 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource Tracing of Audio Deepfake Systems
Jul 10, 2024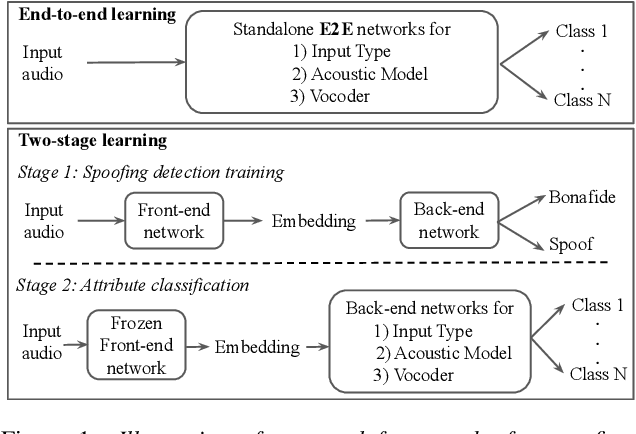
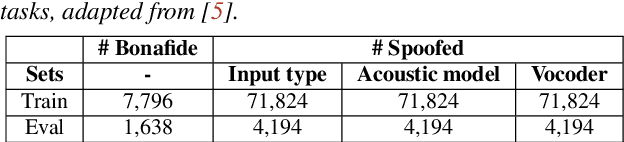

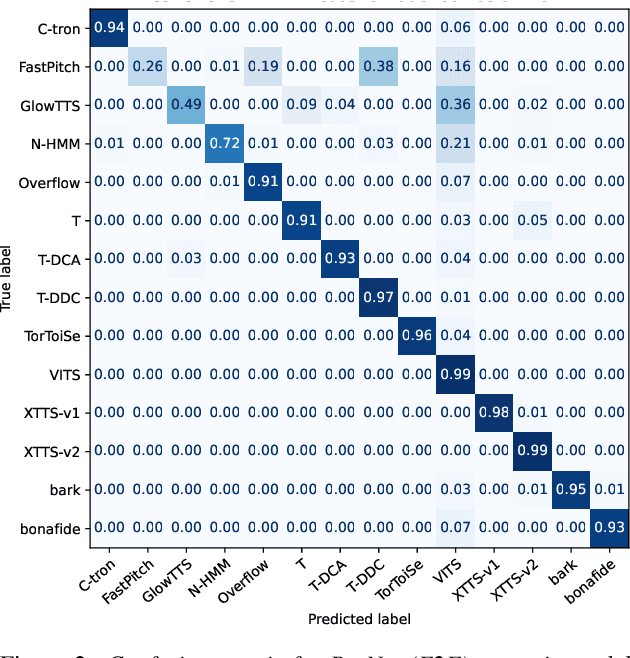
Recent progress in generative AI technology has made audio deepfakes remarkably more realistic. While current research on anti-spoofing systems primarily focuses on assessing whether a given audio sample is fake or genuine, there has been limited attention on discerning the specific techniques to create the audio deepfakes. Algorithms commonly used in audio deepfake generation, like text-to-speech (TTS) and voice conversion (VC), undergo distinct stages including input processing, acoustic modeling, and waveform generation. In this work, we introduce a system designed to classify various spoofing attributes, capturing the distinctive features of individual modules throughout the entire generation pipeline. We evaluate our system on two datasets: the ASVspoof 2019 Logical Access and the Multi-Language Audio Anti-Spoofing Dataset (MLAAD). Results from both experiments demonstrate the robustness of the system to identify the different spoofing attributes of deepfake generation systems.