 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Dynamic Inter-Client Spatial Dependencies: A Federated Spatio-Temporal Graph Learning Method for Traffic Flow Forecasting
Nov 13, 2025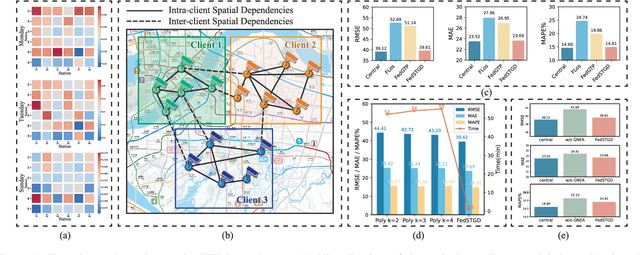

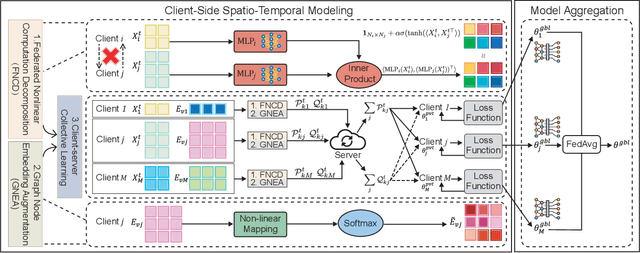
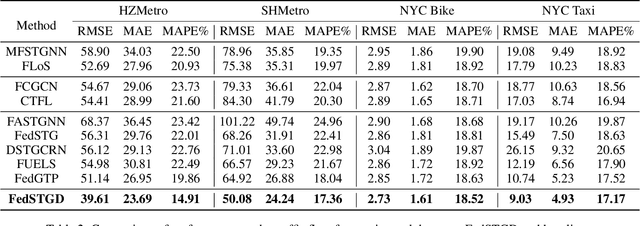
Spatio-temporal graphs are powerful tools for modeling complex dependencies in traffic time series. However, the distributed nature of real-world traffic data across multiple stakeholders poses significant challenges in modeling and reconstructing inter-client spatial dependencies while adhering to data locality constraints. Existing methods primarily address static dependencies, overlooking their dynamic nature and resulting in suboptimal performance. In response, we propose Federated Spatio-Temporal Graph with Dynamic Inter-Client Dependencies (FedSTGD), a framework designed to model and reconstruct dynamic inter-client spatial dependencies in federated learning. FedSTGD incorporates a federated nonlinear computation decomposition module to approximate complex graph operations. This is complemented by a graph node embedding augmentation module, which alleviates performance degradation arising from the decomposition. These modules are coordinated through a client-server collective learning protocol, which decomposes dynamic inter-client spatial dependency learning tasks into lightweight, parallelizable subtasks. Extensive experiments on four real-world datasets demonstrate that FedSTGD achieves superior performance over state-of-the-art baselines in terms of RMSE, MAE, and MAPE, approaching that of centralized baselines. Ablation studies confirm the contribution of each module in addressing dynamic inter-client spatial dependencies, while sensitivity analysis highlights the robustness of FedSTGD to variations in hyperparameters.
Oblivionis: A Lightweight Learning and Unlearning Framework for Federated Large Language Models
Aug 12, 2025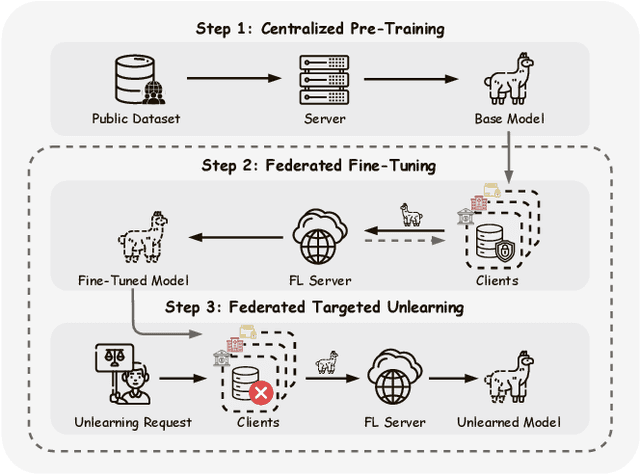
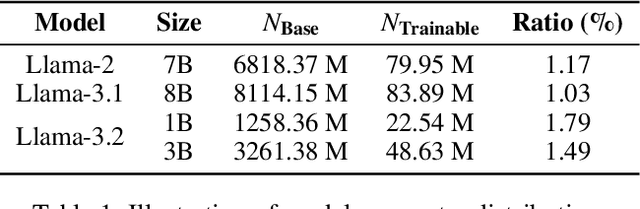
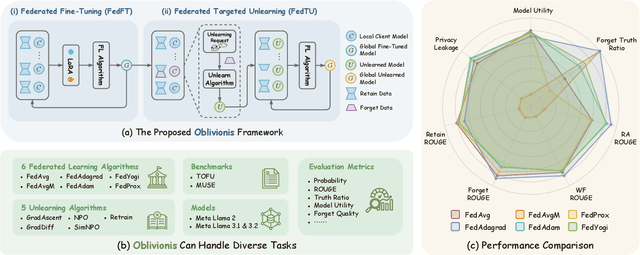
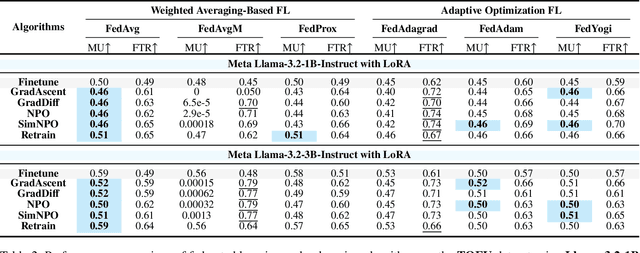
Large Language Models (LLMs) increasingly leverage Federated Learning (FL) to utilize private, task-specific datasets for fine-tuning while preserving data privacy. However, while federated LLM frameworks effectively enable collaborative training without raw data sharing, they critically lack built-in mechanisms for regulatory compliance like GDPR's right to be forgotten. Integrating private data heightens concerns over data quality and long-term governance, yet existing distributed training frameworks offer no principled way to selectively remove specific client contributions post-training. Due to