 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASVspoof 5: Evaluation of Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech
Jan 07, 2026ASVspoof 5 is the fifth edition in a series of challenges which promote the study of speech spoofing and deepfake detection solutions. A significant change from previous challenge editions is a new crowdsourced database collected from a substantially greater number of speakers under diverse recording conditions, and a mix of cutting-edge and legacy generative speech technology. With the new database described elsewhere, we provide in this paper an overview of the ASVspoof 5 challenge results for the submissions of 53 participating teams. While many solutions perform well, performance degrades under adversarial attacks and the application of neural encoding/compression schemes. Together with a review of post-challenge results, we also report a study of calibration in addition to other principal challenges and outline a road-map for the future of ASVspoof.
Pindrop it! Audio and Visual Deepfake Countermeasures for Robust Detection and Fine Grained-Localization
Aug 11, 2025The field of visual and audio generation is burgeoning with new state-of-the-art methods. This rapid proliferation of new techniques underscores the need for robust solutions for detecting synthetic content in videos. In particular, when fine-grained alterations via localized manipulations are performed in visual, audio, or both domains, these subtle modifications add challenges to the detection algorithms. This paper presents solutions for the problems of deepfake video classification and localization. The methods were submitted to the ACM 1M Deepfakes Detection Challenge, achieving the best performance in the temporal localization task and a top four ranking in the classification task for the TestA split of the evaluation dataset.
Open-Set Source Tracing of Audio Deepfake Systems
Jul 09, 2025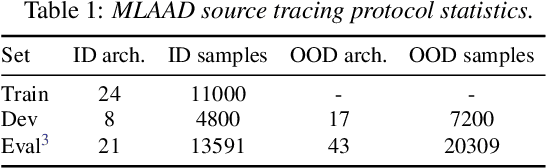
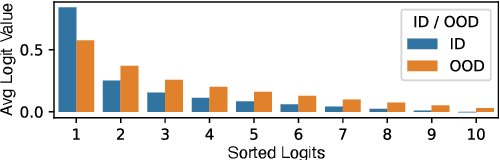
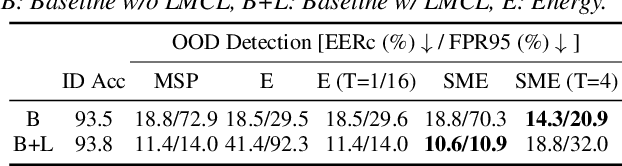
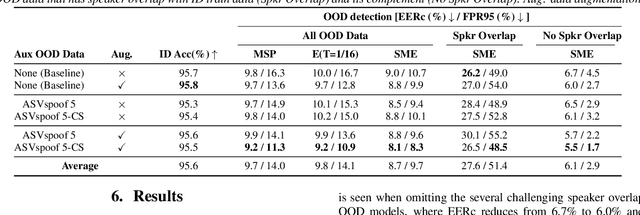
Existing research on source tracing of audio deepfake systems has focused primarily on the closed-set scenario, while studies that evaluate open-set performance are limited to a small number of unseen systems. Due to the large number of emerging audio deepfake systems, robust open-set source tracing is critical. We leverage the protocol of the Interspeech 2025 special session on source tracing to evaluate methods for improving open-set source tracing performance. We introduce a novel adaptation to the energy score for out-of-distribution (OOD) detection, softmax energy (SME). We find that replacing the typical temperature-scaled energy score with SME provides a relative average improvement of 31% in the standard FPR95 (false positive rate at true positive rate of 95%) measure. We further explore SME-guided training as well as copy synthesis, codec, and reverberation augmentations, yielding an FPR95 of 8.3%.
