 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunAudio-ASR Technical Report
Sep 15, 2025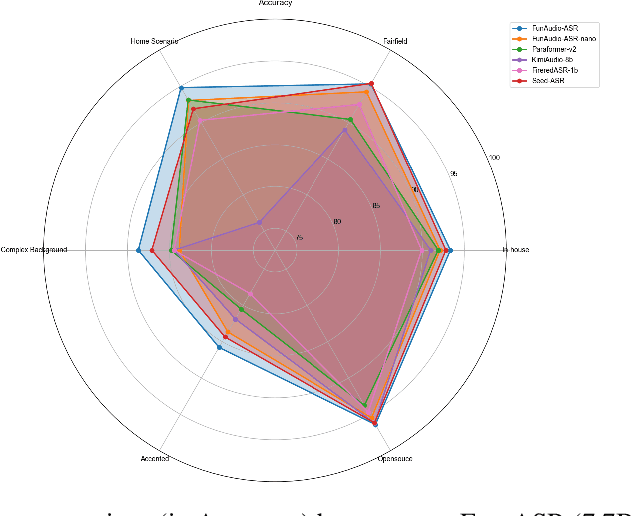
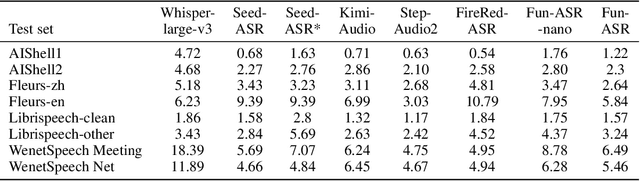
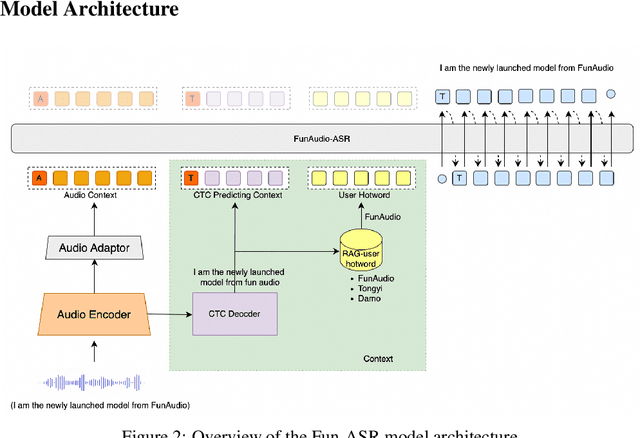
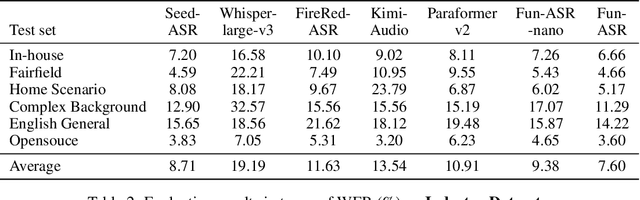
In recent years, automatic speech recognition (ASR) has witnessed transformative advancements driven by three complementary paradigms: data scaling, model size scaling, and deep integration with large language models (LLMs). However, LLMs are prone to hallucination, which can significantly degrade user experience in real-world ASR applications. In this paper, we present FunAudio-ASR, a large-scale, LLM-based ASR system that synergistically combines massive data, large model capacity, LLM integration, and reinforcement learning to achieve state-of-the-art performance across diverse and complex speech recognition scenarios. Moreover, FunAudio-ASR is specifically optimized for practical deployment, with enhancements in streaming capability, noise robustness, code-switching, hotword customization, and satisfying other real-world application requirements. Experimental results show that while most LLM-based ASR systems achieve strong performance on open-source benchmarks, they often underperform on real industry evaluation sets. Thanks to production-oriented optimizations, FunAudio-ASR achieves SOTA performance on real application datasets, demonstrating its effectiveness and robustness in practical settings.
Generalizable Origin Identification for Text-Guided Image-to-Image Diffusion Models
Jan 04, 2025
Text-guided image-to-image diffusion models excel in translating images based on textual prompts, allowing for precise and creative visual modifications. However, such a powerful technique can be misused for spreading misinformation, infringing on copyrights, and evading content tracing. This motivates us to introduce the task of origin IDentification for text-guided Image-to-image Diffusion models (ID$^2$), aiming to retrieve the original image of a given translated query. A straightforward solution to ID$^2$ involves training a specialized deep embedding model to extract and compare features from both query and reference images. However, due to visual discrepancy across generations produced by different diffusion models, this similarity-based approach fails when training on images from one model and testing on those from another, limiting its effectiveness in real-world applications. To solve this challenge of the proposed ID$^2$ task, we contribute the first dataset and a theoretically guaranteed method, both emphasizing generalizability. The curated dataset, OriPID, contains abundant Origins and guided Prompts, which can be used to train and test potential IDentification models across various diffusion models. In the method section, we first prove the existence of a linear transformation that minimizes the distance between the pre-trained Variational Autoencoder (VAE) embeddings of generated samples and their origins. Subsequently, it is demonstrated that such a simple linear transformation can be generalized across different diffusion models. Experimental results show that the proposed method achieves satisfying generalization performance, significantly surpassing similarity-based methods ($+31.6\%$ mAP), even those with generalization designs.
SweetTokenizer: Semantic-Aware Spatial-Temporal Tokenizer for Compact Visual Discretization
Dec 17, 2024