distributed data silos, stringent privacy constraints, and the intricacies of interdependent model aggregation, federated LLM unlearning is significantly more complex than centralized LLM unlearning. To address this gap, we introduce Oblivionis, a lightweight learning and unlearning framework that enables clients to selectively remove specific private data during federated LLM training, enhancing trustworthiness and regulatory compliance. By unifying FL and unlearning as a dual optimization objective, we incorporate 6 FL and 5 unlearning algorithms for comprehensive evaluation and comparative analysis, establishing a robust pipeline for federated LLM unlearning. Extensive experiments demonstrate that Oblivionis outperforms local training, achieving a robust balance between forgetting efficacy and model utility, with cross-algorithm comparisons providing clear directions for future LLM development.
Pindrop it! Audio and Visual Deepfake Countermeasures for Robust Detection and Fine Grained-Localization
Aug 11, 2025The field of visual and audio generation is burgeoning with new state-of-the-art methods. This rapid proliferation of new techniques underscores the need for robust solutions for detecting synthetic content in videos. In particular, when fine-grained alterations via localized manipulations are performed in visual, audio, or both domains, these subtle modifications add challenges to the detection algorithms. This paper presents solutions for the problems of deepfake video classification and localization. The methods were submitted to the ACM 1M Deepfakes Detection Challenge, achieving the best performance in the temporal localization task and a top four ranking in the classification task for the TestA split of the evaluation dataset.
VisAlgae 2023: A Dataset and Challenge for Algae Detection in Microscopy Images
May 27, 2025Microalgae, vital for ecological balance and economic sectors, present challenges in detection due to their diverse sizes and conditions. This paper summarizes the second "Vision Meets Algae" (VisAlgae 2023) Challenge, aiming to enhance high-throughput microalgae cell detection. The challenge, which attracted 369 participating teams, includes a dataset of 1000 images across six classes, featuring microalgae of varying sizes and distinct features. Participants faced tasks such as detecting small targets, handling motion blur, and complex backgrounds. The top 10 methods, outlined here, offer insights into overcoming these challenges and maximizing detection accuracy. This intersection of algae research and computer vision offers promise for ecological understanding and technological advancement. The dataset can be accessed at: https://github.com/juntaoJianggavin/Visalgae2023/.