ASVspoof 5: Design, Collection and Validation of Resources for Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech
Feb 13, 2025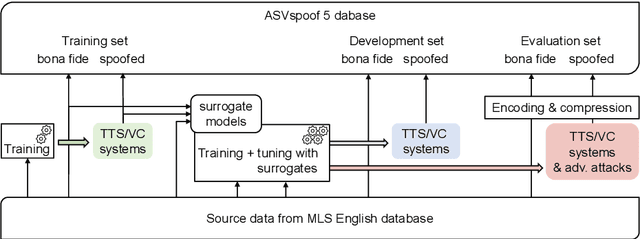

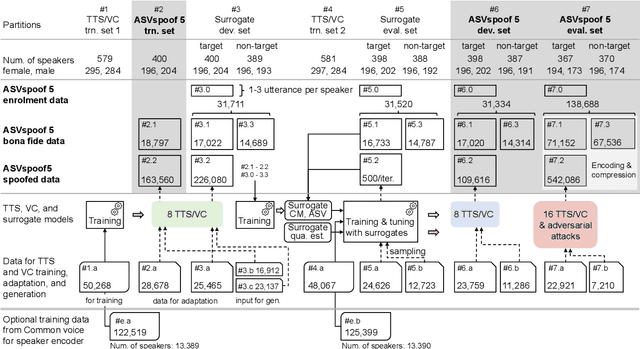
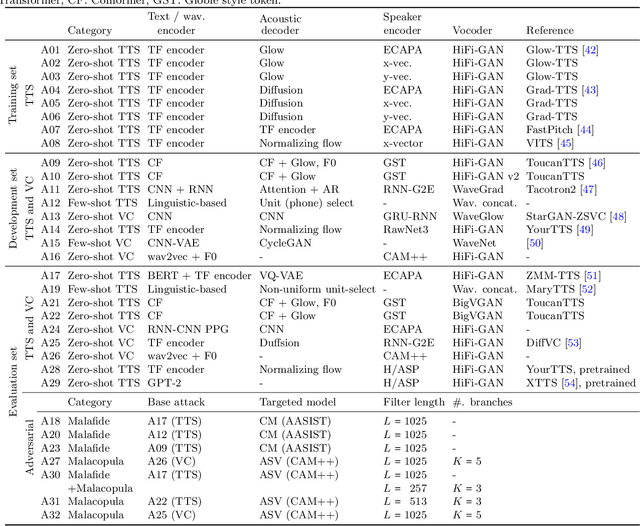
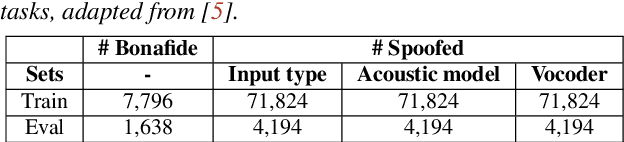
ASVspoof 5 is the fifth edition in a series of challenges which promote the study of speech spoofing and deepfake attacks as well as the design of detection solutions. We introduce the ASVspoof 5 database which is generated in crowdsourced fashion from data collected in diverse acoustic conditions (cf. studio-quality data for earlier ASVspoof databases) and from ~2,000 speakers (cf. ~100 earlier). The database contains attacks generated with 32 different algorithms, also crowdsourced, and optimised to varying degrees using new surrogate detection models. Among them are attacks generated with a mix of legacy and contemporary text-to-speech synthesis and voice conversion models, in addition to adversarial attacks which are incorporated for the first time. ASVspoof 5 protocols comprise seven speaker-disjoint partitions. They include two distinct partitions for the training of different sets of attack models, two more for the development and evaluation of surrogate detection models, and then three additional partitions which comprise the ASVspoof 5 training, development and evaluation sets. An auxiliary set of data collected from an additional 30k speakers can also be used to train speaker encoders for the implementation of attack algorithms. Also described herein is an experimental validation of the new ASVspoof 5 database using a set of automatic speaker verification and spoof/deepfake baseline detectors. With the exception of protocols and tools for the generation of spoofed/deepfake speech, the resources described in this paper, already used by participants of the ASVspoof 5 challenge in 2024, are now all freely available to the community.
ASVspoof 5: Crowdsourced Speech Data, Deepfakes, and Adversarial Attacks at Scale
Aug 16, 2024



ASVspoof 5 is the fifth edition in a series of challenges that promote the study of speech spoofing and deepfake attacks, and the design of detection solutions. Compared to previous challenges, the ASVspoof 5 database is built from crowdsourced data collected from a vastly greater number of speakers in diverse acoustic conditions. Attacks, also crowdsourced, are generated and tested using surrogate detection models, while adversarial attacks are incorporated for the first time. New metrics support the evaluation of spoofing-robust automatic speaker verification (SASV) as well as stand-alone detection solutions, i.e., countermeasures without ASV. We describe the two challenge tracks, the new database, the evaluation metrics, baselines, and the evaluation platform, and present a summary of the results. Attacks significantly compromise the baseline systems, while submissions bring substantial improvements.