This paper presents the \textbf{S}emantic-a\textbf{W}ar\textbf{E} spatial-t\textbf{E}mporal \textbf{T}okenizer (SweetTokenizer), a compact yet effective discretization approach for vision data. Our goal is to boost tokenizers' compression ratio while maintaining reconstruction fidelity in the VQ-VAE paradigm. Firstly, to obtain compact latent representations, we decouple images or videos into spatial-temporal dimensions, translating visual information into learnable querying spatial and temporal tokens through a \textbf{C}ross-attention \textbf{Q}uery \textbf{A}uto\textbf{E}ncoder (CQAE). Secondly, to complement visual information during compression, we quantize these tokens via a specialized codebook derived from off-the-shelf LLM embeddings to leverage the rich semantics from language modality. Finally, to enhance training stability and convergence, we also introduce a curriculum learning strategy, which proves critical for effective discrete visual representation learning. SweetTokenizer achieves comparable video reconstruction fidelity with only \textbf{25\%} of the tokens used in previous state-of-the-art video tokenizers, and boost video generation results by \textbf{32.9\%} w.r.t gFVD. When using the same token number, we significantly improves video and image reconstruction results by \textbf{57.1\%} w.r.t rFVD on UCF-101 and \textbf{37.2\%} w.r.t rFID on ImageNet-1K. Additionally, the compressed tokens are imbued with semantic information, enabling few-shot recognition capabilities powered by LLMs in downstream applications.
Llama SLayer 8B: Shallow Layers Hold the Key to Knowledge Injection
Oct 03, 2024



As a manner to augment pre-trained large language models (LLM), knowledge injection is critical to develop vertical domain large models and has been widely studied. Although most current approaches, including parameter-efficient fine-tuning (PEFT) and block expansion methods, uniformly apply knowledge across all LLM layers, it raises the question: are all layers equally crucial for knowledge injection? We begin by evaluating the importance of each layer in finding the optimal layer range for knowledge injection. Intuitively, the more important layers should play a more critical role in knowledge injection and deserve a denser injection. We observe performance dips in question-answering benchmarks after the removal or expansion of the shallow layers, and the degradation shrinks as the layer gets deeper, indicating that the shallow layers hold the key to knowledge injection. This insight leads us to propose the S strategy, a post-pretraining strategy of selectively enhancing shallow layers while pruning the less effective deep ones. Based on this strategy, we introduce Llama Slayer-8B and Llama Slayer-8B-Instruct. We experimented on the corpus of code $\&$ math and demonstrated the effectiveness of our strategy. Further experiments across different LLM, Mistral-7B, and a legal corpus confirmed the general applicability of the approach, underscoring its wide-ranging efficacy. Our code is available at: \https://github.com/txchen-USTC/Llama-Slayer
Image Copy Detection for Diffusion Models
Sep 30, 2024



Images produced by diffusion models are increasingly popular in digital artwork and visual marketing. However, such generated images might replicate content from existing ones and pose the challenge of content originality. Existing Image Copy Detection (ICD) models, though accurate in detecting hand-crafted replicas, overlook the challenge from diffusion models. This motivates us to introduce ICDiff, the first ICD specialized for diffusion models. To this end, we construct a Diffusion-Replication (D-Rep) dataset and correspondingly propose a novel deep embedding method. D-Rep uses a state-of-the-art diffusion model (Stable Diffusion V1.5) to generate 40, 000 image-replica pairs, which are manually annotated into 6 replication levels ranging from 0 (no replication) to 5 (total replication). Our method, PDF-Embedding, transforms the replication level of each image-replica pair into a probability density function (PDF) as the supervision signal. The intuition is that the probability of neighboring replication levels should be continuous and smooth. Experimental results show that PDF-Embedding surpasses protocol-driven methods and non-PDF choices on the D-Rep test set. Moreover, by utilizing PDF-Embedding, we find that the replication ratios of well-known diffusion models against an open-source gallery range from 10% to 20%.
Mixture-of-Noises Enhanced Forgery-Aware Predictor for Multi-Face Manipulation Detection and Localization
Aug 05, 2024