Llama SLayer 8B: Shallow Layers Hold the Key to Knowledge Injection
Oct 03, 2024



As a manner to augment pre-trained large language models (LLM), knowledge injection is critical to develop vertical domain large models and has been widely studied. Although most current approaches, including parameter-efficient fine-tuning (PEFT) and block expansion methods, uniformly apply knowledge across all LLM layers, it raises the question: are all layers equally crucial for knowledge injection? We begin by evaluating the importance of each layer in finding the optimal layer range for knowledge injection. Intuitively, the more important layers should play a more critical role in knowledge injection and deserve a denser injection. We observe performance dips in question-answering benchmarks after the removal or expansion of the shallow layers, and the degradation shrinks as the layer gets deeper, indicating that the shallow layers hold the key to knowledge injection. This insight leads us to propose the S strategy, a post-pretraining strategy of selectively enhancing shallow layers while pruning the less effective deep ones. Based on this strategy, we introduce Llama Slayer-8B and Llama Slayer-8B-Instruct. We experimented on the corpus of code $\&$ math and demonstrated the effectiveness of our strategy. Further experiments across different LLM, Mistral-7B, and a legal corpus confirmed the general applicability of the approach, underscoring its wide-ranging efficacy. Our code is available at: \https://github.com/txchen-USTC/Llama-Slayer
Source Tracing of Audio Deepfake Systems
Jul 10, 2024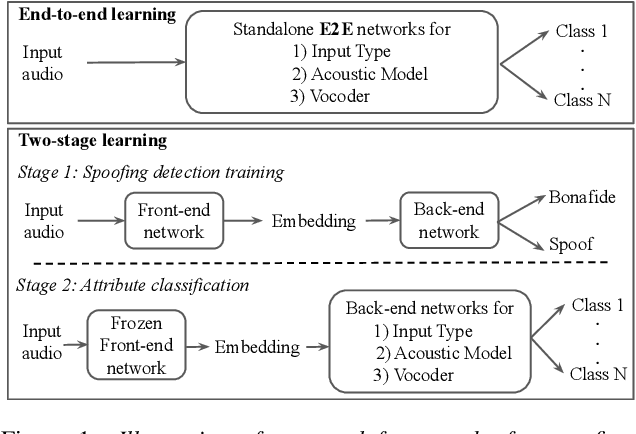
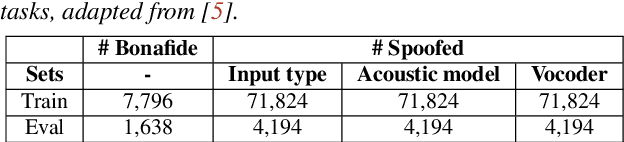

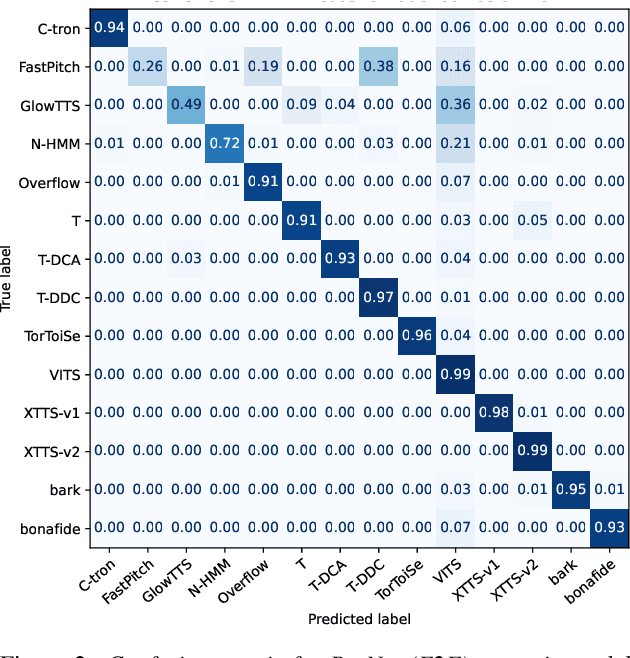
Recent progress in generative AI technology has made audio deepfakes remarkably more realistic. While current research on anti-spoofing systems primarily focuses on assessing whether a given audio sample is fake or genuine, there has been limited attention on discerning the specific techniques to create the audio deepfakes. Algorithms commonly used in audio deepfake generation, like text-to-speech (TTS) and voice conversion (VC), undergo distinct stages including input processing, acoustic modeling, and waveform generation. In this work, we introduce a system designed to classify various spoofing attributes, capturing the distinctive features of individual modules throughout the entire generation pipeline. We evaluate our system on two datasets: the ASVspoof 2019 Logical Access and the Multi-Language Audio Anti-Spoofing Dataset (MLAAD). Results from both experiments demonstrate the robustness of the system to identify the different spoofing attributes of deepfake generation systems.