Source Tracing of Audio Deepfake Systems
Jul 10, 2024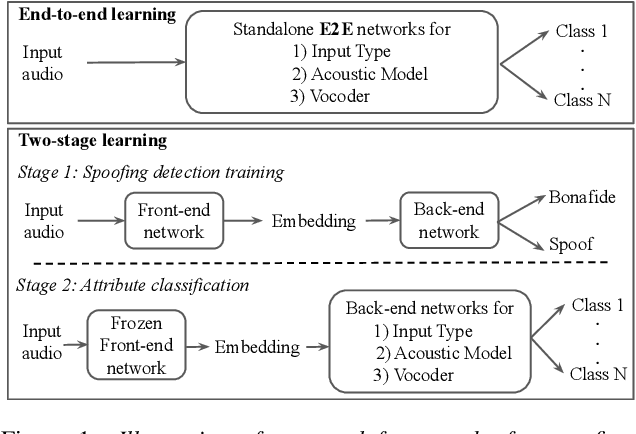

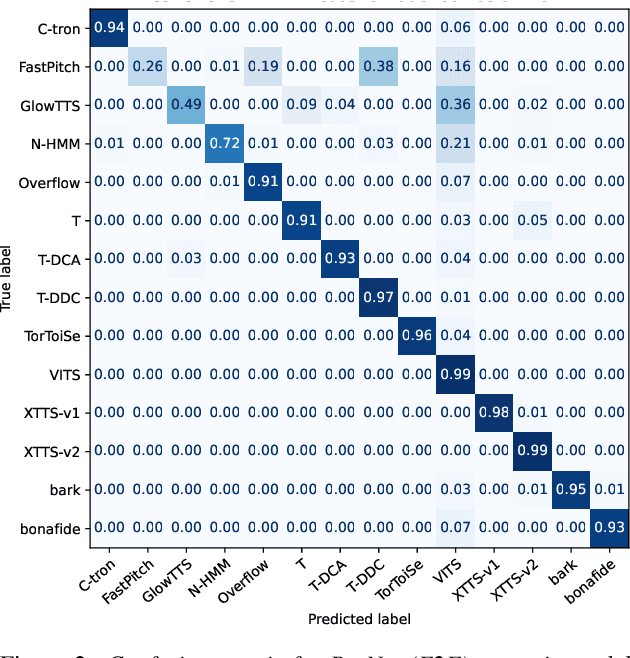
Recent progress in generative AI technology has made audio deepfakes remarkably more realistic. While current research on anti-spoofing systems primarily focuses on assessing whether a given audio sample is fake or genuine, there has been limited attention on discerning the specific techniques to create the audio deepfakes. Algorithms commonly used in audio deepfake generation, like text-to-speech (TTS) and voice conversion (VC), undergo distinct stages including input processing, acoustic modeling, and waveform generation. In this work, we introduce a system designed to classify various spoofing attributes, capturing the distinctive features of individual modules throughout the entire generation pipeline. We evaluate our system on two datasets: the ASVspoof 2019 Logical Access and the Multi-Language Audio Anti-Spoofing Dataset (MLAAD). Results from both experiments demonstrate the robustness of the system to identify the different spoofing attributes of deepfake generation systems.
To what extent can ASV systems naturally defend against spoofing attacks?
Jun 08, 2024The current automatic speaker verification (ASV) task involves making binary decisions on two types of trials: target and non-target. However, emerging advancements in speech generation technology pose significant threats to the reliability of ASV systems. This study investigates whether ASV effortlessly acquires robustness against spoofing attacks (i.e., zero-shot capability) by systematically exploring diverse ASV systems and spoofing attacks, ranging from traditional to cutting-edge techniques. Through extensive analyses conducted on eight distinct ASV systems and 29 spoofing attack systems, we demonstrate that the evolution of ASV inherently incorporates defense mechanisms against spoofing attacks. Nevertheless, our findings also underscore that the advancement of spoofing attacks far outpaces that of ASV systems, hence necessitating further research on spoofing-robust ASV methodologies.
