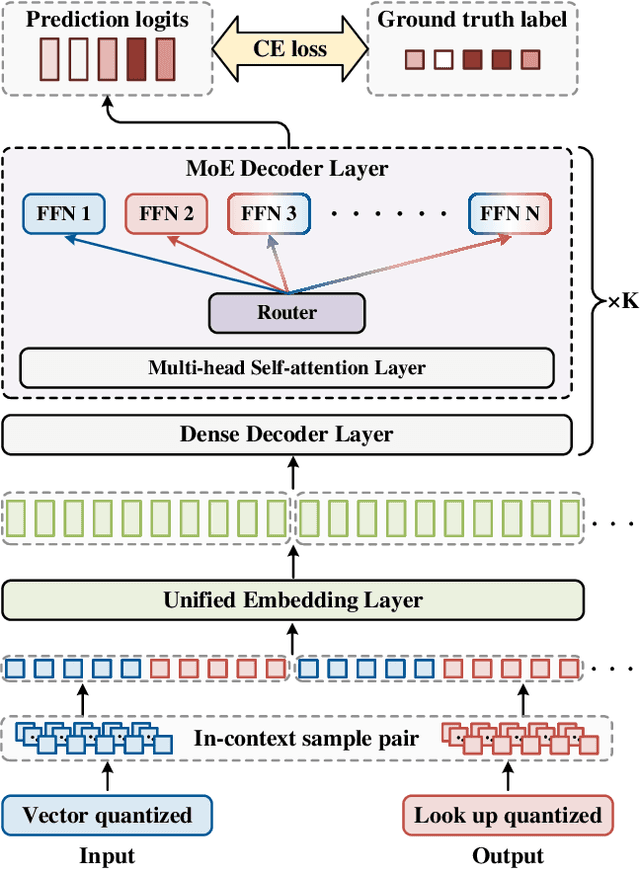
The rapid advancement of large language models (LLMs) has accelerated the emergence of in-context learning (ICL) as a cutting-edge approach in the natural language processing domain. Recently, ICL has been employed in visual understanding tasks, such as semantic segmentation and image captioning, yielding promising results. However, existing visual ICL framework can not enable producing content across multiple modalities, which limits their potential usage scenarios. To address this issue, we present a new ICL framework for visual understanding with multi-modal output enabled. First, we quantize and embed both text and visual prompt into a unified representational space, structured as interleaved in-context sequences. Then a decoder-only sparse transformer architecture is employed to perform generative modeling on them, facilitating in-context learning. Thanks to this design, the model is capable of handling in-context vision understanding tasks with multimodal output in a unified pipeline. Experimental results demonstrate that our model achieves competitive performance compared with specialized models and previous ICL baselines. Overall, our research takes a further step toward unified multimodal in-context learning.