With the advancement of face manipulation technology, forgery images in multi-face scenarios are gradually becoming a more complex and realistic challenge. Despite this, detection and localization methods for such multi-face manipulations remain underdeveloped. Traditional manipulation localization methods either indirectly derive detection results from localization masks, resulting in limited detection performance, or employ a naive two-branch structure to simultaneously obtain detection and localization results, which cannot effectively benefit the localization capability due to limited interaction between two tasks. This paper proposes a new framework, namely MoNFAP, specifically tailored for multi-face manipulation detection and localization. The MoNFAP primarily introduces two novel modules: the Forgery-aware Unified Predictor (FUP) Module and the Mixture-of-Noises Module (MNM). The FUP integrates detection and localization tasks using a token learning strategy and multiple forgery-aware transformers, which facilitates the use of classification information to enhance localization capability. Besides, motivated by the crucial role of noise information in forgery detection, the MNM leverages multiple noise extractors based on the concept of the mixture of experts to enhance the general RGB features, further boosting the performance of our framework. Finally, we establish a comprehensive benchmark for multi-face detection and localization and the proposed \textit{MoNFAP} achieves significant performance. The codes will be made available.
Learning Solution-Aware Transformers for Efficiently Solving Quadratic Assignment Problem
Jun 14, 2024



Recently various optimization problems, such as Mixed Integer Linear Programming Problems (MILPs), have undergone comprehensive investigation, leveraging the capabilities of machine learning. This work focuses on learning-based solutions for efficiently solving the Quadratic Assignment Problem (QAPs), which stands as a formidable challenge in combinatorial optimization. While many instances of simpler problems admit fully polynomial-time approximate solution (FPTAS), QAP is shown to be strongly NP-hard. Even finding a FPTAS for QAP is difficult, in the sense that the existence of a FPTAS implies $P = NP$. Current research on QAPs suffer from limited scale and computational inefficiency. To attack the aforementioned issues, we here propose the first solution of its kind for QAP in the learn-to-improve category. This work encodes facility and location nodes separately, instead of forming computationally intensive association graphs prevalent in current approaches. This design choice enables scalability to larger problem sizes. Furthermore, a \textbf{S}olution \textbf{AW}are \textbf{T}ransformer (SAWT) architecture integrates the incumbent solution matrix with the attention score to effectively capture higher-order information of the QAPs. Our model's effectiveness is validated through extensive experiments on self-generated QAP instances of varying sizes and the QAPLIB benchmark.
AnyPattern: Towards In-context Image Copy Detection
Apr 28, 2024



This paper explores in-context learning for image copy detection (ICD), i.e., prompting an ICD model to identify replicated images with new tampering patterns without the need for additional training. The prompts (or the contexts) are from a small set of image-replica pairs that reflect the new patterns and are used at inference time. Such in-context ICD has good realistic value, because it requires no fine-tuning and thus facilitates fast reaction against the emergence of unseen patterns. To accommodate the "seen $\rightarrow$ unseen" generalization scenario, we construct the first large-scale pattern dataset named AnyPattern, which has the largest number of tamper patterns ($90$ for training and $10$ for testing) among all the existing ones. We benchmark AnyPattern with popular ICD methods and reveal that existing methods barely generalize to novel patterns. We further propose a simple in-context ICD method named ImageStacker. ImageStacker learns to select the most representative image-replica pairs and employs them as the pattern prompts in a stacking manner (rather than the popular concatenation manner). Experimental results show (1) training with our large-scale dataset substantially benefits pattern generalization ($+26.66 \%$ $\mu AP$), (2) the proposed ImageStacker facilitates effective in-context ICD (another round of $+16.75 \%$ $\mu AP$), and (3) AnyPattern enables in-context ICD, i.e., without such a large-scale dataset, in-context learning does not emerge even with our ImageStacker. Beyond the ICD task, we also demonstrate how AnyPattern can benefit artists, i.e., the pattern retrieval method trained on AnyPattern can be generalized to identify style mimicry by text-to-image models. The project is publicly available at https://anypattern.github.io.
Transformer based Pluralistic Image Completion with Reduced Information Loss
Apr 15, 2024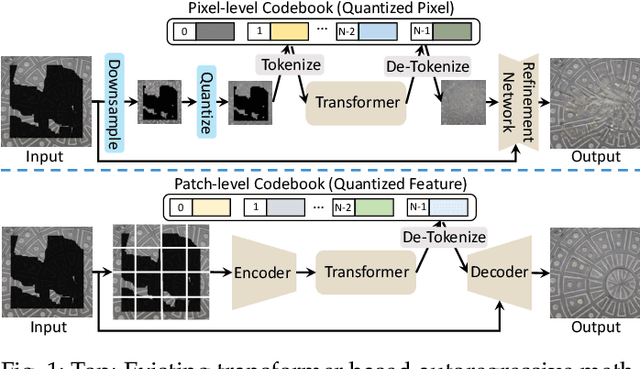