Harder or Different? Understanding Generalization of Audio Deepfake Detection
Jun 07, 2024Recent research has highlighted a key issue in speech deepfake detection: models trained on one set of deepfakes perform poorly on others. The question arises: is this due to the continuously improving quality of Text-to-Speech (TTS) models, i.e., are newer DeepFakes just 'harder' to detect? Or, is it because deepfakes generated with one model are fundamentally different to those generated using another model? We answer this question by decomposing the performance gap between in-domain and out-of-domain test data into 'hardness' and 'difference' components. Experiments performed using ASVspoof databases indicate that the hardness component is practically negligible, with the performance gap being attributed primarily to the difference component. This has direct implications for real-world deepfake detection, highlighting that merely increasing model capacity, the currently-dominant research trend, may not effectively address the generalization challenge.
t-EER: Parameter-Free Tandem Evaluation of Countermeasures and Biometric Comparators
Sep 21, 2023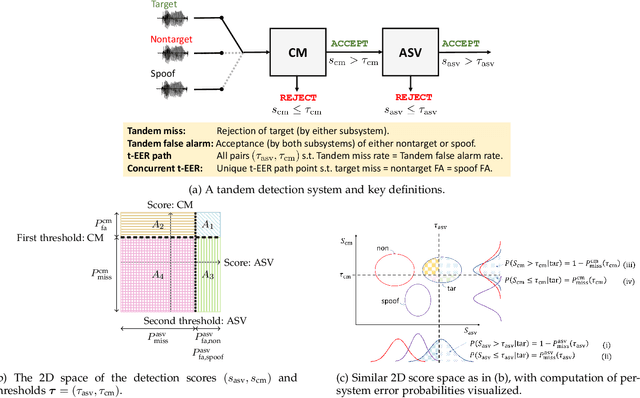

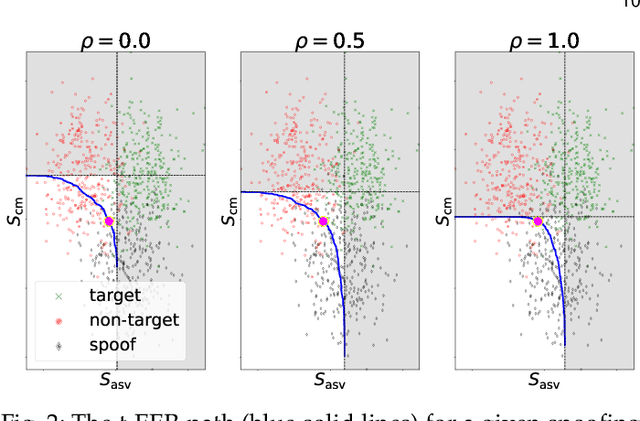

Presentation attack (spoofing) detection (PAD) typically operates alongside biometric verification to improve reliablity in the face of spoofing attacks. Even though the two sub-systems operate in tandem to solve the single task of reliable biometric verification, they address different detection tasks and are hence typically evaluated separately. Evidence shows that this approach is suboptimal. We introduce a new metric for the joint evaluation of PAD solutions operating in situ with biometric verification. In contrast to the tandem detection cost function proposed recently, the new tandem equal error rate (t-EER) is parameter free. The combination of two classifiers nonetheless leads to a \emph{set} of operating points at which false alarm and miss rates are equal and also dependent upon the prevalence of attacks. We therefore introduce the \emph{concurrent} t-EER, a unique operating point which is invariable to the prevalence of attacks. Using both modality (and even application) agnostic simulated scores, as well as real scores for a voice biometrics application, we demonstrate application of the t-EER to a wide range of biometric system evaluations under attack. The proposed approach is a strong candidate metric for the tandem evaluation of PAD systems and biometric comparators.
Malafide: a novel adversarial convolutive noise attack against deepfake and spoofing detection systems
Jun 13, 2023



We present Malafide, a universal adversarial attack against automatic speaker verification (ASV) spoofing countermeasures (CMs). By introducing convolutional noise using an optimised linear time-invariant filter, Malafide attacks can be used to compromise CM reliability while preserving other speech attributes such as quality and the speaker's voice. In contrast to other adversarial attacks proposed recently, Malafide filters are optimised independently of the input utterance and duration, are tuned instead to the underlying spoofing attack, and require the optimisation of only a small number of filter coefficients. Even so, they degrade CM performance estimates by an order of magnitude, even in black-box settings, and can also be configured to overcome integrated CM and ASV subsystems. Integrated solutions that use self-supervised learning CMs, however, are more robust, under both black-box and white-box settings.