A Survey on Visual Mamba
Apr 26, 2024State space models (SSMs) with selection mechanisms and hardware-aware architectures, namely Mamba, have recently demonstrated significant promise in long-sequence modeling. Since the self-attention mechanism in transformers has quadratic complexity with image size and increasing computational demands, the researchers are now exploring how to adapt Mamba for computer vision tasks. This paper is the first comprehensive survey aiming to provide an in-depth analysis of Mamba models in the field of computer vision. It begins by exploring the foundational concepts contributing to Mamba's success, including the state space model framework, selection mechanisms, and hardware-aware design. Next, we review these vision mamba models by categorizing them into foundational ones and enhancing them with techniques such as convolution, recurrence, and attention to improve their sophistication. We further delve into the widespread applications of Mamba in vision tasks, which include their use as a backbone in various levels of vision processing. This encompasses general visual tasks, Medical visual tasks (e.g., 2D / 3D segmentation, classification, and image registration, etc.), and Remote Sensing visual tasks. We specially introduce general visual tasks from two levels: High/Mid-level vision (e.g., Object detection, Segmentation, Video classification, etc.) and Low-level vision (e.g., Image super-resolution, Image restoration, Visual generation, etc.). We hope this endeavor will spark additional interest within the community to address current challenges and further apply Mamba models in computer vision.
MiM-ISTD: Mamba-in-Mamba for Efficient Infrared Small Target Detection
Mar 08, 2024



Recently, infrared small target detection (ISTD) has made significant progress, thanks to the development of basic models. Specifically, the structures combining convolutional networks with transformers can successfully extract both local and global features. However, the disadvantage of the transformer is also inherited, i.e., the quadratic computational complexity to the length of the sequence. Inspired by the recent basic model with linear complexity for long-distance modeling, called Mamba, we explore the potential of this state space model for ISTD task in terms of effectiveness and efficiency in the paper. However, directly applying Mamba achieves poor performance since local features, which are critical to detecting small targets, cannot be fully exploited. Instead, we tailor a Mamba-in-Mamba (MiM-ISTD) structure for efficient ISTD. Specifically, we treat the local patches as "visual sentences" and use the Outer Mamba to explore the global information. We then decompose each visual sentence into sub-patches as "visual words" and use the Inner Mamba to further explore the local information among words in the visual sentence with negligible computational costs. By aggregating the word and sentence features, the MiM-ISTD can effectively explore both global and local information. Experiments on NUAA-SIRST and IRSTD-1k show the superior accuracy and efficiency of our method. Specifically, MiM-ISTD is $10 \times$ faster than the SOTA method and reduces GPU memory usage by 73.4$\%$ when testing on $2048 \times 2048$ image, overcoming the computation and memory constraints on high-resolution infrared images. Source code is available at https://github.com/txchen-USTC/MiM-ISTD.
P-Mamba: Marrying Perona Malik Diffusion with Mamba for Efficient Pediatric Echocardiographic Left Ventricular Segmentation
Feb 13, 2024In pediatric cardiology, the accurate and immediate assessment of cardiac function through echocardiography is important since it can determine whether urgent intervention is required in many emergencies. However, echocardiography is characterized by ambiguity and heavy background noise interference, bringing more difficulty to accurate segmentation. Present methods lack efficiency and are also prone to mistakenly segmenting some background noise areas as the left ventricular area due to noise disturbance. To relieve the two issues, we introduce P-Mamba for efficient pediatric echocardiographic left ventricular segmentation. Specifically, we turn to the recently proposed vision mamba layers in our vision mamba encoder branch to improve the computing and memory efficiency of our model while modeling global dependencies. In the other DWT-based PMD encoder branch, we devise DWT-based Perona-Malik Diffusion (PMD) Blocks that utilize PMD for noise suppression, while simultaneously preserving the local shape cues of the left ventricle. Leveraging the strengths of both the two encoder branches, P-Mamba achieves superior accuracy and efficiency to established models, such as vision transformers with quadratic and linear computational complexity. This innovative approach promises significant advancements in pediatric cardiac imaging and beyond.
Bootstrapping Audio-Visual Segmentation by Strengthening Audio Cues
Feb 06, 2024



How to effectively interact audio with vision has garnered considerable interest within the multi-modality research field. Recently, a novel audio-visual segmentation (AVS) task has been proposed, aiming to segment the sounding objects in video frames under the guidance of audio cues. However, most existing AVS methods are hindered by a modality imbalance where the visual features tend to dominate those of the audio modality, due to a unidirectional and insufficient integration of audio cues. This imbalance skews the feature representation towards the visual aspect, impeding the learning of joint audio-visual representations and potentially causing segmentation inaccuracies. To address this issue, we propose AVSAC. Our approach features a Bidirectional Audio-Visual Decoder (BAVD) with integrated bidirectional bridges, enhancing audio cues and fostering continuous interplay between audio and visual modalities. This bidirectional interaction narrows the modality imbalance, facilitating more effective learning of integrated audio-visual representations. Additionally, we present a strategy for audio-visual frame-wise synchrony as fine-grained guidance of BAVD. This strategy enhances the share of auditory components in visual features, contributing to a more balanced audio-visual representation learning. Extensive experiments show that our method attains new benchmarks in AVS performance.