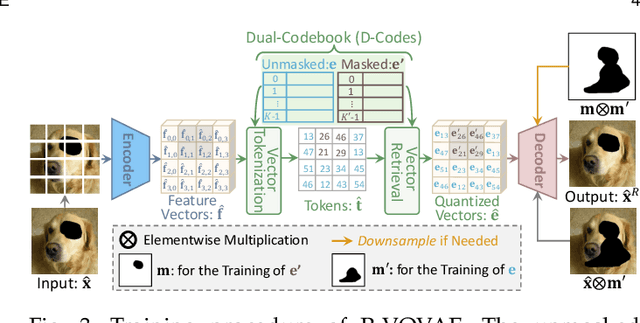
Transformer based methods have achieved great success in image inpainting recently. However, we find that these solutions regard each pixel as a token, thus suffering from an information loss issue from two aspects: 1) They downsample the input image into much lower resolutions for efficiency consideration. 2) They quantize $256^3$ RGB values to a small number (such as 512) of quantized color values. The indices of quantized pixels are used as tokens for the inputs and prediction targets of the transformer. To mitigate these issues, we propose a new transformer based framework called "PUT". Specifically, to avoid input downsampling while maintaining computation efficiency, we design a patch-based auto-encoder P-VQVAE. The encoder converts the masked image into non-overlapped patch tokens and the decoder recovers the masked regions from the inpainted tokens while keeping the unmasked regions unchanged. To eliminate the information loss caused by input quantization, an Un-quantized Transformer is applied. It directly takes features from the P-VQVAE encoder as input without any quantization and only regards the quantized tokens as prediction targets. Furthermore, to make the inpainting process more controllable, we introduce semantic and structural conditions as extra guidance. Extensive experiments show that our method greatly outperforms existing transformer based methods on image fidelity and achieves much higher diversity and better fidelity than state-of-the-art pluralistic inpainting methods on complex large-scale datasets (e.g., ImageNet). Codes are available at https://github.com/liuqk3/PUT.
MiM-ISTD: Mamba-in-Mamba for Efficient Infrared Small Target Detection
Mar 08, 2024



Recently, infrared small target detection (ISTD) has made significant progress, thanks to the development of basic models. Specifically, the structures combining convolutional networks with transformers can successfully extract both local and global features. However, the disadvantage of the transformer is also inherited, i.e., the quadratic computational complexity to the length of the sequence. Inspired by the recent basic model with linear complexity for long-distance modeling, called Mamba, we explore the potential of this state space model for ISTD task in terms of effectiveness and efficiency in the paper. However, directly applying Mamba achieves poor performance since local features, which are critical to detecting small targets, cannot be fully exploited. Instead, we tailor a Mamba-in-Mamba (MiM-ISTD) structure for efficient ISTD. Specifically, we treat the local patches as "visual sentences" and use the Outer Mamba to explore the global information. We then decompose each visual sentence into sub-patches as "visual words" and use the Inner Mamba to further explore the local information among words in the visual sentence with negligible computational costs. By aggregating the word and sentence features, the MiM-ISTD can effectively explore both global and local information. Experiments on NUAA-SIRST and IRSTD-1k show the superior accuracy and efficiency of our method. Specifically, MiM-ISTD is $10 \times$ faster than the SOTA method and reduces GPU memory usage by 73.4$\%$ when testing on $2048 \times 2048$ image, overcoming the computation and memory constraints on high-resolution infrared images. Source code is available at https://github.com/txchen-USTC/MiM-ISTD.